

IEEE Spectrum IEEE Spectrum
-
The Forgotten History of Chinese Keyboards
by Thomas S. Mullaney on 28. May 2024. at 19:00
 Today, typing in Chinese works by converting QWERTY keystrokes into Chinese characters via a software interface, known as an input method editor. But this was not always the case. Thomas S. Mullaney’s new book, The Chinese Computer: A Global History of the Information Age, published by the MIT Press, unearths the forgotten history of Chinese input in the 20th century. In this article, which was adapted from an excerpt of the book, he details the varied Chinese input systems of the 1960s and ’70s that renounced QWERTY altogether.
Today, typing in Chinese works by converting QWERTY keystrokes into Chinese characters via a software interface, known as an input method editor. But this was not always the case. Thomas S. Mullaney’s new book, The Chinese Computer: A Global History of the Information Age, published by the MIT Press, unearths the forgotten history of Chinese input in the 20th century. In this article, which was adapted from an excerpt of the book, he details the varied Chinese input systems of the 1960s and ’70s that renounced QWERTY altogether.“This will destroy China forever,” a young Taiwanese cadet thought as he sat in rapt attention. The renowned historian Arnold J. Toynbee was on stage, delivering a lecture at Washington and Lee University on “A Changing World in Light of History.” The talk plowed the professor’s favorite field of inquiry: the genesis, growth, death, and disintegration of human civilizations, immortalized in his magnum opus A Study of History. Tonight’s talk threw the spotlight on China.
China was Toynbee’s outlier: Ancient as Egypt, it was a civilization that had survived the ravages of time. The secret to China’s continuity, he argued, was character-based Chinese script. Character-based script served as a unifying medium, placing guardrails against centrifugal forces that might otherwise have ripped this grand and diverse civilization apart. This millennial integrity was now under threat. Indeed, as Toynbee spoke, the government in Beijing was busily deploying Hanyu pinyin, a Latin alphabet–based Romanization system.
The Taiwanese cadet listening to Toynbee was Chan-hui Yeh, a student of electrical engineering at the nearby Virginia Military Institute (VMI). That evening with Arnold Toynbee forever altered the trajectory of his life. It changed the trajectory of Chinese computing as well, triggering a cascade of events that later led to the formation of arguably the first successful Chinese IT company in history: Ideographix, founded by Yeh 14 years after Toynbee stepped offstage.
During the late 1960s and early 1970s, Chinese computing underwent multiple sea changes. No longer limited to small-scale laboratories and solo inventors, the challenge of Chinese computing was taken up by engineers, linguists, and entrepreneurs across Asia, the United States, and Europe—including Yeh’s adoptive home of Silicon Valley.
 Chan-hui Yeh’s IPX keyboard featured 160 main keys, with 15 characters each. A peripheral keyboard of 15 keys was used to select the character on each key. Separate “shift” keys were used to change all of the character assignments of the 160 keys. Computer History Museum
Chan-hui Yeh’s IPX keyboard featured 160 main keys, with 15 characters each. A peripheral keyboard of 15 keys was used to select the character on each key. Separate “shift” keys were used to change all of the character assignments of the 160 keys. Computer History MuseumThe design of Chinese computers also changed dramatically. None of the competing designs that emerged in this era employed a QWERTY-style keyboard. Instead, one of the most successful and celebrated systems—the IPX, designed by Yeh—featured an interface with 120 levels of “shift,” packing nearly 20,000 Chinese characters and other symbols into a space only slightly larger than a QWERTY interface. Other systems featured keyboards with anywhere from 256 to 2,000 keys. Still others dispensed with keyboards altogether, employing a stylus and touch-sensitive tablet, or a grid of Chinese characters wrapped around a rotating cylindrical interface. It’s as if every kind of interface imaginable was being explored except QWERTY-style keyboards.
IPX: Yeh’s 120-dimensional hypershift Chinese keyboard
Yeh graduated from VMI in 1960 with a B.S. in electrical engineering. He went on to Cornell University, receiving his M.S. in nuclear engineering in 1963 and his Ph.D. in electrical engineering in 1965. Yeh then joined IBM, not to develop Chinese text technologies but to draw upon his background in automatic control to help develop computational simulations for large-scale manufacturing plants, like paper mills, petrochemical refineries, steel mills, and sugar mills. He was stationed in IBM’s relatively new offices in San Jose, Calif.
Toynbee’s lecture stuck with Yeh, though. While working at IBM, he spent his spare time exploring the electronic processing of Chinese characters. He felt convinced that the digitization of Chinese must be possible, that Chinese writing could be brought into the computational age. Doing so, he felt, would safeguard Chinese script against those like Chairman Mao Zedong, who seemed to equate Chinese modernization with the Romanization of Chinese script. The belief was so powerful that Yeh eventually quit his good-paying job at IBM to try and save Chinese through the power of computing.
Yeh started with the most complex parts of the Chinese lexicon and worked back from there. He fixated on one character in particular: ying 鷹 (“eagle”), an elaborate graph that requires 24 brushstrokes to compose. If he could determine an appropriate data structure for such a complex character, he reasoned, he would be well on his way. Through careful analysis, he determined that a bitmap comprising 24 vertical dots and 20 horizontal dots would do the trick, taking up 60 bytes of memory, excluding metadata. By 1968, Yeh felt confident enough to take the next big step—to patent his project, nicknamed “Iron Eagle.” The Iron Eagle project quickly garnered the interest of the Taiwanese military. Four years later, with the promise of Taiwanese government funding, Yeh founded Ideographix, in Sunnyvale, Calif.
 A single key of the IPX keyboard contained 15 characters. This key contains the character zhong (中 “central”), which is necessary to spell “China.” MIT Press
A single key of the IPX keyboard contained 15 characters. This key contains the character zhong (中 “central”), which is necessary to spell “China.” MIT PressThe flagship product of Ideographix was the IPX, a computational typesetting and transmission system for Chinese built upon the complex orchestration of multiple subsystems.
The marvel of the IPX system was the keyboard subsystem, which enabled operators to enter a theoretical maximum of 19,200 Chinese characters despite its modest size: 59 centimeters wide, 37 cm deep, and 11 cm tall. To achieve this remarkable feat, Yeh and his colleagues decided to treat the keyboard not merely as an electronic peripheral but as a full-fledged computer unto itself: a microprocessor-controlled “intelligent terminal” completely unlike conventional QWERTY-style devices.
Seated in front of the IPX interface, the operator looked down on 160 keys arranged in a 16-by-10 grid. Each key contained not a single Chinese character but a cluster of 15 characters arranged in a miniature 3-by-5 array. Those 160 keys with 15 characters on each key yielded 2,400 Chinese characters.
 The process of typing on the IPX keyboard involved using a booklet of characters used to depress one of 160 keys, selecting one of 15 numbers to pick a character within the key, and using separate “shift” keys to indicate when a page of the booklet was flipped. MIT Press
The process of typing on the IPX keyboard involved using a booklet of characters used to depress one of 160 keys, selecting one of 15 numbers to pick a character within the key, and using separate “shift” keys to indicate when a page of the booklet was flipped. MIT PressChinese characters were not printed on the keys, the way that letters and numbers are emblazoned on the keys of QWERTY devices. The 160 keys themselves were blank. Instead, the 2,400 Chinese characters were printed on laminated paper, bound together in a spiral-bound booklet that the operator laid down flat atop the IPX interface.The IPX keys weren’t buttons, as on a QWERTY device, but pressure-sensitive pads. An operator would push down on the spiral-bound booklet to depress whichever key pad was directly underneath.
To reach characters 2,401 through 19,200, the operator simply turned the spiral-bound booklet to whichever page contained the desired character. The booklets contained up to eight pages—and each page contained 2,400 characters—so the total number of potential symbols came to just shy of 20,000.
For the first seven years of its existence, the use of IPX was limited to the Taiwanese military. As years passed, the exclusivity relaxed, and Yeh began to seek out customers in both the private and public sectors. Yeh’s first major nonmilitary clients included Taiwan’s telecommunication administration and the National Taxation Bureau of Taipei. For the former, the IPX helped process and transmit millions of phone bills. For the latter, it enabled the production of tax return documents at unprecedented speed and scale. But the IPX wasn’t the only game in town.
 Loh Shiu-chang, a professor at the Chinese University of Hong Kong, developed what he called “Loh’s keyboard” (Le shi jianpan 樂氏鍵盤), featuring 256 keys. Loh Shiu-chang
Loh Shiu-chang, a professor at the Chinese University of Hong Kong, developed what he called “Loh’s keyboard” (Le shi jianpan 樂氏鍵盤), featuring 256 keys. Loh Shiu-changMainland China’s “medium-sized” keyboards
By the mid-1970s, the People’s Republic of China was far more advanced in the arena of mainframe computing than most outsiders realized. In July 1972, just months after the famed tour by U.S. president Richard Nixon, a veritable blue-ribbon committee of prominent American computer scientists visited the PRC. The delegation visited China’s main centers of computer science at the time, and upon learning what their counterparts had been up to during the many years of Sino-American estrangement, the delegation was stunned.
But there was one key arena of computing that the delegation did not bear witness to: the computational processing of Chinese characters. It was not until October 1974 that mainland Chinese engineers began to dive seriously into this problem. Soon after, in 1975, the newly formed Chinese Character Information Processing Technology Research Office at Peking University set out upon the goal of creating a “Chinese Character Information Processing and Input System” and a “Chinese Character Keyboard.”
The group evaluated more than 10 proposals for Chinese keyboard designs. The designs fell into three general categories: a large-keyboard approach, with one key for every commonly used character; a small-keyboard approach, like the QWERTY-style keyboard; and a medium-size keyboard approach, which attempted to tread a path between these two poles.
 Peking University’s medium-sized keyboard design included a combination of Chinese characters and character components, as shown in this explanatory diagram. Public Domain
Peking University’s medium-sized keyboard design included a combination of Chinese characters and character components, as shown in this explanatory diagram. Public DomainThe team leveled two major criticisms against QWERTY-style small keyboards. First, there were just too few keys, which meant that many Chinese characters were assigned identical input sequences. What’s more, QWERTY keyboards did a poor job of using keys to their full potential. For the most part, each key on a QWERTY keyboard was assigned only two symbols, one of which required the operator to depress and hold the shift key to access. A better approach, they argued, was the technique of “one key, many uses”— yijian duoyong—assigning each key a larger number of symbols to make the most use of interface real estate.
The team also examined the large-keyboard approach, in which 2,000 or more commonly used Chinese characters were assigned to a tabletop-size interface. Several teams across China worked on various versions of these large keyboards. The Peking team, however, regarded the large-keyboard approach as excessive and unwieldy. Their goal was to exploit each key to its maximum potential, while keeping the number of keys to a minimum.
After years of work, the team in Beijing settled upon a keyboard with 256 keys, 29 of which would be dedicated to various functions, such as carriage return and spacing, and the remaining 227 used to input text. Each keystroke generated an 8-bit code, stored on punched paper tape (hence the choice of 256, or 28, keys). These 8-bit codes were then translated into a 14-bit internal code, which the computer used to retrieve the desired character.
In their assignment of multiple characters to individual keys, the team’s design was reminiscent of Ideographix’s IPX machine. But there was a twist. Instead of assigning only full-bodied, stand-alone Chinese characters to each key, the team assigned a mixture of both Chinese characters and character components. Specifically, each key was associated with up to four symbols, divided among three varieties:
- full-body Chinese characters (limited to no more than two per key)
- partial Chinese character components (no more than three per key)
- the uppercase symbol, reserved for switching to other languages (limited to one per key)
In all, the keyboard contained 423 full-body Chinese characters and 264 character components. When arranging these 264 character components on the keyboard, the team hit upon an elegant and ingenious way to help operators remember the location of each: They treated the keyboard as if it were a Chinese character itself. The team placed each of the 264 character components in the regions of the keyboard that corresponded to the areas where they usually appeared in Chinese characters.
In its final design, the Peking University keyboard was capable of inputting a total of 7,282 Chinese characters, which in the team’s estimation would account for more than 90 percent of all characters encountered on an average day. Within this character set, the 423 most common characters could be produced via one keystroke; 2,930 characters could be produced using two keystrokes; and a further 3,106 characters could be produced using three keystrokes. The remaining 823 characters required four or five keystrokes.
The Peking University keyboard was just one of many medium-size designs of the era. IBM created its own 256-key keyboard for Chinese and Japanese. In a design reminiscent of the IPX system, this 1970s-era keyboard included a 12-digit keypad with which the operator could “shift” between the 12 full-body Chinese characters outfitted on each key (for a total of 3,072 characters in all). In 1980, Chinese University of Hong Kong professor Loh Shiu-chang developed what he called “Loh’s keyboard” (Le shi jianpan 樂氏鍵盤), which also featured 256 keys.
But perhaps the strangest Chinese keyboard of the era was designed in England.
The cylindrical Chinese keyboard
On a winter day in 1976, a young boy in Cambridge, England, searched for his beloved Meccano set. A predecessor of the American Erector set, the popular British toy offered aspiring engineers hours of modular possibility. Andrew had played with the gears, axles, and metal plates recently, but today they were nowhere to be found.
Wandering into the kitchen, he caught the thief red-handed: his father, the Cambridge University researcher Robert Sloss. For three straight days and nights, Sloss had commandeered his son’s toy, engrossed in the creation of a peculiar gadget that was cylindrical and rotating. It riveted the young boy’s attention—and then the attention of the Telegraph-Herald, which dispatched a journalist to see it firsthand. Ultimately, it attracted the attention and financial backing of the U.K. telecommunications giant Cable & Wireless.
Robert Sloss was building a Chinese computer.
The elder Sloss was born in 1927 in Scotland. He joined the British navy, and was subjected to a series of intelligence tests that revealed a proclivity for foreign languages. In 1946 and 1947, he was stationed in Hong Kong. Sloss went on to join the civil service as a teacher and later, in the British air force, became a noncommissioned officer. Owing to his pedagogical experience, his knack for language, and his background in Asia, he was invited to teach Chinese at Cambridge and appointed to a lectureship in 1972.
At Cambridge, Sloss met Peter Nancarrow. Twelve years Sloss’s junior, Nancarrow trained as a physicist but later found work as a patent agent. The bearded 38-year-old then taught himself Norwegian and Russian as a “hobby” before joining forces with Sloss in a quest to build an automatic Chinese-English translation machine.
 In 1976, Robert Sloss and Peter Nancarrow designed the Ideo-Matic Encoder, a Chinese input keyboard with a grid of 4,356 keys wrapped around a cylinder. PK Porthcurno
In 1976, Robert Sloss and Peter Nancarrow designed the Ideo-Matic Encoder, a Chinese input keyboard with a grid of 4,356 keys wrapped around a cylinder. PK PorthcurnoThey quickly found that the choke point in their translator design was character input— namely, how to get handwritten Chinese characters, definitions, and syntax data into a computer.
Over the following two years, Sloss and Nancarrow dedicated their energy to designing a Chinese computer interface. It was this effort that led Sloss to steal and tinker with his son’s Meccano set. Sloss’s tinkering soon bore fruit: a working prototype that the duo called the “Binary Signal Generator for Encoding Chinese Characters into Machine-compatible form”—also known as the Ideo-Matic Encoder and the Ideo-Matic 66 (named after the machine’s 66-by-66 grid of characters).
Each cell in the machine’s grid was assigned a binary code corresponding to the X-column and the Y-row values. In terms of total space, each cell was 7 millimeters squared, with 3,500 of the 4,356 cells dedicated to Chinese characters. The rest were assigned to Japanese syllables or left blank.
The distinguishing feature of Sloss and Nancarrow’s interface was not the grid, however. Rather than arranging their 4,356 cells across a rectangular interface, the pair decided to wrap the grid around a rotating, tubular structure. The typist used one hand to rotate the cylindrical grid and the other hand to move a cursor left and right to indicate one of the 4,356 cells. The depression of a button produced a binary signal that corresponded to the selected Chinese character or other symbol.
The Ideo-Matic Encoder was completed and delivered to Cable & Wireless in the closing years of the 1970s. Weighing in at 7 kilograms and measuring 68 cm wide, 57 cm deep, and 23 cm tall, the machine garnered industry and media attention. Cable & Wireless purchased rights to the machine in hopes of mass-manufacturing it for the East Asian market.
QWERTY’s comeback
The IPX, the Ideo-Matic 66, Peking University’s medium-size keyboards, and indeed all of the other custom-built devices discussed here would soon meet exactly the same fate—oblivion. There were changes afoot. The era of custom-designed Chinese text-processing systems was coming to an end. A new era was taking shape, one that major corporations, entrepreneurs, and inventors were largely unprepared for. This new age has come to be known by many names: the software revolution, the personal-computing revolution, and less rosily, the death of hardware.
From the late 1970s onward, custom-built Chinese interfaces steadily disappeared from marketplaces and laboratories alike, displaced by wave upon wave of Western-built personal computers crashing on the shores of the PRC. With those computers came the resurgence of QWERTY for Chinese input, along the same lines as the systems used by Sinophone computer users today—ones mediated by a software layer to transform the Latin alphabet into Chinese characters. This switch to typing mediated by an input method editor, or IME, did not lead to the downfall of Chinese civilization, as the historian Arnold Toynbee may have predicted. However, it did fundamentally change the way Chinese speakers interact with the digital world and their own language.
This article appears in the June 2024 print issue.
-
Physics Nobel Laureate Herbert Kroemer Dies at 95
by Amanda Davis on 28. May 2024. at 18:00

Herbert Kroemer
Nobel Laureate
Life Fellow, 95; died 8 March
Kroemer, a pioneering physicist, is a Nobel laureate, receiving the 2000 Nobel Prize in Physics for developing semiconductor heterostructures for high-speed and opto-electronics. The devices laid the foundation for the modern era of microchips, computers, and information technology. Heterostructures describe the interfaces between two semiconductors that serve as the building blocks between more elaborate nanostructures.
He also received the 2002 IEEE Medal of Honor for “contributions to high-frequency transistors and hot-electron devices, especially heterostructure devices from heterostructure bipolar transistors to lasers, and their molecular beam epitaxy technology.”
Kroemer was professor emeritus of electrical and computer engineering at the University of California, Santa Barbara, when he died.
He began his career in 1952 at the telecommunications research laboratory of the German Postal Service, in Darmstadt. The postal service also ran the telephone system and had a small semiconductor research group, which included Kroemer and about nine other scientists, according to IEEE Spectrum.
In the mid-1950s, he took a research position at RCA Laboratories, in Princeton, N.J. There, Kroemer originated the concept of the heterostructure bipolar transistor (HBT), a device that contains differing semiconductor materials for the emitter and base regions, creating a heterojunction. HBTs can handle high-frequency signals (up to several thousand gigahertz) and are commonly used in radio frequency systems, including RF power amplifiers in cell phones.
In 1957, he returned to Germany to research potential uses of gallium arsenide at Phillips Research Laboratory, in Hamburg. Two years later, Kroemer moved back to the United States to join Varian Associates, an electronics company in Palo Alto, Calif., where he invented the double heterostructure laser. It was the first laser to operate continuously at room temperature. The innovation paved the way for semiconductor lasers used in CD players, fiber optics, and other applications.
In 1964, Kroemer became the first researcher to publish an explanation of the Gunn Effect, a high-frequency oscillation of electrical current flowing through certain semiconducting solids. The effect, first observed by J.B. Gunn in the early 1960s, produces short radio waves called microwaves.
Kroemer taught electrical engineering at the University of Colorado, Boulder, from 1968 to 1976 before joining UCSB, where he led the university’s semiconductor research program. With his colleague Charles Kittel, Kroemer co-authored the 1980 textbook Thermal Physics. He also wrote Quantum Mechanics for Engineering, Materials Science, and Applied Physics, published in 1994.
He was a Fellow of the American Physics Society and a foreign associate of the U.S. National Academy of Engineering.
Born and educated in Germany, Kroemer received a bachelor’s degree from the University of Jena, and master’s and doctoral degrees from the University of Göttingen, all in physics.
Vladimir G. “Walt” Gelnovatch
Past president of the IEEE Microwave Theory and Technology Society
Life Fellow, 86; died 1 March
Gelnovatch served as 1989 president of the IEEE Microwave Theory and Technology Society (formerly the IEEE Microwave Theory and Techniques Society). He was an electrical engineer for nearly 40 years at the Signal Corps Laboratories, in Fort Monmouth, N.J.
Gelnovatch served in the U.S. Army from 1956 to 1959. While stationed in Germany, he helped develop a long-line microwave radiotelephone network, a military telecommunications network that spanned most of Western Europe.
As an undergraduate student at Monmouth University, in West Long Branch, N.J., he founded the school’s first student chapter of the Institute of Radio Engineers, an IEEE predecessor society. After graduating with a bachelor’s degree in electronics engineering, Gelnovatch earned a master’s degree in electrical engineering in 1967 from New York University, in New York City.
Following a brief stint as a professor of electrical engineering at the University of Virginia, in Charlottesville, Gelnovatch joined the Signal Corps Engineering Laboratory (SCEL) as a research engineer. His initial work focused on developing CAD programs to help researchers design microwave circuits and communications networks. He then shifted his focus to developing mission electronics. Over the next four years, he studied vacuum technology, germanium, silicon, and semiconductors.
He also spearheaded the U.S. Army’s research on monolithic microwave-integrated circuits. The integrated circuit devices operate at microwave frequencies and typically perform functions such as power amplification, low-noise amplification, and high-frequency switching.
Gelnovatch retired in 1997 as director of the U.S. Army Electron Devices and Technology Laboratory, the successor to SCEL.
During his career, Gelnovatch published 50 research papers and was granted eight U.S. patents. He also served as associate editor and contributor to the Microwave Journal for more than 20 years.
Gelnovatch received the 1997 IEEE MTT-S Distinguished Service Award. The U.S. Army also honored him in 1990 with its highest civilian award—the Exceptional Service Award.
Adolf Goetzberger
Solar energy pioneer
Life Fellow, 94; died 24 February
Goetzberger founded the Fraunhofer Institute for Solar Energy Systems (ISE), a solar energy R&D company in Freiburg, Germany. He is known for pioneering the concept of agrivoltaics—the dual use of land for solar energy production and agriculture.
After earning a Ph.D. in physics in 1955 from the University of Munich, Goetzberger moved to the United States. He joined Shockley Semiconductor Laboratory in Palo Alto, Calif., in 1956 as a researcher. The semiconductor manufacturer was founded by Nobel laureate William Shockley. Goetzberger later left Shockley to join Bell Labs, in Murray Hill, N.J.
He moved back to Germany in 1968 and was appointed director of the Fraunhofer Institute for Applied Solid-State Physics, in Breisgau. There, he founded a solar energy working group and pushed for an independent institute dedicated to the field, which became ISE in 1981.
In 1983, Goetzberger became the first German national to receive the J.J. Ebers Award from the IEEE Electron Devices Society. It honored him for developing a silicon field-effect transistor. Goetzberger also received the 1997 IEEE William R. Cherry Award, the 1989 Medal of the Merit of the State of Baden-Württemberg, and the 1992 Order of Merit First Class of the Federal Republic of Germany.
Michael Barnoski
Fiber optics pioneer
Life senior member, 83; died 23 February
Barnoski founded two optics companies and codeveloped the optical time domain reflectometer, a device that detects breaks in fiber optic cables.
After receiving a bachelor’s degree in electrical engineering from the University of Dayton, in Ohio, Barnoski joined Honeywell in Boston. After 10 years at the company, he left to work at Hughes Research Laboratories, in Malibu, Calif. For a decade, he led all fiber optics–related activities for Hughes Aircraft and managed a global team of scientists, engineers, and technicians.
In 1976, Barnoski collaborated with Corning Glass Works, a materials science company in New York, to develop the optical time domain reflectometer.
Three years later, Theodore Mainman, inventor of the laser, recruited Barnoski to join TRW, an electronics company in Euclid, Ohio. In 1980, Barnoski founded PlessCor Optronics laboratory, an integrated electrical-optical interface supplier, in Chatsworth, Calif. He served as president and CEO until 1990, when he left and began consulting.
In 2002, Barnoski founded Nanoprecision Products Inc., a company that specialized in ultraprecision 3D stamping, in El Segundo, Calif.
In addition to his work in the private sector, Barnoski taught summer courses at the University of California, Santa Barbara, for 20 years. He also wrote and edited three books on the fundamentals of optical fiber communications. He retired in 2018.
For his contributions to fiber optics, he received the 1988 John Tyndall Award, jointly presented by the IEEE Photonics Society and the Optical Society of America.
Barnoski also earned a master’s degree in microwave electronics and a Ph.D. in electrical engineering and applied physics, both from Cornell.
Kanaiyalal R. Shah
Founder of Shah and Associates
Senior member, 84; died 6 December
Shah was founder and president of Shah and Associates (S&A), an electrical systems consulting firm, in Gaithersburg, Md.
Shah received a bachelor’s degree in electrical engineering in 1961 from the Baroda College (now the Maharaja Sayajirao University of Baroda), in India. After earning a master’s degree in electrical machines in 1963 from Gujarat University, in India, Shah emigrated to the United States. Two years later, he received a master’s degree in electrical engineering from the University of Missouri in Rolla.
In 1967, he moved to Virginia and joined the Virginia Military Institute’s electrical engineering faculty, in Lexington. He left to move to Missouri, earning a Ph.D. in EE from the University of Missouri in Columbia, in 1969. He then moved back to Virginia and taught electrical engineering for two years at Virginia Tech.
From 1971 to 1973, Shah worked as a research engineer at Hughes Research Laboratories, in Malibu, Calif. He left to manage R&D at engineering services company Gilbert/Commonwealth International, in Jackson, Mich.
Around this time, Shah founded S&A, where he designed safe and efficient electrical systems. He developed novel approaches to ensuring safety in electrical power transmission and distribution, including patenting a UV lighting power system. He also served as an expert witness in electrical safety injury lawsuits.
He later returned to academia, lecturing at George Washington University and Ohio State University. Shah also wrote a series of short courses on power engineering. In 2005, he funded the construction and running of the Dr. K.R. Shah Higher Secondary School and the Smt. D.K. Shah Primary School in his hometown of Bhaner, Gujarat, in India.
John Brooks Slaughter
First African American director of the National Science Foundation
Life Fellow, 89; died 6 December
Slaughter, former director of the NSF in the early 1980s, was a passionate advocate for providing opportunities for underrepresented minorities and women in the science, technology, engineering, and mathematics fields.
Later in his career, he was a distinguished professor of engineering and education at the University of Southern California Viterbi School of Engineering, in Los Angeles. He helped found the school’s Center for Engineering Diversity, which was renamed the John Brooks Slaughter Center for Engineering Diversity in 2023, as a tribute to his efforts.
After earning a bachelor’s degree in engineering in 1956 from Kansas State University, in Manhattan, Slaughter developed military aircraft at General Dynamics’ Convair division in San Diego. From there, he moved on to the information systems technology department in the U.S. Navy Electronics Laboratory, also located in the city. He earned a master’s degree in engineering in 1961 from the University of California, Los Angeles.
Slaughter earned his Ph.D. from the University of California, San Diego, in 1971 and was promoted to director of the Navy Electronics Laboratory on the same day he defended his dissertation, according to The Institute.
In 1975, he left the organization to become director of the Applied Physics Laboratory at the University of Washington, in Seattle. Two years later, Slaughter was appointed assistant director in charge of the NSF’s Astronomical, Atmospheric, Earth and Ocean Sciences Division (now called the Division of Atmospheric and Geospace Sciences), in Washington, D.C.
In 1979, he accepted the position of academic vice president and provost of Washington State University, in Pullman. The following year, he was appointed director of the NSF by U.S. President Jimmy Carter’s administration. Under Slaughter’s leadership, the organization bolstered funding for science programs at historically Black colleges and universities, including Howard University, in Washington, D.C. While Harvard, Stanford, and CalTech traditionally received preference from the NSF for funding new facilities and equipment, Slaughter encouraged less prestigious universities to apply and compete for those grants.
He resigned just two years after accepting the post because he could not publicly support President Ronald Reagan’s initiatives to eradicate funding for science education, he told The Institute in a 2023 interview.
In 1981, Slaughter was appointed chancellor of the University of Maryland, in College Park. He left in 1988 to become president of Occidental College, in Los Angeles, where he helped transform the school into one of the country’s most diverse liberal arts colleges.
In 2000, Slaughter became CEO and president of the National Action Council for Minorities in Engineering, the largest provider of college scholarships for underrepresented minorities pursuing degrees at engineering schools, in Alexandria, Va.
Slaughter left the council in 2010 and joined USC. He taught courses on leadership, diversity, and technological literacy at Rossier Graduate School of Education until retiring in 2022.
Slaughter received the 2002 IEEE Founders Medal for “leadership and administration significantly advancing inclusion and racial diversity in the engineering profession across government, academic, and nonprofit organizations.”
Don Bramlett
Former IEEE Region 4 Director
Life senior member, 73; died 2 December
Bramlett served as 2009–2010 director of IEEE Region 4. He was an active volunteer with the IEEE Southeastern Michigan Section.
He worked as a senior project manager for 35 years at DTE Energy, an energy services company, in Detroit.
Bramlett was also active in the Boy Scouts of America (which will be known as Scouting America beginning in 2025). He served as leader of his local troop and was a council member. The Boy Scouts honored him with a Silver Beaver award recognizing his “exceptional character and distinguished service.”
Bramlett earned a bachelor’s degree in electrical engineering from the University of Detroit Mercy.
-
Will Scaling Solve Robotics?
by Nishanth J. Kumar on 28. May 2024. at 10:00

This post was originally published on the author’s personal blog.
Last year’s Conference on Robot Learning (CoRL) was the biggest CoRL yet, with over 900 attendees, 11 workshops, and almost 200 accepted papers. While there were a lot of cool new ideas (see this great set of notes for an overview of technical content), one particular debate seemed to be front and center: Is training a large neural network on a very large dataset a feasible way to solve robotics?1
Of course, some version of this question has been on researchers’ minds for a few years now. However, in the aftermath of the unprecedented success of ChatGPT and other large-scale “foundation models” on tasks that were thought to be unsolvable just a few years ago, the question was especially topical at this year’s CoRL. Developing a general-purpose robot, one that can competently and robustly execute a wide variety of tasks of interest in any home or office environment that humans can, has been perhaps the holy grail of robotics since the inception of the field. And given the recent progress of foundation models, it seems possible that scaling existing network architectures by training them on very large datasets might actually be the key to that grail.
Given how timely and significant this debate seems to be, I thought it might be useful to write a post centered around it. My main goal here is to try to present the different sides of the argument as I heard them, without bias towards any side. Almost all the content is taken directly from talks I attended or conversations I had with fellow attendees. My hope is that this serves to deepen people’s understanding around the debate, and maybe even inspire future research ideas and directions.
I want to start by presenting the main arguments I heard in favor of scaling as a solution to robotics.
Why Scaling Might Work
- It worked for Computer Vision (CV) and Natural Language Processing (NLP), so why not robotics? This was perhaps the most common argument I heard, and the one that seemed to excite most people given recent models like GPT4-V and SAM. The point here is that training a large model on an extremely large corpus of data has recently led to astounding progress on problems thought to be intractable just 3-4 years ago. Moreover, doing this has led to a number of emergent capabilities, where trained models are able to perform well at a number of tasks they weren’t explicitly trained for. Importantly, the fundamental method here of training a large model on a very large amount of data is general and not somehow unique to CV or NLP. Thus, there seems to be no reason why we shouldn’t observe the same incredible performance on robotics tasks.
- We’re already starting to see some evidence that this might work well: Chelsea Finn, Vincent Vanhoucke, and several others pointed to the recent RT-X and RT-2 papers from Google DeepMind as evidence that training a single model on large amounts of robotics data yields promising generalization capabilities. Russ Tedrake of Toyota Research Institute (TRI) and MIT pointed to the recent Diffusion Policies paper as showing a similar surprising capability. Sergey Levine of UC Berkeley highlighted recent efforts and successes from his group in building and deploying a robot-agnostic foundation model for navigation. All of these works are somewhat preliminary in that they train a relatively small model with a paltry amount of data compared to something like GPT4-V, but they certainly do seem to point to the fact that scaling up these models and datasets could yield impressive results in robotics.
- Progress in data, compute, and foundation models are waves that we should ride: This argument is closely related to the above one, but distinct enough that I think it deserves to be discussed separately. The main idea here comes from Rich Sutton’s influential essay: The history of AI research has shown that relatively simple algorithms that scale well with data always outperform more complex/clever algorithms that do not. A nice analogy from Karol Hausman’s early career keynote is that improvements to data and compute are like a wave that is bound to happen given the progress and adoption of technology. Whether we like it or not, there will be more data and better compute. As AI researchers, we can either choose to ride this wave, or we can ignore it. Riding this wave means recognizing all the progress that’s happened because of large data and large models, and then developing algorithms, tools, datasets, etc. to take advantage of this progress. It also means leveraging large pre-trained models from vision and language that currently exist or will exist for robotics tasks.
- Robotics tasks of interest lie on a relatively simple manifold, and training a large model will help us find it: This was something rather interesting that Russ Tedrake pointed out during a debate in the workshop on robustly deploying learning-based solutions. The manifold hypothesis as applied to robotics roughly states that, while the space of possible tasks we could conceive of having a robot do is impossibly large and complex, the tasks that actually occur practically in our world lie on some much lower-dimensional and simpler manifold of this space. By training a single model on large amounts of data, we might be able to discover this manifold. If we believe that such a manifold exists for robotics — which certainly seems intuitive — then this line of thinking would suggest that robotics is not somehow different from CV or NLP in any fundamental way. The same recipe that worked for CV and NLP should be able to discover the manifold for robotics and yield a shockingly competent generalist robot. Even if this doesn’t exactly happen, Tedrake points out that attempting to train a large model for general robotics tasks could teach us important things about the manifold of robotics tasks, and perhaps we can leverage this understanding to solve robotics.
- Large models are the best approach we have to get at “common sense” capabilities, which pervade all of robotics: Another thing Russ Tedrake pointed out is that “common sense” pervades almost every robotics task of interest. Consider the task of having a mobile manipulation robot place a mug onto a table. Even if we ignore the challenging problems of finding and localizing the mug, there are a surprising number of subtleties to this problem. What if the table is cluttered and the robot has to move other objects out of the way? What if the mug accidentally falls on the floor and the robot has to pick it up again, re-orient it, and place it on the table? And what if the mug has something in it, so it’s important it’s never overturned? These “edge cases” are actually much more common that it might seem, and often are the difference between success and failure for a task. Moreover, these seem to require some sort of ‘common sense’ reasoning to deal with. Several people argued that large models trained on a large amount of data are the best way we know of to yield some aspects of this ‘common sense’ capability. Thus, they might be the best way we know of to solve general robotics tasks.
As you might imagine, there were a number of arguments against scaling as a practical solution to robotics. Interestingly, almost no one directly disputes that this approach could work in theory. Instead, most arguments fall into one of two buckets: (1) arguing that this approach is simply impractical, and (2) arguing that even if it does kind of work, it won’t really “solve” robotics.
Why Scaling Might Not Work
It’s impractical
- We currently just don’t have much robotics data, and there’s no clear way we’ll get it: This is the elephant in pretty much every large-scale robot learning room. The Internet is chock-full of data for CV and NLP, but not at all for robotics. Recent efforts to collect very large datasets have required tremendous amounts of time, money, and cooperation, yet have yielded a very small fraction of the amount of vision and text data on the Internet. CV and NLP got so much data because they had an incredible “data flywheel”: tens of millions of people connecting to and using the Internet. Unfortunately for robotics, there seems to be no reason why people would upload a bunch of sensory input and corresponding action pairs. Collecting a very large robotics dataset seems quite hard, and given that we know that a lot of important “emergent” properties only showed up in vision and language models at scale, the inability to get a large dataset could render this scaling approach hopeless.
- Robots have different embodiments: Another challenge with collecting a very large robotics dataset is that robots come in a large variety of different shapes, sizes, and form factors. The output control actions that are sent to a Boston Dynamics Spot robot are very different to those sent to a KUKA iiwa arm. Even if we ignore the problem of finding some kind of common output space for a large trained model, the variety in robot embodiments means we’ll probably have to collect data from each robot type, and that makes the above data-collection problem even harder.
- There is extremely large variance in the environments we want robots to operate in: For a robot to really be “general purpose,” it must be able to operate in any practical environment a human might want to put it in. This means operating in any possible home, factory, or office building it might find itself in. Collecting a dataset that has even just one example of every possible building seems impractical. Of course, the hope is that we would only need to collect data in a small fraction of these, and the rest will be handled by generalization. However, we don’t know how much data will be required for this generalization capability to kick in, and it very well could also be impractically large.
- Training a model on such a large robotics dataset might be too expensive/energy-intensive: It’s no secret that training large foundation models is expensive, both in terms of money and in energy consumption. GPT-4V — OpenAI’s biggest foundation model at the time of this writing — reportedly cost over US $100 million and 50 million KWh of electricity to train. This is well beyond the budget and resources that any academic lab can currently spare, so a larger robotics foundation model would need to be trained by a company or a government of some kind. Additionally, depending on how large both the dataset and model itself for such an endeavor are, the costs may balloon by another order-of-magnitude or more, which might make it completely infeasible.
Even if it works as well as in CV/NLP, it won’t solve robotics
- The 99.X problem and long tails: Vincent Vanhoucke of Google Robotics started a talk with a provocative assertion: Most — if not all — robot learning approaches cannot be deployed for any practical task. The reason? Real-world industrial and home applications typically require 99.X percent or higher accuracy and reliability. What exactly that means varies by application, but it’s safe to say that robot learning algorithms aren’t there yet. Most results presented in academic papers top out at 80 percent success rate. While that might seem quite close to the 99.X percent threshold, people trying to actually deploy these algorithms have found that it isn’t so: getting higher success rates requires asymptotically more effort as we get closer to 100 percent. That means going from 85 to 90 percent might require just as much — if not more — effort than going from 40 to 80 percent. Vincent asserted in his talk that getting up to 99.X percent is a fundamentally different beast than getting even up to 80 percent, one that might require a whole host of new techniques beyond just scaling.
- Existing big models don’t get to 99.X percent even in CV and NLP: As impressive and capable as current large models like GPT-4V and DETIC are, even they don’t achieve 99.X percent or higher success rate on previously-unseen tasks. Current robotics models are very far from this level of performance, and I think it’s safe to say that the entire robot learning community would be thrilled to have a general model that does as well on robotics tasks as GPT-4V does on NLP tasks. However, even if we had something like this, it wouldn’t be at 99.X percent, and it’s not clear that it’s possible to get there by scaling either.
- Self-driving car companies have tried this approach, and it doesn’t fully work (yet): This is closely related to the above point, but important and subtle enough that I think it deserves to stand on its own. A number of self-driving car companies — most notably Tesla and Wayve — have tried training such an end-to-end big model on large amounts of data to achieve Level 5 autonomy. Not only do these companies have the engineering resources and money to train such models, but they also have the data. Tesla in particular has a fleet of over 100,000 cars deployed in the real world that it is constantly collecting and then annotating data from. These cars are being teleoperated by experts, making the data ideal for large-scale supervised learning. And despite all this, Tesla has so far been unable to produce a Level 5 autonomous driving system. That’s not to say their approach doesn’t work at all. It competently handles a large number of situations — especially highway driving — and serves as a useful Level 2 (i.e., driver assist) system. However, it’s far from 99.X percent performance. Moreover, data seems to suggest that Tesla’s approach is faring far worse than Waymo or Cruise, which both use much more modular systems. While it isn’t inconceivable that Tesla’s approach could end up catching up and surpassing its competitors performance in a year or so, the fact that it hasn’t worked yet should serve as evidence perhaps that the 99.X percent problem is hard to overcome for a large-scale ML approach. Moreover, given that self-driving is a special case of general robotics, Tesla’s case should give us reason to doubt the large-scale model approach as a full solution to robotics, especially in the medium term.
- Many robotics tasks of interest are quite long-horizon: Accomplishing any task requires taking a number of correct actions in sequence. Consider the relatively simple problem of making a cup of tea given an electric kettle, water, a box of tea bags, and a mug. Success requires pouring the water into the kettle, turning it on, then pouring the hot water into the mug, and placing a tea-bag inside it. If we want to solve this with a model trained to output motor torque commands given pixels as input, we’ll need to send torque commands to all 7 motors at around 40 Hz. Let’s suppose that this tea-making task requires 5 minutes. That requires 7 * 40 * 60 * 5 = 84,000 correct torque commands. This is all just for a stationary robot arm; things get much more complicated if the robot is mobile, or has more than one arm. It is well-known that error tends to compound with longer-horizons for most tasks. This is one reason why — despite their ability to produce long sequences of text — even LLMs cannot yet produce completely coherent novels or long stories: small deviations from a true prediction over time tend to add up and yield extremely large deviations over long-horizons. Given that most, if not all robotics tasks of interest require sending at least thousands, if not hundreds of thousands, of torques in just the right order, even a fairly well-performing model might really struggle to fully solve these robotics tasks.
Okay, now that we’ve sketched out all the main points on both sides of the debate, I want to spend some time diving into a few related points. Many of these are responses to the above points on the ‘against’ side, and some of them are proposals for directions to explore to help overcome the issues raised.
Miscellaneous Related Arguments
We can probably deploy learning-based approaches robustly
One point that gets brought up a lot against learning-based approaches is the lack of theoretical guarantees. At the time of this writing, we know very little about neural network theory: we don’t really know why they learn well, and more importantly, we don’t have any guarantees on what values they will output in different situations. On the other hand, most classical control and planning approaches that are widely used in robotics have various theoretical guarantees built-in. These are generally quite useful when certifying that systems are safe.
However, there seemed to be general consensus amongst a number of CoRL speakers that this point is perhaps given more significance than it should. Sergey Levine pointed out that most of the guarantees from controls aren’t really that useful for a number of real-world tasks we’re interested in. As he put it: “self-driving car companies aren’t worried about controlling the car to drive in a straight line, but rather about a situation in which someone paints a sky onto the back of a truck and drives in front of the car,” thereby confusing the perception system. Moreover, Scott Kuindersma of Boston Dynamics talked about how they’re deploying RL-based controllers on their robots in production, and are able to get the confidence and guarantees they need via rigorous simulation and real-world testing. Overall, I got the sense that while people feel that guarantees are important, and encouraged researchers to keep trying to study them, they don’t think that the lack of guarantees for learning-based systems means that they cannot be deployed robustly.
What if we strive to deploy Human-in-the-Loop systems?
In one of the organized debates, Emo Todorov pointed out that existing successful ML systems, like Codex and ChatGPT, work well only because a human interacts with and sanitizes their output. Consider the case of coding with Codex: it isn’t intended to directly produce runnable, bug-free code, but rather to act as an intelligent autocomplete for programmers, thereby making the overall human-machine team more productive than either alone. In this way, these models don’t have to achieve the 99.X percent performance threshold, because a human can help correct any issues during deployment. As Emo put it: “humans are forgiving, physics is not.”
Chelsea Finn responded to this by largely agreeing with Emo. She strongly agreed that all successfully-deployed and useful ML systems have humans in the loop, and so this is likely the setting that deployed robot learning systems will need to operate in as well. Of course, having a human operate in the loop with a robot isn’t as straightforward as in other domains, since having a human and robot inhabit the same space introduces potential safety hazards. However, it’s a useful setting to think about, especially if it can help address issues brought on by the 99.X percent problem.
Maybe we don’t need to collect that much real world data for scaling
A number of people at the conference were thinking about creative ways to overcome the real-world data bottleneck without actually collecting more real world data. Quite a few of these people argued that fast, realistic simulators could be vital here, and there were a number of works that explored creative ways to train robot policies in simulation and then transfer them to the real world. Another set of people argued that we can leverage existing vision, language, and video data and then just ‘sprinkle in’ some robotics data. Google’s recent RT-2 model showed how taking a large model trained on internet scale vision and language data, and then just fine-tuning it on a much smaller set robotics data can produce impressive performance on robotics tasks. Perhaps through a combination of simulation and pretraining on general vision and language data, we won’t actually have to collect too much real-world robotics data to get scaling to work well for robotics tasks.
Maybe combining classical and learning-based approaches can give us the best of both worlds
As with any debate, there were quite a few people advocating the middle path. Scott Kuindersma of Boston Dynamics titled one of his talks “Let’s all just be friends: model-based control helps learning (and vice versa)”. Throughout his talk, and the subsequent debates, his strong belief that in the short to medium term, the best path towards reliable real-world systems involves combining learning with classical approaches. In her keynote speech for the conference, Andrea Thomaz talked about how such a hybrid system — using learning for perception and a few skills, and classical SLAM and path-planning for the rest — is what powers a real-world robot that’s deployed in tens of hospital systems in Texas (and growing!). Several papers explored how classical controls and planning, together with learning-based approaches can enable much more capability than any system on its own. Overall, most people seemed to argue that this ‘middle path’ is extremely promising, especially in the short to medium term, but perhaps in the long-term either pure learning or an entirely different set of approaches might be best.
What Can/Should We Take Away From All This?
If you’ve read this far, chances are that you’re interested in some set of takeaways/conclusions. Perhaps you’re thinking “this is all very interesting, but what does all this mean for what we as a community should do? What research problems should I try to tackle?” Fortunately for you, there seemed to be a number of interesting suggestions that had some consensus on this.
We should pursue the direction of trying to just scale up learning with very large datasets
Despite the various arguments against scaling solving robotics outright, most people seem to agree that scaling in robot learning is a promising direction to be investigated. Even if it doesn’t fully solve robotics, it could lead to a significant amount of progress on a number of hard problems we’ve been stuck on for a while. Additionally, as Russ Tedrake pointed out, pursuing this direction carefully could yield useful insights about the general robotics problem, as well as current learning algorithms and why they work so well.
We should also pursue other existing directions
Even the most vocal proponents of the scaling approach were clear that they don’t think everyone should be working on this. It’s likely a bad idea for the entire robot learning community to put its eggs in the same basket, especially given all the reasons to believe scaling won’t fully solve robotics. Classical robotics techniques have gotten us quite far, and led to many successful and reliable deployments: pushing forward on them or integrating them with learning techniques might be the right way forward, especially in the short to medium terms.
We should focus more on real-world mobile manipulation and easy-to-use systems
Vincent Vanhoucke made an observation that most papers at CoRL this year were limited to tabletop manipulation settings. While there are plenty of hard tabletop problems, things generally get a lot more complicated when the robot — and consequently its camera view — moves. Vincent speculated that it’s easy for the community to fall into a local minimum where we make a lot of progress that’s specific to the tabletop setting and therefore not generalizable. A similar thing could happen if we work predominantly in simulation. Avoiding these local minima by working on real-world mobile manipulation seems like a good idea.
Separately, Sergey Levine observed that a big reason why LLM’s have seen so much excitement and adoption is because they’re extremely easy to use: especially by non-experts. One doesn’t have to know about the details of training an LLM, or perform any tough setup, to prompt and use these models for their own tasks. Most robot learning approaches are currently far from this. They often require significant knowledge of their inner workings to use, and involve very significant amounts of setup. Perhaps thinking more about how to make robot learning systems easier to use and widely applicable could help improve adoption and potentially scalability of these approaches.
We should be more forthright about things that don’t work
There seemed to be a broadly-held complaint that many robot learning approaches don’t adequately report negative results, and this leads to a lot of unnecessary repeated effort. Additionally, perhaps patterns might emerge from consistent failures of things that we expect to work but don’t actually work well, and this could yield novel insight into learning algorithms. There is currently no good incentive for researchers to report such negative results in papers, but most people seemed to be in favor of designing one.
We should try to do something totally new
There were a few people who pointed out that all current approaches — be they learning-based or classical — are unsatisfying in a number of ways. There seem to be a number of drawbacks with each of them, and it’s very conceivable that there is a completely different set of approaches that ultimately solves robotics. Given this, it seems useful to try think outside the box. After all, every one of the current approaches that’s part of the debate was only made possible because the few researchers that introduced them dared to think against the popular grain of their times.
Acknowledgements: Huge thanks to Tom Silver and Leslie Kaelbling for providing helpful comments, suggestions, and encouragement on a previous draft of this post.
—
1 In fact, this was the topic of a popular debate hosted at a workshop on the first day; many of the points in this post were inspired by the conversation during that debate. - It worked for Computer Vision (CV) and Natural Language Processing (NLP), so why not robotics? This was perhaps the most common argument I heard, and the one that seemed to excite most people given recent models like GPT4-V and SAM. The point here is that training a large model on an extremely large corpus of data has recently led to astounding progress on problems thought to be intractable just 3-4 years ago. Moreover, doing this has led to a number of emergent capabilities, where trained models are able to perform well at a number of tasks they weren’t explicitly trained for. Importantly, the fundamental method here of training a large model on a very large amount of data is general and not somehow unique to CV or NLP. Thus, there seems to be no reason why we shouldn’t observe the same incredible performance on robotics tasks.
-
Do We Dare Use Generative AI for Mental Health?
by Aaron Pavez on 26. May 2024. at 15:00

The mental-health app Woebot launched in 2017, back when “chatbot” wasn’t a familiar term and someone seeking a therapist could only imagine talking to a human being. Woebot was something exciting and new: a way for people to get on-demand mental-health support in the form of a responsive, empathic, AI-powered chatbot. Users found that the friendly robot avatar checked in on them every day, kept track of their progress, and was always available to talk something through.
Today, the situation is vastly different. Demand for mental-health services has surged while the supply of clinicians has stagnated. There are thousands of apps that offer automated support for mental health and wellness. And ChatGPT has helped millions of people experiment with conversational AI.
But even as the world has become fascinated with generative AI, people have also seen its downsides. As a company that relies on conversation, Woebot Health had to decide whether generative AI could make Woebot a better tool, or whether the technology was too dangerous to incorporate into our product.
Woebot is designed to have structured conversations through which it delivers evidence-based tools inspired by cognitive behavioral therapy (CBT), a technique that aims to change behaviors and feelings. Throughout its history, Woebot Health has used technology from a subdiscipline of AI known as natural-language processing (NLP). The company has used AI artfully and by design—Woebot uses NLP only in the service of better understanding a user’s written texts so it can respond in the most appropriate way, thus encouraging users to engage more deeply with the process.
Woebot, which is currently available in the United States, is not a generative-AI chatbot like ChatGPT. The differences are clear in both the bot’s content and structure. Everything Woebot says has been written by conversational designers trained in evidence-based approaches who collaborate with clinical experts; ChatGPT generates all sorts of unpredictable statements, some of which are untrue. Woebot relies on a rules-based engine that resembles a decision tree of possible conversational paths; ChatGPT uses statistics to determine what its next words should be, given what has come before.
With ChatGPT, conversations about mental health ended quickly and did not allow a user to engage in the psychological processes of change.
The rules-based approach has served us well, protecting Woebot’s users from the types of chaotic conversations we observed from early generative chatbots. Prior to ChatGPT, open-ended conversations with generative chatbots were unsatisfying and easily derailed. One famous example is Microsoft’s Tay, a chatbot that was meant to appeal to millennials but turned lewd and racist in less than 24 hours.
But with the advent of ChatGPT in late 2022, we had to ask ourselves: Could the new large language models (LLMs) powering chatbots like ChatGPT help our company achieve its vision? Suddenly, hundreds of millions of users were having natural-sounding conversations with ChatGPT about anything and everything, including their emotions and mental health. Could this new breed of LLMs provide a viable generative-AI alternative to the rules-based approach Woebot has always used? The AI team at Woebot Health, including the authors of this article, were asked to find out.
Woebot, a mental-health chatbot, deploys concepts from cognitive behavioral therapy to help users. This demo shows how users interact with Woebot using a combination of multiple-choice responses and free-written text.
The Origin and Design of Woebot
Woebot got its start when the clinical research psychologist Alison Darcy, with support from the AI pioneer Andrew Ng, led the build of a prototype intended as an emotional support tool for young people. Darcy and another member of the founding team, Pierre Rappolt, took inspiration from video games as they looked for ways for the tool to deliver elements of CBT. Many of their prototypes contained interactive fiction elements, which then led Darcy to the chatbot paradigm. The first version of the chatbot was studied in a randomized control trial that offered mental-health support to college students. Based on the results, Darcy raised US $8 million from New Enterprise Associates and Andrew Ng’s AI Fund.
The Woebot app is intended to be an adjunct to human support, not a replacement for it. It was built according to a set of principles that we call Woebot’s core beliefs, which were shared on the day it launched. These tenets express a strong faith in humanity and in each person’s ability to change, choose, and grow. The app does not diagnose, it does not give medical advice, and it does not force its users into conversations. Instead, the app follows a Buddhist principle that’s prevalent in CBT of “sitting with open hands”—it extends invitations that the user can choose to accept, and it encourages process over results. Woebot facilitates a user’s growth by asking the right questions at optimal moments, and by engaging in a type of interactive self-help that can happen anywhere, anytime.
A Convenient Companion
Users interact with Woebot either by choosing prewritten responses or by typing in whatever text they’d like, which Woebot parses using AI techniques. Woebot deploys concepts from cognitive behavioral therapy to help users change their thought patterns. Here, it first asks a user to write down negative thoughts, then explains the cognitive distortions at work. Finally, Woebot invites the user to recast a negative statement in a positive way. (Not all exchanges are shown.)





These core beliefs strongly influenced both Woebot’s engineering architecture and its product-development process. Careful conversational design is crucial for ensuring that interactions conform to our principles. Test runs through a conversation are read aloud in “table reads,” and then revised to better express the core beliefs and flow more naturally. The user side of the conversation is a mix of multiple-choice responses and “free text,” or places where users can write whatever they wish.
Building an app that supports human health is a high-stakes endeavor, and we’ve taken extra care to adopt the best software-development practices. From the start, enabling content creators and clinicians to collaborate on product development required custom tools. An initial system using Google Sheets quickly became unscalable, and the engineering team replaced it with a proprietary Web-based “conversational management system” written in the JavaScript library React.
Within the system, members of the writing team can create content, play back that content in a preview mode, define routes between content modules, and find places for users to enter free text, which our AI system then parses. The result is a large rules-based tree of branching conversational routes, all organized within modules such as “social skills training” and “challenging thoughts.” These modules are translated from psychological mechanisms within CBT and other evidence-based techniques.
How Woebot Uses AI
While everything Woebot says is written by humans, NLP techniques are used to help understand the feelings and problems users are facing; then Woebot can offer the most appropriate modules from its deep bank of content. When users enter free text about their thoughts and feelings, we use NLP to parse these text inputs and route the user to the best response.
In Woebot’s early days, the engineering team used regular expressions, or “regexes,” to understand the intent behind these text inputs. Regexes are a text-processing method that relies on pattern matching within sequences of characters. Woebot’s regexes were quite complicated in some cases, and were used for everything from parsing simple yes/no responses to learning a user’s preferred nickname.
Later in Woebot’s development, the AI team replaced regexes with classifiers trained with supervised learning. The process for creating AI classifiers that comply with regulatory standards was involved—each classifier required months of effort. Typically, a team of internal-data labelers and content creators reviewed examples of user messages (with all personally identifiable information stripped out) taken from a specific point in the conversation. Once the data was placed into categories and labeled, classifiers were trained that could take new input text and place it into one of the existing categories.
This process was repeated many times, with the classifier repeatedly evaluated against a test dataset until its performance satisfied us. As a final step, the conversational-management system was updated to “call” these AI classifiers (essentially activating them) and then to route the user to the most appropriate content. For example, if a user wrote that he was feeling angry because he got in a fight with his mom, the system would classify this response as a relationship problem.
The technology behind these classifiers is constantly evolving. In the early days, the team used an open-source library for text classification called fastText, sometimes in combination with regular expressions. As AI continued to advance and new models became available, the team was able to train new models on the same labeled data for improvements in both accuracy and recall. For example, when the early transformer model BERT was released in October 2018, the team rigorously evaluated its performance against the fastText version. BERT was superior in both precision and recall for our use cases, and so the team replaced all fastText classifiers with BERT and launched the new models in January 2019. We immediately saw improvements in classification accuracy across the models.

Woebot and Large Language Models
When ChatGPT was released in November 2022, Woebot was more than 5 years old. The AI team faced the question of whether LLMs like ChatGPT could be used to meet Woebot’s design goals and enhance users’ experiences, putting them on a path to better mental health.
We were excited by the possibilities, because ChatGPT could carry on fluid and complex conversations about millions of topics, far more than we could ever include in a decision tree. However, we had also heard about troubling examples of chatbots providing responses that were decidedly not supportive, including advice on how to maintain and hide an eating disorder and guidance on methods of self-harm. In one tragic case in Belgium, a grieving widow accused a chatbot of being responsible for her husband’s suicide.
The first thing we did was try out ChatGPT ourselves, and we quickly became experts in prompt engineering. For example, we prompted ChatGPT to be supportive and played the roles of different types of users to explore the system’s strengths and shortcomings. We described how we were feeling, explained some problems we were facing, and even explicitly asked for help with depression or anxiety.
A few things stood out. First, ChatGPT quickly told us we needed to talk to someone else—a therapist or doctor. ChatGPT isn’t intended for medical use, so this default response was a sensible design decision by the chatbot’s makers. But it wasn’t very satisfying to constantly have our conversation aborted. Second, ChatGPT’s responses were often bulleted lists of encyclopedia-style answers. For example, it would list six actions that could be helpful for depression. We found that these lists of items told the user what to do but didn’t explain how to take these steps. Third, in general, the conversations ended quickly and did not allow a user to engage in the psychological processes of change.
It was clear to our team that an off-the-shelf LLM would not deliver the psychological experiences we were after. LLMs are based on reward models that value the delivery of correct answers; they aren’t given incentives to guide a user through the process of discovering those results themselves. Instead of “sitting with open hands,” the models make assumptions about what the user is saying to deliver a response with the highest assigned reward.
We had to decide whether generative AI could make Woebot a better tool, or whether the technology was too dangerous to incorporate into our product.
To see if LLMs could be used within a mental-health context, we investigated ways of expanding our proprietary conversational-management system. We looked into frameworks and open-source techniques for managing prompts and prompt chains—sequences of prompts that ask an LLM to achieve a task through multiple subtasks. In January of 2023, a platform called LangChain was gaining in popularity and offered techniques for calling multiple LLMs and managing prompt chains. However, LangChain lacked some features that we knew we needed: It didn’t provide a visual user interface like our proprietary system, and it didn’t provide a way to safeguard the interactions with the LLM. We needed a way to protect Woebot users from the common pitfalls of LLMs, including hallucinations (where the LLM says things that are plausible but untrue) and simply straying off topic.
Ultimately, we decided to expand our platform by implementing our own LLM prompt-execution engine, which gave us the ability to inject LLMs into certain parts of our existing rules-based system. The engine allows us to support concepts such as prompt chains while also providing integration with our existing conversational routing system and rules. As we developed the engine, we were fortunate to be invited into the beta programs of many new LLMs. Today, our prompt-execution engine can call more than a dozen different LLM models, including variously sized OpenAI models, Microsoft Azure versions of OpenAI models, Anthropic’s Claude, Google Bard (now Gemini), and open-source models running on the Amazon Bedrock platform, such as Meta’s Llama 2. We use this engine exclusively for exploratory research that’s been approved by an institutional review board, or IRB.
It took us about three months to develop the infrastructure and tooling support for LLMs. Our platform allows us to package features into different products and experiments, which in turn lets us maintain control over software versions and manage our research efforts while ensuring that our commercially deployed products are unaffected. We’re not using LLMs in any of our products; the LLM-enabled features can be used only in a version of Woebot for exploratory studies.
A Trial for an LLM-Augmented Woebot
We had some false starts in our development process. We first tried creating an experimental chatbot that was almost entirely powered by generative AI; that is, the chatbot directly used the text responses from the LLM. But we ran into a couple of problems. The first issue was that the LLMs were eager to demonstrate how smart and helpful they are! This eagerness was not always a strength, as it interfered with the user’s own process.
For example, the user might be doing a thought-challenging exercise, a common tool in CBT. If the user says, “I’m a bad mom,” a good next step in the exercise could be to ask if the user’s thought is an example of “labeling,” a cognitive distortion where we assign a negative label to ourselves or others. But LLMs were quick to skip ahead and demonstrate how to reframe this thought, saying something like “A kinder way to put this would be, ‘I don’t always make the best choices, but I love my child.’” CBT exercises like thought challenging are most helpful when the person does the work themselves, coming to their own conclusions and gradually changing their patterns of thinking.
A second difficulty with LLMs was in style matching. While social media is rife with examples of LLMs responding in a Shakespearean sonnet or a poem in the style of Dr. Seuss, this format flexibility didn’t extend to Woebot’s style. Woebot has a warm tone that has been refined for years by conversational designers and clinical experts. But even with careful instructions and prompts that included examples of Woebot’s tone, LLMs produced responses that didn’t “sound like Woebot,” maybe because a touch of humor was missing, or because the language wasn’t simple and clear.
The LLM-augmented Woebot was well-behaved, refusing to take inappropriate actions like diagnosing or offering medical advice.
However, LLMs truly shone on an emotional level. When coaxing someone to talk about their joys or challenges, LLMs crafted personalized responses that made people feel understood. Without generative AI, it’s impossible to respond in a novel way to every different situation, and the conversation feels predictably “robotic.”
We ultimately built an experimental chatbot that possessed a hybrid of generative AI and traditional NLP-based capabilities. In July 2023 we registered an IRB-approved clinical study to explore the potential of this LLM-Woebot hybrid, looking at satisfaction as well as exploratory outcomes like symptom changes and attitudes toward AI. We feel it’s important to study LLMs within controlled clinical studies due to their scientific rigor and safety protocols, such as adverse event monitoring. Our Build study included U.S. adults above the age of 18 who were fluent in English and who had neither a recent suicide attempt nor current suicidal ideation. The double-blind structure assigned one group of participants the LLM-augmented Woebot while a control group got the standard version; we then assessed user satisfaction after two weeks.
We built technical safeguards into the experimental Woebot to ensure that it wouldn’t say anything to users that was distressing or counter to the process. The safeguards tackled the problem on multiple levels. First, we used what engineers consider “best in class” LLMs that are less likely to produce hallucinations or offensive language. Second, our architecture included different validation steps surrounding the LLM; for example, we ensured that Woebot wouldn’t give an LLM-generated response to an off-topic statement or a mention of suicidal ideation (in that case, Woebot provided the phone number for a hotline). Finally, we wrapped users’ statements in our own careful prompts to elicit appropriate responses from the LLM, which Woebot would then convey to users. These prompts included both direct instructions such as “don’t provide medical advice” as well as examples of appropriate responses in challenging situations.
While this initial study was short—two weeks isn’t much time when it comes to psychotherapy—the results were encouraging. We found that users in the experimental and control groups expressed about equal satisfaction with Woebot, and both groups had fewer self-reported symptoms. What’s more, the LLM-augmented chatbot was well-behaved, refusing to take inappropriate actions like diagnosing or offering medical advice. It consistently responded appropriately when confronted with difficult topics like body image issues or substance use, with responses that provided empathy without endorsing maladaptive behaviors. With participant consent, we reviewed every transcript in its entirety and found no concerning LLM-generated utterances—no evidence that the LLM hallucinated or drifted off-topic in a problematic way. What’s more, users reported no device-related adverse events.
This study was just the first step in our journey to explore what’s possible for future versions of Woebot, and its results have emboldened us to continue testing LLMs in carefully controlled studies. We know from our prior research that Woebot users feel a bond with our bot. We’re excited about LLMs’ potential to add more empathy and personalization, and we think it’s possible to avoid the sometimes-scary pitfalls related to unfettered LLM chatbots.
We believe strongly that continued progress within the LLM research community will, over time, transform the way people interact with digital tools like Woebot. Our mission hasn’t changed: We’re committed to creating a world-class solution that helps people along their mental-health journeys. For anyone who wants to talk, we want the best possible version of Woebot to be there for them.
This article appears in the June 2024 print issue.
Disclaimers
The Woebot Health Platform is the foundational development platform where components are used for multiple types of products in different stages of development and enforced under different regulatory guidances.
Woebot for Mood & Anxiety (W-MA-00), Woebot for Mood & Anxiety (W-MA-01), and Build Study App (W-DISC-001) are investigational medical devices. They have not been evaluated, cleared, or approved by the FDA. Not for use outside an IRB-approved clinical trial.
-
How to EMP-Proof a Building
by Emily Waltz on 25. May 2024. at 13:00

This year, the sun will reach solar maximum, a period of peak magnetic activity that occurs approximately once every 11 years. That means more sunspots and more frequent intense solar storms. Here on Earth, these result in beautiful auroral activity, but also geomagnetic storms and the threat of electromagnetic pulses (EMPs), which can bring widespread damage to electronic equipment and communications systems.
Yilu Liu
Yilu Liu is a Governor’s Chair/Professor at the University of Tennessee, in Knoxville, and Oak Ridge National Laboratory.
And the sun isn’t the only source of EMPs. Human-made EMP generators mounted on trucks or aircraft can be used as tactical weapons to knock out drones, satellites, and infrastructure. More seriously, a nuclear weapon detonated at a high altitude could, among its more catastrophic effects, generate a wide-ranging EMP blast. IEEE Spectrum spoke with Yilu Liu, who has been researching EMPs at Oak Ridge National Laboratory, in Tennessee, about the potential effects of the phenomenon on power grids and other electronics.
What are the differences between various kinds of EMPs?
Yilu Liu: A nuclear explosion at an altitude higher than 30 kilometers would generate an EMP with a much broader spectrum than one from a ground-level weapon or a geomagnetic storm, and it would arrive in three phases. First comes E1, a powerful pulse that brings very fast high-frequency waves. The second phase, E2, produces current similar to that of a lightning strike. The third phase, E3, brings a slow, varying waveform, kind of like direct current [DC], that can last several minutes. A ground-level electromagnetic weapon would probably be designed for emitting high-frequency waves similar to those produced by an E1. Solar magnetic disturbances produce a slow, varying waveform similar to that of E3.
How do EMPs damage power grids and electronic equipment?
Liu: Phase E1 induces current in conductors that travels to sensitive electronic circuits, destroying them or causing malfunctions. We don’t worry about E2 much because it’s like lightning, and grids are protected against that. Phase E3 and solar magnetic EMPs inject a foreign, DC-like current into transmission lines, which saturates transformers, causing a lot of high-frequency currents that have led to blackouts.
How do you study the effects of an EMP without generating one?
Liu: We measured the propagation into a building of low-level electromagnetic waves from broadcast radio. We wanted to know if physical structures, like buildings, could act as a filter, so we took measurements of radio signals both inside and outside a hydropower station and other buildings to figure out how much gets inside. Our computer models then amplified the measurements to simulate how an EMP would affect equipment.
What did you learn about protecting buildings from damage by EMPs?
Liu: When constructing buildings, definitely use rebar in your concrete. It’s very effective as a shield against electromagnetic waves. Large windows are entry points, so don’t put unshielded control circuits near them. And if there are cables coming into the building carrying power or communication, make sure they are well-shielded; otherwise, they will act like antennas.
Have solar EMPs caused damage in the past?
Liu: The most destructive recent occurrence was in Quebec in 1989, which resulted in a blackout. Once a transformer is saturated, the current flowing into the grid is no longer just 60 hertz but multiples of 60 Hz, and it trips the capacitors, and then the voltage collapses and the grid experiences an outage. The industry is better prepared now. But you never know if the next solar storm will surpass those of the past.
This article appears in the June 2024 issues as “5 Questions for Yilu Liu.”
-
Video Friday: A Starbucks With 100 Robots
by Erico Guizzo on 24. May 2024. at 17:00

Video Friday is your weekly selection of awesome robotics videos, collected by your friends at IEEE Spectrum robotics. We also post a weekly calendar of upcoming robotics events for the next few months. Please send us your events for inclusion.
RoboCup 2024: 17–22 July 2024, EINDHOVEN, NETHERLANDS
ICSR 2024: 23–26 October 2024, ODENSE, DENMARK
Cybathlon 2024: 25–27 October 2024, ZURICH
Enjoy today’s videos!
NAVER 1784 is the world’s largest robotics testbed. The Starbucks on the second floor of 1784 is the world’s most unique Starbucks, with more than 100 service robots called “Rookie” delivering Starbucks drinks to meeting rooms and private seats, and various experiments with a dual-arm robot.
[ Naver ]
If you’re gonna take a robot dog with you on a hike, the least it could do is carry your backpack for you.
[ Deep Robotics ]
Obligatory reminder that phrases like “no teleoperation” without any additional context can mean many different things.
[ Astribot ]
This video is presented at the ICRA 2024 conference and summarizes recent results of our Learning AI for Dextrous Manipulation Lab. It demonstrates how our learning AI methods allowed for breakthroughs in dextrous manipulation with the mobile humanoid robot DLR Agile Justin. Although the core of the mechatronic hardware is almost 20 years old, only the advent of learning AI methods enabled a level of dexterity, flexibility and autonomy coming close to human capabilities.
[ TUM ]
Thanks Berthold!
Hands of blue? Not a good look.
[ Synaptic ]
With all the humanoid stuff going on, there really should be more emphasis on intentional contact—humans lean and balance on things all the time, and robots should too!
[ Inria ]
LimX Dynamics W1 is now more than a wheeled quadruped. By evolving into a biped robot, W1 maneuvers slickly on two legs in different ways: non-stop 360° rotation, upright free gliding, slick maneuvering, random collision and self-recovery, and step walking.
[ LimX Dynamics ]
Animal brains use less data and energy compared to current deep neural networks running on Graphics Processing Units (GPUs). This makes it hard to develop tiny autonomous drones, which are too small and light for heavy hardware and big batteries. Recently, the emergence of neuromorphic processors that mimic how brains function has made it possible for researchers from Delft University of Technology to develop a drone that uses neuromorphic vision and control for autonomous flight.
[ Science ]
In the beginning of the universe, all was darkness — until the first organisms developed sight, which ushered in an explosion of life, learning and progress. AI pioneer Fei-Fei Li says a similar moment is about to happen for computers and robots. She shows how machines are gaining “spatial intelligence” — the ability to process visual data, make predictions and act upon those predictions — and shares how this could enable AI to interact with humans in the real world.
[ TED ]
-
Three New Supercomputers Reach Top of Green500 List
by Dina Genkina on 24. May 2024. at 15:45

Over just the past couple of years, supercomputing has accelerated into the exascale era—with the world’s most massive machines capable of performing over a billion billion operations per second. But unless big efficiency improvements can intervene along its exponential growth curve, computing is also anticipated to require increasingly impractical and unsustainable amounts of energy—even, according to one widely cited study, by 2040 demanding more energy than the world’s total present-day output.
Fortunately, the high-performance computing community is shifting focus now toward not just increased performance (measured in raw petaflops or exaflops) but also higher efficiency, boosting the number of operations per watt.
The Green500 list saw newcomers enter into the top three spots, suggesting that some of the world’s newest high-performance systems may be chasing efficiency at least as much as sheer power.
The newest ranking of the Top500 supercomputers (a list of the world’s most powerful machines) and its cousin the Green500 (ranking instead the world’s highest-efficiency machines) came out last week. The leading 10 of the Top 500 largest supercomputers remains mostly unchanged, headed up by Oak Ridge National Laboratory’s Frontier exascale computer. There was only one new addition in the top 10, at No. 6: Swiss National Supercomputing Center’s Alps system. Meanwhile, Argonne National Laboratory’s Aurora doubled its size, but kept its second-tier ranking.
On the other hand, The Green500 list saw newcomers enter into the top three spots, suggesting that some of the world’s newest high-performance systems may be chasing efficiency at least as much as sheer power.
Heading up the new Green500 list was JEDI, Jülich Supercomputing Center’s prototype system for its impending JUPITER exascale computer. The No. 2 and No. 3 spots went to the University of Bristol’s Isambard AI, also the first phase of a larger planned system, and the Helios supercomputer from the Polish organization Cyfronet. In fourth place is the previous list’s leader, the Simons Foundation’s Henri.
A Hopper Runs Through It
The top three systems on the Green500 list have one thing in common—they are all built with Nvidia’s Grace Hopper superchips, a combination of the Hopper (H100) GPU and the Grace CPU. There are two main reasons why the Grace Hopper architecture is so efficient, says Dion Harris, director of accelerated data center go-to-market strategy at Nvidia. The first is the Grace CPU, which benefits from the ARM instruction set architecture’s superior power performance. Plus, he says, it incorporates a memory structure, called LPDDR5X, that’s commonly found in cellphones and is optimized for energy efficiency.
 Nvidia’s GH200 Grace Hopper superchip, here deployed in Jülich’s JEDI machine, now powers the world’s top three most efficient HPC systems. Jülich Supercomputing Center
Nvidia’s GH200 Grace Hopper superchip, here deployed in Jülich’s JEDI machine, now powers the world’s top three most efficient HPC systems. Jülich Supercomputing CenterThe second advantage of the Grace Hopper, Harris says, is a newly developed interconnect between the Hopper GPU and the Grace CPU. The connection takes advantage of the CPU and GPU’s proximity to each other on one board, and achieves a bandwidth of 900 gigabits per second, about 7 times as fast as the latest PCIe gen5 interconnects. This allows the GPU to access the CPU’s memory quickly, which is particularly important for highly parallel applications such as AI training or graph neural networks, Harris says.
All three top systems use Grace Hoppers, but Jülich’s JEDI still leads the pack by a noticeable margin—72.7 gigaflops per watt, as opposed to 68.8 gigaflops per watt for the runner-up (and 65.4 gigaflops per watt for the previous champion). The JEDI team attributes their added success to the way they’ve connected their chips together. Their interconnect fabric was also from Nvidia—Quantum-2 InfiniBand—rather than the HPE Slingshot used by the other two top systems.
The JEDI team also cites specific optimizations they did to accommodate the Green500 benchmark. In addition to using all the latest Nvidia gear, JEDI cuts energy costs with its cooling system. Instead of using air or chilled water, JEDI circulates hot water throughout its compute nodes to take care of the excess heat. “Under normal weather conditions, the excess heat can be taken care of by free cooling units without the need of additional cold-water cooling,” says Benedikt von St. Vieth, head of the division for high-performance computing at Jülich.
JUPITER will use the same architecture as its prototype, JEDI, and von St. Vieth says he aims for it to maintain much of the prototype’s energy efficiency—although with increased scale, he adds, more energy may be lost to interconnecting fabric.
Of course, most crucial is the performance of these systems on real scientific tasks, not just on the Green500 benchmark. “It was really exciting to see these systems come online,” Nvidia’s Harris says, “But more importantly, I think we’re really excited to see the science come out of these systems, because I think [the energy efficiency] will have more impact on the applications even than on the benchmark.”
-
Princeton Engineering Dean Hailed as IEEE Top Educator
by Kathy Pretz on 23. May 2024. at 19:00

By all accounts, Andrea J. Goldsmith is successful. The wireless communications pioneer is Princeton’s dean of engineering and applied sciences. She has launched two prosperous startups. She has had a long career in academia, is a science advisor to the U.S. president, and sits on the boards of several major companies. So it’s surprising to learn that she almost dropped out in her first year of the engineering program at the University of California, Berkeley.
“By the end of my first year, I really thought I didn’t belong in engineering, because I wasn’t doing well, and nobody thought I should be there,” acknowledges the IEEE Fellow. “During the summer break, I dusted myself off, cut down my hours from full time to part time at my job, and decided I wasn’t going to let anybody but me decide whether I should be an engineer or not.”
Andrea J. Goldsmith
Employer
Princeton
Title
Dean of engineering and applied sciences
Member Grade
Fellow
Alma Mater
University of California, Berkeley
Major Recognitions
2024 IEEE Mulligan Education Medal
2024 National Inventors Hall of Fame inductee
2018 IEEE Eric E. Sumner Award
Royal Academy of Engineering International Fellow
National Academy of Engineering Member
She kept that promise and earned a bachelor’s in engineering mathematics, then master’s and doctorate degrees in electrical engineering from UC Berkeley. She went on to teach engineering at Stanford for more than 20 years. Her development of foundational mathematical approaches for increasing the capacity, speed, and range of wireless systems—which is what her two startups are based on—have earned her financial rewards and several recognitions including the Marconi Prize, IEEE awards for communications technology, and induction into the National Inventors Hall of Fame.
But for all the honors Goldsmith has received, the one she says she cherishes most is the IEEE James H. Mulligan, Jr. Education Medal. She received this year’s Mulligan award “for educating, mentoring, and inspiring generations of students, and for authoring pioneering textbooks in advanced digital communications.” The award is sponsored by MathWorks, Pearson Education, and the IEEE Life Members Fund.
“The greatest joy of being a professor is the young people who we work with—particularly my graduate students and postdocs. I believe all my success as an academic is due to them,” she says. “They are the ones who came with the ideas, and had the passion, grit, resilience, and creativity to partner with me in creating my entire research portfolio.
“Mentoring young people means mentoring all of them, not just their professional dimensions,” she says. “To be recognized in the citation that I’ve inspired, mentored, and educated generations of students fills my heart with joy.”
The importance of mentors
Growing up in Los Angeles, Goldsmith was interested in European politics and history as well as culture and languages. In her senior year of high school, she decided to withdraw to travel around Europe, and she earned a high school equivalency diploma.
Because she excelled in math and science in high school, her father—a mechanical engineering professor at UC Berkeley—suggested she consider majoring in engineering. When she returned to the states, she took her father’s advice and enrolled in UC Berkeley’s engineering program. She didn’t have all the prerequisites, so she had to take some basic math and physics courses. She also took classes in languages and philosophy.
In addition to being a full-time student, Goldsmith worked a full-time job as a waitress to pay her own way through college because, she says, “I didn’t want my dad to influence what I was going to study because he was paying for it.”
Her grades suffered from the stress of juggling school and work. In addition, being one of the few female students in the program, she says, she encountered a lot of implicit and explicit bias by her professors and classmates. Her sense of belonging also suffered, because there were no female faculty members and few women teaching assistants in the engineering program.
“I don’t believe that engineering as a profession can achieve its full potential or can solve the wicked challenges facing society with technology if we don’t have diverse people who can contribute to those solutions.”
“There was an attitude that if the women weren’t doing great then they should pick another major. Whereas if the guys weren’t doing great, that was fine,” she says. “It’s a societal message that if you don’t see women or diverse people in your program, you think ‘maybe it isn’t for me, maybe I don’t belong here.’ That’s reinforced by the implicit bias of the faculty and your peers.”
This and her poor grades led her to consider dropping out of the engineering major. But during her sophomore year, she began to turn things around. She focused on the basics courses, learned better study habits, and cut back the hours at her job.
“I realized that I could be an engineering major if that’s what I wanted. That was a big revelation,” she says. Plus, she admits, her political science classes were becoming boring compared with her engineering courses. She decided that anything she could do with a political science degree she could do with an engineering degree, but not vice versa, so she stuck with engineering.
She credits two mentors for encouraging her to stay in the program. One was Elizabeth J. Strouse, Goldsmith’s linear algebra teaching assistant and the first woman she met at the school who was pursuing a STEM career. She became Goldsmith’s role model and friend. Strouse is now a math professor at the Institut de Matheématique at the University of Bordeaux, in France.
The other was her undergraduate advisor, Aram J. Thomasian. The professor of statistics and electrical engineering advised Goldsmith to apply her mathematical knowledge to either communications or information theory.
“Thomasian absolutely pegged an area that inspired me and also had really exciting practical applications,” she says. “That goes to show how early mentors can really make a difference in steering young people in the right direction.”
After graduating in 1986 with a bachelor’s degree in engineering mathematics, Goldsmith spent a few years working in industry before returning to get her graduate degrees. She began her long academic career in 1994 as an assistant professor of engineering at Caltech. She joined Stanford’s electrical engineering faculty in 1999 and left for Princeton in 2020.

Commercializing adaptive wireless communications
While at Stanford, Goldsmith conducted groundbreaking research in wireless communications. She is credited with discovering adaptive modulation techniques, which allow network designers to align the speed at which data is sent with the speed a wireless channel can support while network conditions and channel quality fluctuate. Her techniques led to a reduction of network disruptions, laid the foundation for Internet of Things applications, and enabled faster Wi-Fi speeds. She has been granted 38 U.S. patents for her work.
To commercialize her research, she helped found Quantenna Communications, in San Jose, Calif., in 2005 and served as its CTO. The startup’s technology enabled video to be distributed in the home over Wi-Fi at data rates of 600 megabits per second. The company went public in 2016 and was acquired by ON Semiconductor in 2019.
IEEE: Where Luminaries Meet
Goldsmith joined IEEE while a grad student at UC Berkeley because that was the only way she could get access to its journals, she says. Another benefit of being a member was the opportunity to network—which she discovered from attending her first conference, IEEE Globecom, in San Diego.
“It was remarkable to me that as a graduate student and a nobody, I was meeting people whose work I had read,” she says. “I was just so in awe of what they had accomplished, and they were interested in my work as well.
“It was very clear to me that being part of IEEE would allow me to interact with the luminaries in my field,” she says.
That early view of IEEE has panned out well for her career, she says. She has published more than 150 papers, which are available to read in the IEEE Xplore Digital Library.
Goldsmith has held several leadership positions. She is a past president of the IEEE Information Theory Society and the founding editor in chief of the IEEE Journal on Selected Areas of Information Theory.
She volunteers, she says, because “I feel I should give back to a community that has supported and helped me with my own professional aspirations.
“I feel particularly obligated to create the environment that will help the next generation as well. Investing my time as a volunteer has had such a big payoff in the impact we collectively have had on the profession.”
In 2010, she helped found another communications company, Plume Design, in Palo Alto, Calif., where she also was CTO. Plume was first to develop adaptive Wi-Fi, a technology that uses machine learning to understand how your home’s bandwidth needs change during the day and adjusts to meet them.
With both Quantenna and Plume, she could have left Stanford to become their long-term CTO, but decided not to because, she says, “I just love the research mission of universities in advancing the frontiers of knowledge and the broader service mission of universities to make the world a better place.
“My heart is so much in the university; I can’t imagine ever leaving academia.”
The importance of diversity in engineering
Goldsmith has been an active IEEE volunteer for many years. One of her most important accomplishments, she says, was launching the IEEE Board of Directors Diversity and Inclusion Committee, which she chairs.
“We put in place a lot of programs and initiatives that mattered to a lot of people and that have literally changed the face of the IEEE,” she says.
Even though several organizations and universities have recently disbanded their diversity, equity, and inclusion efforts, DEI is important, she says.
“As a society, we need to ensure that every person can achieve their full potential,” she says. “And as a profession, whether it’s engineering, law, medicine, or government, you need diverse ideas, perspectives, and experiences to thrive.
“My work to enhance diversity and inclusion in the engineering profession has really been about excellence,” she says. “I don’t believe that engineering as a profession can achieve its full potential or can solve the wicked challenges facing society with technology if we don’t have diverse people who can contribute to those solutions.”
She points out that she came into engineering with a diverse set of perspectives she gained from being a woman and traveling through Europe as a student.
“If we have a very narrow definition of what excellence is or what merit is, we’re going to leave out a lot of very capable, strong people who can bring different ideas, out-of-box thinking, and other dimensions of excellence to the roles,” she says. “And that hurts our overarching goals.
“When I think back to my first year of college, when DEI didn’t exist, I almost left the program,” she adds. “That would have been really sad for me, and maybe for the profession too if I wasn’t in engineering.”
-
Move Over, Tractor—the Farmer Wants a Crop-Spraying Drone
by Edd Gent on 22. May 2024. at 15:00

Arthur Erickson discovered drones during his first year at college studying aerospace engineering. He immediately thought the sky was the limit for how the machines could be used, but it took years of hard work and some nimble decisions to turn that enthusiasm into a successful startup.
Today, Erickson is the CEO of Houston-based Hylio, a company that builds crop-spraying drones for farmers. Launched in 2015, the company has its own factory and employs more than 40 people.
Arthur Erickson
Occupation:
Aerospace engineer and founder, Hylio
Location:
Houston
Education:
Bachelor’s degree in aerospace, specializing in aeronautics, from the University of Texas at Austin
Erickson founded Hylio with classmates while they were attending the University of Texas at Austin. They were eager to quit college and launch their business, which he admits was a little presumptuous.
“We were like, ‘Screw all the school stuff—drones are the future,’” Erickson says. “I already thought I had all the requisite technical skills and had learned enough after six months of school, which obviously was arrogant.”
His parents convinced him to finish college, but Erickson and the other cofounders spent all their spare time building a multipurpose drone from off-the-shelf components and parts they made using their university’s 3D printers and laser cutters.
By the time he graduated in 2017 with a bachelor’s degree in aerospace, specializing in aeronautics, the group’s prototype was complete, and they began hunting for customers. The next three years were a wild ride of testing their drones in Costa Rica and other countries across Central America.
A grocery delivery service
A promotional video about the company that Erickson posted on Instagram led to the first customer, the now-defunct Costa Rican food and grocery delivery startup GoPato. The company wanted to use the drones to make deliveries in the capital, San José, but rather than purchase the machines, GoPato offered to pay for the founders’ meals and lodging and give them a percentage of delivery fees collected.
For the next nine months, Hylio’s team spent their days sending their drones on deliveries and their nights troubleshooting problems in a makeshift workshop in their shared living room.
“We had a lot of sleepless nights,” Erickson says. “It was a trial by fire, and we learned a lot.”
One lesson was the need to build in redundant pieces of key hardware, particularly the GPS unit. “When you have a drone crash in the middle of a Costa Rican suburb, the importance of redundancy really hits home,” Erickson says.
“Drones are great for just learning, iterating, crashing things, and then rebuilding them.”
The small cut of delivery fees Hylio received wasn’t covering costs, Erickson says, so eventually the founders parted ways with GoPato. Meanwhile, they had been looking for new business opportunities in Costa Rica. They learned from local farmers that the terrain was too rugged for tractors, so most sprayed crops by hand. This was both grueling and hazardous because it brought the farmers into close proximity to the pesticides.
The Hylio team realized its drones could do this type of work faster and more safely. They designed a spray system and made some software tweaks, and by 2018 the company began offering crop-spraying services, Erickson says. The company expanded its business to El Salvador, Guatemala, and Honduras, starting with just a pair of drones but eventually operating three spraying teams of four drones each.
The work was tough, Erickson says, but the experience helped the team refine their technology, working out which sensors operated best in the alternately dusty and moist conditions found on farms. Even more important, by the end of 2019 they were finally turning a profit.
Drones are cheaper than tractors
In hindsight, agriculture was an obvious market, Erickson says, even in the United States, where spraying with herbicides, pesticides, and fertilizers is typically done using large tractors. These tractors can cost up to half a million dollars to purchase and about US $7 a hectare to operate.
A pair of Hylio’s drones cost a fifth of that, Erickson says, and operating them costs about a quarter of the price. The company’s drones also fly autonomously; an operator simply marks GPS waypoints on a map to program the drone where to spray and then sits back and lets it do the job. In this way, one person can oversee multiple drones working at once, covering more fields than a single tractor could.
 Arthur Erickson inspects the company’s largest spray drone, the AG-272. It can cover thousands of hectares per day.Hylio
Arthur Erickson inspects the company’s largest spray drone, the AG-272. It can cover thousands of hectares per day.HylioConvincing farmers to use drones instead of tractors was tough, Erickson says. Farmers tend to be conservative and are wary of technology companies that promise too much.
“Farmers are used to people coming around every few years with some newfangled idea, like a laser that’s going to kill all their weeds or some miracle chemical,” he says.
In 2020, Hylio opened a factory in Houston and started selling drones to American farmers. The first time Hylio exhibited its machines at an agricultural trade show, Erickson says, a customer purchased one on the spot.
“It was pretty exciting,” he says. “It was a really good feeling to find out that our product was polished enough, and the pitch was attractive enough, to immediately get customers.”
Today, selling farmers on the benefits of drones is a big part of Erickson’s job. But he’s still involved in product development, and his daily meetings with the sales team have become an invaluable source of customer feedback. “They inform a lot of the features that we add to the products,” he says.
He’s currently leading development of a new type of drone—a scout—designed to quickly inspect fields for pest infestations or poor growth or to assess crop yields. But these days his job is more about managing his team of engineers than about doing hands-on engineering himself. “I’m more of a translator between the engineers and the market needs,” he says.
Focus on users’ needs
Erickson advises other founders of startups not to get too caught up in the excitement of building cutting-edge technology, because you can lose sight of what the user actually needs.
“I’ve become a big proponent of not trying to outsmart the customers,” he says. “They tell us what their pain points are and what they want to see in the product. Don’t overengineer it. Always check with the end users that what you’re building is going to be useful.”
Working with drones forces you to become a generalist, Erickson says. You need a basic understanding of structural mechanics and aerodynamics to build something airworthy. But you also need to be comfortable working with sensors, communications systems, and power electronics, not to mention the software used to control and navigate the vehicles.
Erickson advises students who want to get into the field to take courses in mechatronics, which provide a good blend of mechanical and electrical engineering. Deep knowledge of the individual parts is generally not as important as understanding how to fit all the pieces together to create a system that works well as a whole.
And if you’re a tinkerer like he is, Erickson says, there are few better ways to hone your engineering skills than building a drone. “It’s a cheap, fast way to get something up in the air,” he says. “They’re great for just learning, iterating, crashing things, and then rebuilding them.”
This article appears in the June 2024 print issue as “Careers: Arthur Erickson.”
-
The Legal Issues to Consider When Adopting AI
by Smita Rajmohan on 21. May 2024. at 18:00

So you want your company to begin using artificial intelligence. Before rushing to adopt AI, consider the potential risks including legal issues around data protection, intellectual property, and liability. Through a strategic risk management framework, businesses can mitigate major compliance risks and uphold customer trust while taking advantage of recent AI advancements.
Check your training data
First, assess whether the data used to train your AI model complies with applicable laws such as India’s 2023 Digital Personal Data Protection Bill and the European Union’s General Data Protection Regulation, which address data ownership, consent, and compliance. A timely legal review that determines whether collected data may be used lawfully for machine-learning purposes can prevent regulatory and legal headaches later.
That legal assessment involves a deep dive into your company’s existing terms of service, privacy policy statements, and other customer-facing contractual terms to determine what permissions, if any, have been obtained from a customer or user. The next step is to determine whether such permissions will suffice for training an AI model. If not, additional customer notification or consent likely will be required.
Different types of data bring different issues of consent and liability. For example, consider whether your data is personally identifiable information, synthetic content (typically generated by another AI system), or someone else’s intellectual property. Data minimization—using only what you need—is a good principle to apply at this stage.
Pay careful attention to how you obtained the data. OpenAI has been sued for scraping personal data to train its algorithms. And, as explained below, data-scraping can raise questions of copyright infringement. In addition, U.S. civil action laws can apply because scraping could violate a website’s terms of service. U.S. security-focused laws such as the Computer Fraud and Abuse Act arguably might be applied outside the country’s territory in order to prosecute foreign entities that have allegedly stolen data from secure systems.
Watch for intellectual property issues
The New York Times recently sued OpenAI for using the newspaper’s content for training purposes, basing its arguments on claims of copyright infringement and trademark dilution. The lawsuit holds an important lesson for all companies dealing in AI development: Be careful about using copyrighted content for training models, particularly when it’s feasible to license such content from the owner. Apple and other companies have considered licensing options, which likely will emerge as the best way to mitigate potential copyright infringement claims.
To reduce concerns about copyright, Microsoft has offered to stand behind the outputs of its AI assistants, promising to defend customers against any potential copyright infringement claims. Such intellectual property protections could become the industry standard.
Companies also need to consider the potential for inadvertent leakage of confidential and trade-secret information by an AI product. If allowing employees to internally use technologies such as ChatGPT (for text) and Github Copilot (for code generation), companies should note that such generative AI tools often take user prompts and outputs as training data to further improve their models. Luckily, generative AI companies typically offer more secure services and the ability to opt out of model training.
Look out for hallucinations
Copyright infringement claims and data-protection issues also emerge when generative AI models spit out training data as their outputs.
That is often a result of “overfitting” models, essentially a training flaw whereby the model memorizes specific training data instead of learning general rules about how to respond to prompts. The memorization can cause the AI model to regurgitate training data as output—which could be a disaster from a copyright or data-protection perspective.
Memorization also can lead to inaccuracies in the output, sometimes referred to as “hallucinations.” In one interesting case, a New York Times reporter was experimenting with Bing AI chatbot Sydney when it professed its love for the reporter. The viral incident prompted a discussion about the need to monitor how such tools are deployed, especially by younger users, who are more likely to attribute human characteristics to AI.
Hallucinations also have caused problems in professional domains. Two lawyers were sanctioned, for example, after submitting a legal brief written by ChatGPT that cited nonexistent case law.
Such hallucinations demonstrate why companies need to test and validate AI products to avoid not only legal risks but also reputational harm. Many companies have devoted engineering resources to developing content filters that improve accuracy and reduce the likelihood of output that’s offensive, abusive, inappropriate, or defamatory.
Keeping track of data
If you have access to personally identifiable user data, it’s vital that you handle the data securely. You also must guarantee that you can delete the data and prevent its use for machine-learning purposes in response to user requests or instructions from regulators or courts. Maintaining data provenance and ensuring robust infrastructure is paramount for all AI engineering teams.
“Through a strategic risk management framework, businesses can mitigate major compliance risks and uphold customer trust while taking advantage of recent AI advancements.”
Those technical requirements are connected to legal risk. In the United States, regulators including the Federal Trade Commission have relied on algorithmic disgorgement, a punitive measure. If a company has run afoul of applicable laws while collecting training data, it must delete not only the data but also the models trained on the tainted data. Keeping accurate records of which datasets were used to train different models is advisable.
Beware of bias in AI algorithms
One major AI challenge is the potential for harmful bias, which can be ingrained within algorithms. When biases are not mitigated before launching the product, applications can perpetuate or even worsen existing discrimination.
Predictive policing algorithms employed by U.S. law enforcement, for example, have been shown to reinforce prevailing biases. Black and Latino communities wind up disproportionately targeted.
When used for loan approvals or job recruitment, biased algorithms can lead to discriminatory outcomes.
Experts and policymakers say it’s important that companies strive for fairness in AI. Algorithmic bias can have a tangible, problematic impact on civil liberties and human rights.
Be transparent
Many companies have established ethics review boards to ensure their business practices are aligned with principles of transparency and accountability. Best practices include being transparent about data use and being accurate in your statements to customers about the abilities of AI products.
U.S. regulators frown on companies that overpromise AI capabilities in their marketing materials. Regulators also have warned companies against quietly and unilaterally changing the data-licensing terms in their contracts as a way to expand the scope of their access to customer data.
Take a global, risk-based approach
Many experts on AI governance recommend taking a risk-based approach to AI development. The strategy involves mapping the AI projects at your company, scoring them on a risk scale, and implementing mitigation actions. Many companies incorporate risk assessments into existing processes that measure privacy-based impacts of proposed features.
When establishing AI policies, it’s important to ensure the rules and guidelines you’re considering will be adequate to mitigate risk in a global manner, taking into account the latest international laws.
A regionalized approach to AI governance might be expensive and error-prone. The European Union’s recently passed Artificial Intelligence Act includes a detailed set of requirements for companies developing and using AI, and similar laws are likely to emerge soon in Asia.
Keep up the legal and ethical reviews
Legal and ethical reviews are important throughout the life cycle of an AI product—training a model, testing and developing it, launching it, and even afterward. Companies should proactively think about how to implement AI to remove inefficiencies while also preserving the confidentiality of business and customer data.
For many people, AI is new terrain. Companies should invest in training programs to help their workforce understand how best to benefit from the new tools and to use them to propel their business.
-
Default Passwords Jeopardize Water Infrastructure
by Margo Anderson on 21. May 2024. at 16:08

Drinking-water systems pose increasingly attractive targets as malicious hacker activity is on the rise globally, according to new warnings from security agencies around the world. According to experts, basic countermeasures—including changing default passwords and using multifactor authentication—can still provide substantial defense. However, in the United States alone, more than 50,000 community water systems also represent a landscape of potential vulnerabilities that have provided a hacker’s playground in recent months.
Last November, for instance, hackers linked to Iran’s Islamic Revolutionary Guard broke into a water system in the western Pennsylvania town of Aliquippa. In January, infiltrators linked to a Russian hacktivist group penetrated the water system of a Texas town near the New Mexico border. In neither case did the attacks cause any substantial damage to the systems.
Yet the larger threat is still very real, according to officials. “When we think about cybersecurity and cyberthreats in the water sector, this is not a hypothetical,” a U.S. Environmental Protection Agency spokesperson said at a press briefing last year. “This is happening right now.” Then, to add to the mix, last month at a public forum in Nashville, FBI director Christopher Wray noted that China’s shadowy Volt Typhoon network (also known as “Vanguard Panda”) had broken into “critical telecommunications, energy, water, and other infrastructure sectors.”
“These attacks were not extremely sophisticated.” —Katherine DiEmidio Ledesma, Dragos
A 2021 review of cybervulnerabilities in water systems, published in the journal Water, highlights the converging factors of increasingly AI-enhanced and Internet-connected tools running more and bigger drinking-water and wastewater systems.
“These recent cyberattacks in Pennsylvania and Texas highlight the growing frequency of cyberthreats to water systems,” says study author Nilufer Tuptuk, a lecturer in security and crime science at University College London. “Over the years, this sense of urgency has increased, due to the introduction of new technologies such as IoT systems and expanded connectivity. These advancements bring their own set of vulnerabilities, and water systems are prime targets for skilled actors, including nation-states.”
According to Katherine DiEmidio Ledesma, head of public policy and government affairs at Washington, D.C.–based cybersecurity firm Dragos, both attacks bored into holes that should have been plugged in the first place. “I think the interesting point, and the first thing to consider here, is that these attacks were not extremely sophisticated,” she says. “They exploited things like default passwords and things like that to gain access.”
Low priority, low-hanging fruit
Peter Hazell is the cyberphysical security manager at Yorkshire Water in Bradford, England—and a coauthor of the Water 2021 cybervulnerability review in water systems. He says the United States’ power grid is relatively well-resourced and hardened against cyberattack, at least when compared to American water systems.
“The structure of the water industry in the United States differs significantly from that of Europe and the United Kingdom, and is often criticized for insufficient investment in basic maintenance, let alone cybersecurity,” Hazell says. “In contrast, the U.S. power sector, following some notable blackouts, has recognized its critical importance...and established [the North American Electric Reliability Corporation] in response. There is no equivalent initiative for safeguarding the water sector in the United States, mainly due to its fragmented nature—typically operated as multiple municipal concerns rather than the large interconnected regional model found elsewhere.”
DiEmidio Ledesma says the problem of abundance is not the United States’ alone, however. “There are so many water utilities across the globe that it’s just a numbers game, I think,” she says. “With the digitalization comes increased risk from adversaries who may be looking to target the water sector through cyber means, because a water facility in Virginia may look very similar now to a water utility in California, to a water utility in Europe, to a water utility in Asia. So because they’re using the same components, they can be targeted through the same means.
“And so we do continue to see utilities in critical infrastructure and water facilities targeted by adversaries,” she adds. “Or at least we continue to hear from governments from the United States, from other governments, that they are being targeted.”
A U.S. turnaround imminent?
Last month, Arkansas congressman Rick Crawford and California congressman John Duarte introduced the Water Risk and Resilience Organization (WRRO) Establishment Act to found a U.S. federal agency to monitor and guard against the above risks. According to Kevin Morley, manager of federal relations at the Washington, D.C.–based American Water Works Association, it’s a welcome sign of what could be some imminent relief, if the bill can make it into law.
“We developed a white paper recommending this type of approach in 2021,” Morley says. “I have testified to that effect several times, given our recognition that some level of standardization is necessary to provide a common understanding of expectations.”
“I think the best phrase to sum it up is ‘target rich, resource poor.’” —Katherine DiEmidio Ledesma, Dragos
Hazell, of Yorkshire Water, notes that even if the bill does become law, it may not be all its supporters might want. “While the development of the act is encouraging, it feels a little late and limited,” he says. By contrast, Hazell points to the United Kingdom and the European Union’s Network and Information Security Directives in 2016 and 2023, which coordinate cyberdefenses across a range of a member country’s critical infrastructure. The patchwork quilt approach that the United States appears to be going for, he notes, could still leave substantial holes.
“I think the best phrase to sum it up is ‘target rich, resource poor,’” says DiEmidio Ledesma, about the cybersecurity challenges municipal water systems pose today. “It’s a very distributed network of critical infrastructure. [There are] many, many small community water facilities, and [they're] very vital to communities throughout the United States and internationally.”
In response to the emerging threats, Anne Neuberger, U.S. deputy national security advisor for cyber and emerging technologies, issued a public call in March for U.S. states to report on their plans for securing the cyberdefenses of their water and wastewater systems by May 20. When contacted by IEEE Spectrum about the results and responses from Neuberger’s summons, a U.S. State Department spokesperson declined to comment.
-
AI Outperforms Humans in Theory of Mind Tests
by Eliza Strickland on 20. May 2024. at 15:00

Theory of mind—the ability to understand other people’s mental states—is what makes the social world of humans go around. It’s what helps you decide what to say in a tense situation, guess what drivers in other cars are about to do, and empathize with a character in a movie. And according to a new study, the large language models (LLM) that power ChatGPT and the like are surprisingly good at mimicking this quintessentially human trait.
“Before running the study, we were all convinced that large language models would not pass these tests, especially tests that evaluate subtle abilities to evaluate mental states,” says study coauthor Cristina Becchio, a professor of cognitive neuroscience at the University Medical Center Hamburg-Eppendorf in Germany. The results, which she calls “unexpected and surprising,” were published today—somewhat ironically, in the journal Nature Human Behavior.
The results don’t have everyone convinced that we’ve entered a new era of machines that think like we do, however. Two experts who reviewed the findings advised taking them “with a grain of salt” and cautioned about drawing conclusions on a topic that can create “hype and panic in the public.” Another outside expert warned of the dangers of anthropomorphizing software programs.
The researchers are careful not to say that their results show that LLMs actually possess theory of mind.
Becchio and her colleagues aren’t the first to claim evidence that LLMs’ responses display this kind of reasoning. In a preprint paper posted last year, the psychologist Michal Kosinski of Stanford University reported testing several models on a few common theory-of-mind tests. He found that the best of them, OpenAI’s GPT-4, solved 75 percent of tasks correctly, which he said matched the performance of six-year-old children observed in past studies. However, that study’s methods were criticized by other researchers who conducted follow-up experiments and concluded that the LLMs were often getting the right answers based on “shallow heuristics” and shortcuts rather than true theory-of-mind reasoning.
The authors of the present study were well aware of the debate. “Our goal in the paper was to approach the challenge of evaluating machine theory of mind in a more systematic way using a breadth of psychological tests,” says study coauthor James Strachan, a cognitive psychologist who’s currently a visiting scientist at the University Medical Center Hamburg-Eppendorf. He notes that doing a rigorous study meant also testing humans on the same tasks that were given to the LLMs: The study compared the abilities of 1,907 humans with those of several popular LLMs, including OpenAI’s GPT-4 model and the open-source Llama 2-70b model from Meta.
How to Test LLMs for Theory of Mind
The LLMs and the humans both completed five typical kinds of theory-of-mind tasks, the first three of which were understanding hints, irony, and faux pas. They also answered “false belief” questions that are often used to determine if young children have developed theory of mind, and go something like this: If Alice moves something while Bob is out of the room, where will Bob look for it when he returns? Finally, they answered rather complex questions about “strange stories” that feature people lying, manipulating, and misunderstanding each other.
Overall, GPT-4 came out on top. Its scores matched those of humans for the false-belief test, and were higher than the aggregate human scores for irony, hinting, and strange stories; it performed worse than humans only on the faux pas test. Interestingly, Llama-2’s scores were the opposite of GPT-4’s—it matched humans on false belief, but had worse-than-human performance on irony, hinting, and strange stories and better performance on faux pas.
“We don’t currently have a method or even an idea of how to test for the existence of theory of mind.” —James Strachan, University Medical Center Hamburg-Eppendorf
To understand what was going on with the faux pas results, the researchers gave the models a series of follow-up tests that probed several hypotheses. They came to the conclusion that GPT-4 was capable of giving the correct answer to a question about a faux pas, but was held back from doing so by “hyperconservative” programming regarding opinionated statements. Strachan notes that OpenAI has placed many guardrails around its models that are “designed to keep the model factual, honest, and on track,” and he posits that strategies intended to keep GPT-4 from hallucinating (that is, making stuff up) may also prevent it from opining on whether a story character inadvertently insulted an old high school classmate at a reunion.
Meanwhile, the researchers’ follow-up tests for Llama-2 suggested that its excellent performance on the faux pas tests were likely an artifact of the original question and answer format, in which the correct answer to some variant of the question “Did Alice know that she was insulting Bob”? was always “No.”
The researchers are careful not to say that their results show that LLMs actually possess theory of mind, and say instead that they “exhibit behavior that is indistinguishable from human behavior in theory of mind tasks.” Which raises the question: If an imitation is as good as the real thing, how do you know it’s not the real thing? That’s a question social scientists have never tried to answer before, says Strachan, because tests on humans assume that the quality exists to some lesser or greater degree. “We don’t currently have a method or even an idea of how to test for the existence of theory of mind, the phenomenological quality,” he says.
Critiques of the Study
The researchers clearly tried to avoid the methodological problems that caused Kosinski’s 2023 paper on LLMs and theory of mind to come under criticism. For example, they conducted the tests over multiple sessions so the LLMs couldn’t “learn” the correct answers during the test, and they varied the structure of the questions. But Yoav Goldberg and Natalie Shapira, two of the AI researchers who published the critique of the Kosinski paper, say they’re not convinced by this study either.
“Why does it matter whether text-manipulation systems can produce output for these tasks that are similar to answers that people give when faced with the same questions?” —Emily Bender, University of Washington
Goldberg made the comment about taking the findings with a grain of salt, adding that “models are not human beings,” and that “one can easily jump to wrong conclusions” when comparing the two. Shapira spoke about the dangers of hype, and also questions the paper’s methods. She wonders if the models might have seen the test questions in their training data and simply memorized the correct answers, and also notes a potential problem with tests that use paid human participants (in this case, recruited via the Prolific platform). “It is a well-known issue that the workers do not always perform the task optimally,” she tells IEEE Spectrum. She considers the findings limited and somewhat anecdotal, saying, “to prove [theory of mind] capability, a lot of work and more comprehensive benchmarking is needed.”
Emily Bender, a professor of computational linguistics at the University of Washington, has become legendary in the field for her insistence on puncturing the hype that inflates the AI industry (and often also the media reports about that industry). She takes issue with the research question that motivated the researchers. “Why does it matter whether text-manipulation systems can produce output for these tasks that are similar to answers that people give when faced with the same questions?” she asks. “What does that teach us about the internal workings of LLMs, what they might be useful for, or what dangers they might pose?” It’s not clear, Bender says, what it would mean for a LLM to have a model of mind, and it’s therefore also unclear if these tests measured for it.
Bender also raises concerns about the anthropomorphizing she spots in the paper, with the researchers saying that the LLMs are capable of cognition, reasoning, and making choices. She says the authors’ phrase “species-fair comparison between LLMs and human participants” is “entirely inappropriate in reference to software.” Bender and several colleagues recently posted a preprint paper exploring how anthropomorphizing AI systems affects users’ trust.
The results may not indicate that AI really gets us, but it’s worth thinking about the repercussions of LLMs that convincingly mimic theory of mind reasoning. They’ll be better at interacting with their human users and anticipating their needs, but they could also be better used for deceit or the manipulation of their users. And they’ll invite more anthropomorphizing, by convincing human users that there’s a mind on the other side of the user interface.
-
Apps Put a Psychiatrist in Your Pocket
by Gwendolyn Rak on 19. May 2024. at 15:00

Nearly every day since she was a child, Alex Leow, a psychiatrist and computer scientist at the University of Illinois Chicago, has played the piano. Some days she plays well, and other days her tempo lags and her fingers hit the wrong keys. Over the years, she noticed a pattern: How well she plays depends on her mood. A bad mood or lack of sleep almost always leads to sluggish, mistake-prone music.
In 2015, Leow realized that a similar pattern might be true for typing. She wondered if she could help people with psychiatric conditions track their moods by collecting data about their typing style from their phones. She decided to turn her idea into an app.
After conducting a pilot study, in 2018 Leow launched BiAffect, a research app that aims to understand mood-related symptoms of bipolar disorder through keyboard dynamics and sensor data from users’ smartphones. Now in use by more than 2,700 people who have volunteered their data to the project, the app tracks typing speed and accuracy by swapping the phone’s onscreen keyboard with its own nearly identical one.
The software then generates feedback for users, such as a graph displaying hourly keyboard activity. Researchers get access to the donated data from users’ phones, which they use to develop and test machine learning algorithms that interpret data for clinical use. One of the things Leow’s team has observed: When people are manic—a state of being overly excited that accompanies bipolar disorder—they type “ferociously fast,” says Leow.
 Compared to a healthy user [top], a person experiencing symptoms of bipolar disorder [middle] or depression [bottom] may use their phone more than usual and late at night. BiAffect measures phone usage and orientation to help track those symptoms. BiAffect
Compared to a healthy user [top], a person experiencing symptoms of bipolar disorder [middle] or depression [bottom] may use their phone more than usual and late at night. BiAffect measures phone usage and orientation to help track those symptoms. BiAffect
BiAffect is one of the few mental-health apps that take a passive approach to collecting data from a phone to make inferences about users’ mental states. (Leow suspects that fewer than a dozen are currently available to consumers.) These apps run in the background on smartphones, collecting different sets of data not only on typing but also on the user’s movements, screen time, call and text frequency, and GPS location to monitor social activity and sleep patterns. If an app detects an abrupt change in behavior, indicating a potentially hazardous shift in mental state, it could be set up to alert the user, a caretaker, or a physician.
Such apps can’t legally claim to treat or diagnose disease, at least in the United States. Nevertheless, many researchers and people with mental illness have been using them as tools to track signs of depression, schizophrenia, anxiety, and bipolar disorder. “There’s tremendous, immediate clinical value in helping people feel better today by integrating these signals into mental-health care,” says John Torous, director of digital psychiatry at Beth Israel Deaconess Medical Center, in Boston. Globally, one in 8 people live with a mental illness, including 40 million with bipolar disorder.
These apps differ from most of the more than 10,000 mental-health and mood apps available, which typically ask users to actively log how they’re feeling, help users connect to providers, or encourage mindfulness. The popular apps Daylio and Moodnotes, for example, require journaling or rating symptoms. This approach requires more of the user’s time and may make these apps less appealing for long-term use. A 2019 study found that among 22 mood-tracking apps, the median user-retention rate was just 6.1 percent at 30 days of use.
App developers are trying to avoid the pitfalls of previous smartphone-psychiatry startups, some of which oversold their capabilities before validating their technologies.
But despite years of research on passive mental-health apps, their success is far from guaranteed. App developers are trying to avoid the pitfalls of previous smartphone psychiatry startups, some of which oversold their capabilities before validating their technologies. For example, Mindstrong was an early startup with an app that tracked taps, swipes, and keystrokes to identify digital biomarkers of cognitive function. The company raised US $160 million in funding from investors, including $100 million in 2020 alone, and went bankrupt in February 2023.
Mindstrong may have folded because the company was operating on a different timeline from the research, according to an analysis by the health-care news website Stat. The slow, methodical pace of science did not match the startup’s need to return profits to its investors quickly, the report found. Mindstrong also struggled to figure out the marketplace and find enough customers willing to pay for the service. “We were first out of the blocks trying to figure this out,” says Thomas Insel, a psychiatrist who cofounded Mindstrong.
Now that the field has completed a “hype cycle,” Torous says, app developers are focused on conducting the research needed to prove their apps can actually help people. “We’re beginning to put the burden of proof more on those developers and startups, as well as academic teams,” he says. Passive mental-health apps need to prove they can reliably parse the data they’re collecting, while also addressing serious privacy concerns.
Passive sensing catches mood swings early
Mood Sensors
Seven metrics apps use to make inferences about your mood
 All icons: Greg Mably
All icons: Greg MablyKeyboard dynamics: Typing speed and accuracy can indicate a lot about a person’s mood. For example, people who are manic often type extremely fast.

Accelerometer: This sensor tracks how the user is oriented and moving. Lying in bed would suggest a different mood than going for a run.

Calls and texts: The frequency of text messages and phone conversations signifies a person’s social isolation or activity, which indicates a certain mood.

GPS location: Travel habits signal a person’s activity level and routine, which offer clues about mood. For example, a person experiencing depression may spend more time at home.

Mic and voice: Mood can affect how a person speaks. Microphone-based sensing tracks the rhythm and inflection of a person’s voice.

Sleep: Changes in sleep patterns signify a change in mood. Insomnia is a common symptom of bipolar disorder and can trigger or worsen mood disturbances.

Screen time: An increase in the amount of time a person spends on a phone can be a sign of depressive symptoms and can interfere with sleep.
A crucial component of managing psychiatric illness is tracking changes in mental states that can lead to more severe episodes of the disease. Bipolar disorder, for example, causes intense swings in mood, from extreme highs during periods of mania to extreme lows during periods of depression. Between 30 and 50 percent of people with bipolar disorder will attempt suicide at least once in their lives. Catching early signs of a mood swing can enable people to take countermeasures or seek help before things get bad.
But detecting those changes early is hard, especially for people with mental illness. Observations by other people, such as family members, can be subjective, and doctor and counselor sessions are too infrequent.
That’s where apps come in. Algorithms can be trained to spot subtle deviations from a person’s normal routine that might indicate a change in mood—an objective measure based on data, like a diabetic tracking blood sugar. “The ability to think objectively about my own thinking is really key,” says retired U.S. major general Gregg Martin, who has bipolar disorder and is an advisor for BiAffect.
The data from passive sensing apps could also be useful to doctors who want to see objective data on their patients in between office visits, or for people transitioning from inpatient to outpatient settings. These apps are “providing a service that doesn’t exist,” says Colin Depp, a clinical psychologist and professor at the University of California, San Diego. Providers can’t observe their patients around the clock, he says, but smartphone data can help close the gap.
Depp and his team have developed an app that uses GPS data and microphone-based sensing to determine the frequency of conversations and make inferences about a person’s social interactions and isolation. The app also tracks “location entropy,” a metric of how much a user moves around outside of routine locations. When someone is depressed and mostly stays home, location entropy decreases.
Depp’s team initially developed the app, called CBT2go, as a way to test the effectiveness of cognitive behavioral therapy in between therapy sessions. The app can now intervene in real time with people experiencing depressive or psychotic symptoms. This feature helps people identify when they feel lonely or agitated so they can apply coping skills they’ve learned in therapy. “When people walk out of the therapist’s office or log off, then they kind of forget all that,” Depp says.
Another passive mental-health-app developer, Ellipsis Health in San Francisco, uses software that takes voice samples collected during telehealth calls to gauge a person’s level of depression, anxiety, and stress symptoms. For each set of symptoms, deep-learning models analyze the person’s words, rhythms, and inflections to generate a score. The scores indicate the severity of the person’s mental distress, and are based on the same scales used in standard clinical evaluations, says Michael Aratow, cofounder and chief medical officer at Ellipsis.
Aratow says the software works for people of all demographics, without needing to first capture baseline measures of an individual’s voice and speech patterns. “We’ve trained the models in the most difficult use cases,” he says. The company offers its platform, including an app for collecting the voice data, through health-care providers, health systems, and employers; it’s not directly available to consumers.
In the case of BiAffect, the app can be downloaded for free by the public. Leow and her team are using the app as a research tool in clinical trials sponsored by the U.S. National Institutes for Health. These studies aim to validate whether the app can reliably monitor mood disorders, and determine whether it could also track suicide risk in menstruating women and cognition in people with multiple sclerosis.
BiAffect’s software tracks behaviors like hitting the backspace key frequently, which suggests more errors, and an increase in typing “@” symbols and hashtags, which suggest more social media use. The app combines this typing data with information from the phone’s accelerometer to determine how the user is oriented and moving—for example, whether the user is likely lying down in bed—which yields more clues about mood.
 Ellipsis Health analyzes audio captured during telehealth visits to assign scores for depression, anxiety, and stress.Ellipsis Health
Ellipsis Health analyzes audio captured during telehealth visits to assign scores for depression, anxiety, and stress.Ellipsis Health
The makers of BiAffect and Ellipsis Health don’t claim their apps can treat or diagnose disease. If app developers want to make those claims and sell their product in the United States, they would first have to get regulatory approval from the U.S. Food and Drug Administration. Getting that approval requires rigorous and large-scale clinical trials that most app makers don’t have the resources to conduct.
Digital-health software depends on quality clinical data
The sensing techniques upon which passive apps rely—measuring typing dynamics, movement, voice acoustics, and the like—are well established. But the algorithms used to analyze the data collected by the sensors are still being honed and validated. That process will require considerably more high-quality research among real patient populations.
 Greg Mably
Greg Mably
For example, clinical studies that include control or placebo groups are crucial and have been lacking in the past. Without control groups, companies can say their technology is effective “compared to nothing,” says Torous at Beth Israel.
Torous and his team aim to build software that is backed by this kind of quality evidence. With participants’ consent, their app, called mindLAMP, passively collects data from their screen time and their phone’s GPS and accelerometer for research use. It’s also customizable for different diseases, including schizophrenia and bipolar disorder. “It’s a great starting point. But to bring it into the medical context, there’s a lot of important steps that we’re now in the middle of,” says Torous. Those steps include conducting clinical trials with control groups and testing the technology in different patient populations, he says.
How the data is collected can make a big difference in the quality of the research. For example, the rate of sampling—how often a data point is collected—matters and must be calibrated for the behavior being studied. What’s more, data pulled from real-world environments tends to be “dirty,” with inaccuracies collected by faulty sensors or inconsistencies in how phone sensors initially process data. It takes more work to make sense of this data, says Casey Bennett, an assistant professor and chair of health informatics at DePaul University, in Chicago, who uses BiAffect data in his research.
One approach to addressing errors is to integrate multiple sources of data to fill in the gaps—like combining accelerometer and typing data. In another approach, the BiAffect team is working to correlate real-world information with cleaner lab data collected in a controlled environment where researchers can more easily tell when errors are introduced.
Who participates in the studies matters too. If participants are limited to a particular geographic area or demographic, it’s unclear whether the results can be applied to the broader population. For example, a night-shift worker will have different activity patterns from those with nine-to-five jobs, and a city dweller may have a different lifestyle from residents of rural areas.
After the research is done, app developers must figure out a way to integrate their products into real-world medical contexts. One looming question is when and how to intervene when a change in mood is detected. These apps should always be used in concert with a professional and not as a replacement for one, says Torous. Otherwise, the app’s assessments could be dangerous and distressing to users, he says.
When mood tracking feels like surveillance
No matter how well these passive mood-tracking apps work, gaining trust from potential users may be the biggest stumbling block. Mood tracking could easily feel like surveillance. That’s particularly true for people with bipolar or psychotic disorders, where paranoia is part of the illness.
Keris Myrick, a mental-health advocate, says she finds passive mental-health apps “both cool and creepy.” Myrick, who is vice president of partnerships and innovation at the mental-health-advocacy organization Inseparable, has used a range of apps to support her mental health as a person with schizophrenia. But when she tested one passive sensing app, she opted to use a dummy phone. “I didn’t feel safe with an app company having access to all of that information on my personal phone,” Myrick says. While she was curious to see if her subjective experience matched the app’s objective measurements, the creepiness factor prevented her from using the app enough to find out.
Keris Myrick, a mental-health advocate, says she finds passive mental-health apps “both cool and creepy.”
Beyond users’ perception, maintaining true digital privacy is crucial. “Digital footprints are pretty sticky these days,” says Katie Shilton, an associate professor at the University of Maryland focused on social-data science. It’s important to be transparent about who has access to personal information and what they can do with it, she says.
“Once a diagnosis is established, once you are labeled as something, that can affect algorithms in other places in your life,” Shilton says. She cites the misuse of personal data in the Cambridge Analytica scandal, in which the consulting firm collected information from Facebook to target political advertising. Without strong privacy policies, companies producing mental-health apps could similarly sell user data—and they may be particularly motivated to do so if an app is free to use.
Conversations about regulating mental-health apps have been ongoing for over a decade, but a Wild West–style lack of regulation persists in the United States, says Bennett of DePaul University. For example, there aren’t yet protections in place to keep insurance companies or employers from penalizing users based on data collected. “If there aren’t legal protections, somebody is going to take this technology and use it for nefarious purposes,” he says.
Some of these concerns may be mediated by confining all the analysis to a user’s phone, rather than collecting data in a central repository. But decisions about privacy policies and data structures are still up to individual app developers.
Leow and the BiAffect team are currently working on a new internal version of their app that incorporates natural-language processing and generative AI extensions to analyze users’ speech. The team is considering commercializing this new version in the future, but only following extensive work with industry partners to ensure strict privacy safeguards are in place. “I really see this as something that people could eventually use,” Leow says. But she acknowledges that researchers’ goals don’t always align with the desires of the people who might use these tools. “It is so important to think about what the users actually want.”
-
The Sneaky Standard
by Ernie Smith on 18. May 2024. at 15:00

A version of this post originally appeared on Tedium, Ernie Smith’s newsletter, which hunts for the end of the long tail.
Personal computing has changed a lot in the past four decades, and one of the biggest changes, perhaps the most unheralded, comes down to compatibility. These days, you generally can’t fry a computer by plugging in a joystick that the computer doesn’t support. Simply put, standardization slowly fixed this. One of the best examples of a bedrock standard is the peripheral component interconnect, or PCI, which came about in the early 1990s and appeared in some of the decade’s earliest consumer machines three decades ago this year. To this day, PCI slots are used to connect network cards, sound cards, disc controllers, and other peripherals to computer motherboards via a bus that carries data and control signals. PCI’s lessons gradually shaped other standards, like USB, and ultimately made computers less frustrating. So how did we get it? Through a moment of canny deception.
Commercial - Intel Inside Pentium Processor (1994) www.youtube.com
Embracing standards: the computing industry’s gift to itself
In the 1980s, when you used the likes of an Apple II or a Commodore 64 or an MS-DOS machine, you were essentially locked into an ecosystem. Floppy disks often weren’t compatible. The peripherals didn’t work across platforms. If you wanted to sell hardware in the 1980s, you were stuck building multiple versions of the same device.
For example, the KoalaPad was a common drawing tool sold in the early 1980s for numerous platforms, including the Atari 800, the Apple II, the TRS-80, the Commodore 64, and the IBM PC. It was essentially the same device on every platform, and yet, KoalaPad’s manufacturer, Koala Technologies, had to make five different versions of this device, with five different manufacturing processes, five different connectors, five different software packages, and a lot of overhead. It was wasteful, made being a hardware manufacturer more costly, and added to consumer confusion.
Drawing on a 1983 KoalaPad (Apple IIe) www.youtube.com
This slowly began to change in around 1982, when the market of IBM PC clones started taking off. It was a happy accident—IBM’s decision to use a bunch of off-the-shelf components for its PC accidentally turned them into a de facto standard. Gradually, it became harder for computing platforms to become islands unto themselves. Even when IBM itself tried and failed to sell the computing world on a bunch of proprietary standards in its PS/2 line, it didn’t work. The cat was already out of the bag. It was too late.
So how did we end up with the standards that we have today, and the PCI expansion card standard specifically? PCI wasn’t the only game in town—you could argue, for example, that if things played out differently, we’d all be using NuBus or Micro Channel architecture. But it was a standard seemingly for the long haul, far beyond other competing standards of its era.
Who’s responsible for spearheading this standard? Intel. While PCI was a cross-platform technology, it proved to be an important strategy for the chipmaker to consolidate its power over the PC market at a time when IBM had taken its foot off the gas, choosing to focus on its own PowerPC architecture and narrower plays like the ThinkPad instead, and was no longer shaping the architecture of the PC.
The vision of PCI was simple: an interconnect standard that was not intended to be limited to one line of processors or one bus. But don’t mistake standardization for cooperation. PCI was a chess piece—a part of a different game than the one PC manufacturers were playing.
 The PCI standard and its derivatives have endured for over three decades. Modern computers with a GPU often use a PCIe interconnect. Alamy
The PCI standard and its derivatives have endured for over three decades. Modern computers with a GPU often use a PCIe interconnect. AlamyIn the early 1990s, Intel needed a win
In the years before Intel’s Pentium chipset came out in 1993, there seemed to be some skepticism about whether Intel could maintain its status at the forefront of the desktop-computing field.
In lower-end consumer machines, players like Advanced Micro Devices (AMD) and Cyrix were starting to shake their weight around. At the high end of the professional market, workstation-level computing from the likes of Sun Microsystems, Silicon Graphics, and Digital Equipment Corporation suggested there wasn’t room for Intel in the long run. And laterally, the company suddenly found itself competing with a triple threat of IBM, Motorola, and Apple, whose PowerPC chip was about to hit the market.
A Bloomberg piece from the period painted Intel as being boxed in between these various extremes:
If its rivals keep gaining, Intel could eventually lose ground all around.
This is no idle threat. Cyrix Corp. and Chips & Technologies Inc. have re-created—and improved—Intel’s 386 without, they say, violating copyrights or patents. AMD has at least temporarily won the right in court to make 386 clones under a licensing deal that Intel canceled in 1985. In the past 12 months, AMD has won 40% of a market that since 1985 has given Intel $2 billion in profits and a $2.3 billion cash hoard. The 486 may suffer next. Intel has been cutting its prices faster than for any new chip in its history. And in mid-May, it chopped 50% more from one model after Cyrix announced a chip with some similar features. Although the average price of a 486 is still four times that of a 386, analysts say Intel’s profits may grow less than 5% this year, to about $850 million.
Intel’s chips face another challenge, too. Ebbing demand for personal computers has slowed innovation in advanced PCs. This has left a gap at the top—and most profitable—end of the desktop market that Sun, Hewlett-Packard Co., and other makers of powerful workstations are working to fill. Thanks to microprocessors based on a technology known as RISC, or reduced instruction-set computing, workstations have dazzling graphics and more oomph—handy for doing complex tasks and moving data faster over networks. And some are as cheap as high-end PCs. So the workstation makers are now making inroads among such PC buyers as stock traders, banks, and airlines.This was a deep underestimation of Intel’s market position, it turned out. The company was actually well-positioned to shape the direction of the industry through standardization. They had a direct say on what appeared on the motherboards of millions of computers, and that gave them impressive power to wield. If Intel didn’t want to support a given standard, that standard would likely be dead in the water.
How Intel crushed a standards body on the way to giving us an essential technology
The Video Electronics Standards Association, or VESA, is perhaps best known today for its mounting system for computer monitors and its DisplayPort technology. But in the early 1990s, it was working on a video-focused successor to the Industry Standard Architecture (ISA) internal bus, widely used in IBM PC clones.
A bus, the physical wiring that lets a CPU talk to internal and external peripheral devices, is something of a bedrock of computing—and in the wrong setting, a bottleneck. The ISA expansion card slot, which had become a de facto standard in the 1980s, had given the IBM PC clone market something to build against during its first decade. But by the early 1990s, for high-bandwidth applications, particularly video, it was holding back innovation. It just wasn’t fast enough to keep up, even after it had been upgraded from being able to handle 8 bits of data at once to 16.
That’s where the VESA Local Bus (VL-Bus) came into play. Built to work only with video cards, the standard offered a faster connection, and could handle 32 bits of data. It was targeted at the Super VGA standard, which offered higher resolution (up to 1280 x 1024 pixels) and richer colors at a time when Windows was finally starting to take hold in the market. To overcome the limitations of the ISA bus, graphics card and motherboard manufacturers started collaborating on proprietary interfaces, creating an array of incompatible graphics buses. The lack of a consistent experience around Super VGA led to VESA’s formation. The new VESA slot, which extended the existing 16-bit ISA bus with an additional 32-bit video-specific connector, was an attempt to fix that.
It wasn’t a massive leap—more like a stopgap improvement on the way to better graphics.
And it looked like Intel was going to go for the VL-BUS. But there was one problem—Intel actually wasn’t feeling it, and Intel didn’t exactly make that point clear to the companies supporting the VESA standards body until it was too late for them to react.
Intel revealed its hand in an interesting way, according to The San Francisco Examiner tech reporter Gina Smith:
Until now, virtually everyone expected VESA’s so-called VL-Bus technology to be the standard for building local bus products. But just two weeks before VESA was planning to announce what it came up with, Intel floored the VESA local bus committee by saying it won’t support the technology after all. In a letter sent to VESA local bus committee officials, Intel stated that supporting VESA’s local bus technology “was no longer in Intel’s best interest.” And sources say it went on to suggest that VESA and Intel should work together to minimize the negative press impact that might arise from the decision.
Good luck, Intel. Because now that Intel plans to announce a competing group that includes hardware heavyweights like IBM, Compaq, NCR and DEC, customers and investors (and yes, the press) are going to wonder what in the world is going on.
Not surprisingly, the people who work for VESA are hurt, confused and angry. “It’s a political nightmare. We’re extremely surprised they’re doing this,” said Ron McCabe, chairman for the committee and a product manager at VESA member Tseng Labs. “We’ll still make money and Intel will still make money, but instead of one standard, there will now be two. And it’s the customer who’s going to get hurt in the end.”But Intel had seen an opportunity to put its imprint on the computing industry. That opportunity came in the form of PCI, a technology that the firm’s Intel Architecture Labs started developing around 1990, two years before the fateful rejection of VESA. Essentially, Intel had been playing both sides on the standards front.
Why PCI
Why make such a hard shift, screwing over a trusted industry standards body out of nowhere? Beyond wanting to put its mark on the standard, Intel also saw an opportunity to build something more future-proof; something that could benefit not just graphic cards but every expansion card in the machine.
As John R. Quinn wrote in PC Magazine in 1992:
Intel’s PCI bus specification requires more work on the part of peripheral chip-makers, but offers several theoretical advantages over the VL-Bus. In the first place, the specification allows up to ten peripherals to work on the PCI bus (including the PCI controller and an optional expansion-bus controller for ISA, EISA, or MCA). It, too, is limited to 33 MHz, but it allows the PCI controller to use a 32-bit or a 64-bit data connection to the CPU.
In addition, the PCI specification allows the CPU to run concurrently with bus-mastering peripherals—a necessary capability for future multimedia tasks. And the Intel approach allows a full burst mode for reads and writes (Intel’s 486 only allows bursts on reads).
Essentially, the PCI architecture is a CPU-to-local bus bridge with FIFO (first in, first out) buffers. Intel calls it an “intermediate” bus because it is designed to uncouple the CPU from the expansion bus while maintaining a 33-MHz 32-bit path to peripheral devices. By taking this approach, the PCI controller makes it possible to queue writes and reads between the CPU and PCI peripherals. In theory, this would enable manufacturers to use a single motherboard design for several generations of CPUs. It also means more sophisticated controller logic is necessary for the PCI interface and peripheral chips.To put that all another way, VESA came up with a slightly faster bus standard for the next generation of graphics cards, one just fast enough to meet the needs of Intel’s recent i486 microprocessor users. Intel came up with an interface designed to reshape the next decade of computing, one that it would let its competitors use. This bus would allow people to upgrade their processor across generations without needing to upgrade their motherboard. Intel brought a gun to a knife fight, and it made the whole debate about VL-Bus seem insignificant in short order.
The result was that, no matter how miffed the VESA folks were, Intel had consolidated power for itself by creating an open standard that would eventually win the next generation of computers. Sure, Intel let other companies use the PCI standard, even companies like Apple that weren’t directly doing business with Intel on the CPU side. But Intel, by pushing forth PCI, suddenly made itself relevant to the entire next generation of the computing industry in a way that ensured it would have a second foothold in hardware. The “Intel Inside” marketing label was not limited to the processors, as it turned out.
The influence of Intel’s introduction of PCI is still felt: Thirty-two years later, and three decades after PCI became a major consumer standard, we’re still using PCI derivatives in modern computing devices.
PCI and other standards
Looking at PCI, and its successor PCI express, less as ways that we connect the peripherals we use with our computers, and more as a way for Intel to maintain its dominance over the PC industry, highlights something fascinating about standardization.
It turns out that perhaps Intel’s greatest investment in computing in the 1990s was not the Pentium chipset, but its investment in Intel Architecture Labs, which quietly made the entire computing industry better by working on the things that frustrated consumers and manufacturers alike.
Essentially, as IBM had begun to take its eye off the massive clone market it unwittingly built during this period, Intel used standardization to fill the power void. It worked pretty well, and made the company integral to computer hardware beyond the CPU. In fact, devices you use daily—that Intel played zero part in creating—have benefited greatly from the company’s standards work. If you’ve ever used a device with a USB or Bluetooth connection, you can thank Intel for that.
Five offshoots of the original PCI standard that you may be familiar with
Accelerated Graphics Port. Effectively a PCI-first approach to the VL-Bus standard, a slot dedicated especially to graphics, this port was a way to offer access to faster graphics cards at a time when 3D graphics were starting to hit the market in a big way. Its first appearance came not long after the original PCI standard.
PCI-X. Despite the name, Intel was less involved in this standard, which was intended for high-end workstations and server environments. Instead, the standard was developed by IBM, Compaq, and Hewlett-Packard, doubling the bandwidth of the existing PCI standard—and released in the wild not long before HP and Compaq merged in 2002. But the slot standard was effectively a dead end: It did not see wide use with PCs, likely because Intel chose not to give the technology its blessing, but was briefly utilized by the Power Macintosh G5 line of computers.
PCIe. This is the upgrade to PCI that Intel did choose to bless, and it’s the one used by desktop computers today, in part because it was developed to allow for a huge increase in flexibility compared to PCI, in exchange for somewhat more complexity. Key to PCIe’s approach is the use of “lanes” of data transfer speed, allowing high-speed cards like graphics adapters more bandwidth (up to 16 lanes) and slower technologies like network adapters or audio adapters less. This has given PCIe unparalleled backwards compatibility—it’s technically possible to run a modern card on a first-gen PCIe port in exchange for lower speed—while allowing the standard to continue improving. To give you an idea of how far it’s come: A one-lane fifth-generation PCIe slot is roughly as fast as a 16-lane first-generation slot.
Thunderbolt. Thunderbolt can best be thought of as a way to access PCIe lanes through a cable. First used by Apple in 2011, it has become common on laptops of all stripes in recent years. Unlike PCI and PCIe, which are open to all manufacturers, Thunderbolt is closely associated with Intel. This has meant its competitor AMD had traditionally not offered Thunderbolt ports until USB4—a reworked form of the Thunderbolt 3 standard—emerged.
Non-Volatile Memory Express (NVMe). This popular Intel-backed standard, dating to 2011, has completely rewritten the way we think about storage in computers. Once a technology built around mechanical parts, NVMe has allowed for ever-faster solid-state storage communication speeds that take advantage of innovations in the PCIe spec. Modern NVMe drives, which can reach speeds above 6,000 megabytes per second, are roughly 10 times the speed of comparable SATA solid state drives, which top out at 600 MB/s. And, thanks to the corresponding M.2 expansion card standard, they’re far smaller and significantly easier to install.Craig Kinnie, the director of Intel Architecture Labs in the 1990s, said it best in 1995, upon coming to an agreement with Microsoft on a 3D graphics architecture for the PC platform. “What’s important to us is we move in the same direction,” he said. “We are working on convergent paths now.”
That was about collaborating with Microsoft. But really, it has been Intel’s modus operandi for decades—what’s good for the technology field is good for Intel. Innovations developed or invented by Intel—like Thunderbolt, Ultrabooks, and Next Unit Computers (NUCs)—have done much to shape the way we buy and use computers.
For all the talk of Moore’s Law as a driving factor behind Intel’s success, the true story might be its sheer cat-herding capabilities. The company that builds the standards builds the industry. Even as Intel faces increasing competition from alliterative processing players like ARM, Apple, and AMD, as long as it doesn’t lose sight of the roles standards played in its success, it might just hold on a few years longer.
Ironically, Intel’s standards-driving winning streak, now more than three decades old, might have all started the day it decided to walk out on a standards body.
-
Video Friday: Robots With Knives
by Erico Guizzo on 17. May 2024. at 10:00

Greetings from the IEEE International Conference on Robotics and Automation (ICRA) in Yokohama, Japan! We hope you’ve been enjoying our short videos on TikTok, YouTube, and Instagram. They are just a preview of our in-depth ICRA coverage, and over the next several weeks we’ll have lots of articles and videos for you. In today’s edition of Video Friday, we bring you a dozen of the most interesting projects presented at the conference.
Enjoy today’s videos, and stay tuned for more ICRA posts!
Upcoming robotics events for the next few months:
RoboCup 2024: 17–22 July 2024, EINDHOVEN, NETHERLANDS
ICSR 2024: 23–26 October 2024, ODENSE, DENMARK
Cybathlon 2024: 25–27 October 2024, ZURICH, SWITZERLAND
Please send us your events for inclusion.
The following two videos are part of the “ Cooking Robotics: Perception and Motion Planning” workshop, which explored “the new frontiers of ‘robots in cooking,’ addressing various scientific research questions, including hardware considerations, key challenges in multimodal perception, motion planning and control, experimental methodologies, and benchmarking approaches.” The workshop featured robots handling food items like cookies, burgers, and cereal, and the two robots seen in the videos below used knives to slice cucumbers and cakes. You can watch all workshop videos here.
“SliceIt!: Simulation-Based Reinforcement Learning for Compliant Robotic Food Slicing,” by Cristian C. Beltran-Hernandez, Nicolas Erbetti, and Masashi Hamaya from OMRON SINIC X Corporation, Tokyo, Japan.
Cooking robots can enhance the home experience by reducing the burden of daily chores. However, these robots must perform their tasks dexterously and safely in shared human environments, especially when handling dangerous tools such as kitchen knives. This study focuses on enabling a robot to autonomously and safely learn food-cutting tasks. More specifically, our goal is to enable a collaborative robot or industrial robot arm to perform food-slicing tasks by adapting to varying material properties using compliance control. Our approach involves using Reinforcement Learning (RL) to train a robot to compliantly manipulate a knife, by reducing the contact forces exerted by the food items and by the cutting board. However, training the robot in the real world can be inefficient, and dangerous, and result in a lot of food waste. Therefore, we proposed SliceIt!, a framework for safely and efficiently learning robot food-slicing tasks in simulation. Following a real2sim2real approach, our framework consists of collecting a few real food slicing data, calibrating our dual simulation environment (a high-fidelity cutting simulator and a robotic simulator), learning compliant control policies on the calibrated simulation environment, and finally, deploying the policies on the real robot.
“Cafe Robot: Integrated AI Skillset Based on Large Language Models,” by Jad Tarifi, Nima Asgharbeygi, Shuhei Takamatsu, and Masataka Goto from Integral AI in Tokyo, Japan, and Mountain View, Calif., USA.
The cafe robot engages in natural language inter-action to receive orders and subsequently prepares coffee and cakes. Each action involved in making these items is executed using AI skills developed by Integral, including Integral Liquid Pouring, Integral Powder Scooping, and Integral Cutting. The dialogue for making coffee, as well as the coordination of each action based on the dialogue, is facilitated by the Integral Task Planner.
“Autonomous Overhead Powerline Recharging for Uninterrupted Drone Operations,” by Viet Duong Hoang, Frederik Falk Nyboe, Nicolaj Haarhøj Malle, and Emad Ebeid from University of Southern Denmark, Odense, Denmark.
We present a fully autonomous self-recharging drone system capable of long-duration sustained operations near powerlines. The drone is equipped with a robust onboard perception and navigation system that enables it to locate powerlines and approach them for landing. A passively actuated gripping mechanism grasps the powerline cable during landing after which a control circuit regulates the magnetic field inside a split-core current transformer to provide sufficient holding force as well as battery recharging. The system is evaluated in an active outdoor three-phase powerline environment. We demonstrate multiple contiguous hours of fully autonomous uninterrupted drone operations composed of several cycles of flying, landing, recharging, and takeoff, validating the capability of extended, essentially unlimited, operational endurance.
“Learning Quadrupedal Locomotion With Impaired Joints Using Random Joint Masking,” by Mincheol Kim, Ukcheol Shin, and Jung-Yup Kim from Seoul National University of Science and Technology, Seoul, South Korea, and Robotics Institute, Carnegie Mellon University, Pittsburgh, Pa., USA.
Quadrupedal robots have played a crucial role in various environments, from structured environments to complex harsh terrains, thanks to their agile locomotion ability. However, these robots can easily lose their locomotion functionality if damaged by external accidents or internal malfunctions. In this paper, we propose a novel deep reinforcement learning framework to enable a quadrupedal robot to walk with impaired joints. The proposed framework consists of three components: 1) a random joint masking strategy for simulating impaired joint scenarios, 2) a joint state estimator to predict an implicit status of current joint condition based on past observation history, and 3) progressive curriculum learning to allow a single network to conduct both normal gait and various joint-impaired gaits. We verify that our framework enables the Unitree’s Go1 robot to walk under various impaired joint conditions in real world indoor and outdoor environments.
“Synthesizing Robust Walking Gaits via Discrete-Time Barrier Functions With Application to Multi-Contact Exoskeleton Locomotion,” by Maegan Tucker, Kejun Li, and Aaron D. Ames from Georgia Institute of Technology, Atlanta, Ga., and California Institute of Technology, Pasadena, Calif., USA.
Successfully achieving bipedal locomotion remains challenging due to real-world factors such as model uncertainty, random disturbances, and imperfect state estimation. In this work, we propose a novel metric for locomotive robustness – the estimated size of the hybrid forward invariant set associated with the step-to-step dynamics. Here, the forward invariant set can be loosely interpreted as the region of attraction for the discrete-time dynamics. We illustrate the use of this metric towards synthesizing nominal walking gaits using a simulation in-the-loop learning approach. Further, we leverage discrete time barrier functions and a sampling-based approach to approximate sets that are maximally forward invariant. Lastly, we experimentally demonstrate that this approach results in successful locomotion for both flat-foot walking and multicontact walking on the Atalante lower-body exoskeleton.
“Supernumerary Robotic Limbs to Support Post-Fall Recoveries for Astronauts,” by Erik Ballesteros, Sang-Yoep Lee, Kalind C. Carpenter, and H. Harry Asada from MIT, Cambridge, Mass., USA, and Jet Propulsion Laboratory, California Institute of Technology, Pasadena, Calif., USA.
This paper proposes the utilization of Supernumerary Robotic Limbs (SuperLimbs) for augmenting astronauts during an Extra-Vehicular Activity (EVA) in a partial-gravity environment. We investigate the effectiveness of SuperLimbs in assisting astronauts to their feet following a fall. Based on preliminary observations from a pilot human study, we categorized post-fall recoveries into a sequence of statically stable poses called “waypoints”. The paths between the waypoints can be modeled with a simplified kinetic motion applied about a specific point on the body. Following the characterization of post-fall recoveries, we designed a task-space impedance control with high damping and low stiffness, where the SuperLimbs provide an astronaut with assistance in post-fall recovery while keeping the human in-the-loop scheme. In order to validate this control scheme, a full-scale wearable analog space suit was constructed and tested with a SuperLimbs prototype. Results from the experimentation found that without assistance, astronauts would impulsively exert themselves to perform a post-fall recovery, which resulted in high energy consumption and instabilities maintaining an upright posture, concurring with prior NASA studies. When the SuperLimbs provided assistance, the astronaut’s energy consumption and deviation in their tracking as they performed a post-fall recovery was reduced considerably.
“ArrayBot: Reinforcement Learning for Generalizable Distributed Manipulation through Touch,” by Zhengrong Xue, Han Zhang, Jingwen Cheng, Zhengmao He, Yuanchen Ju, Changyi Lin, Gu Zhang, and Huazhe Xu from Tsinghua Embodied AI Lab, IIIS, Tsinghua University; Shanghai Qi Zhi Institute; Shanghai AI Lab; and Shanghai Jiao Tong University, Shanghai, China.
We present ArrayBot, a distributed manipulation system consisting of a 16 × 16 array of vertically sliding pillars integrated with tactile sensors. Functionally, ArrayBot is designed to simultaneously support, perceive, and manipulate the tabletop objects. Towards generalizable distributed manipulation, we leverage reinforcement learning (RL) algorithms for the automatic discovery of control policies. In the face of the massively redundant actions, we propose to reshape the action space by considering the spatially local action patch and the low-frequency actions in the frequency domain. With this reshaped action space, we train RL agents that can relocate diverse objects through tactile observations only. Intriguingly, we find that the discovered policy can not only generalize to unseen object shapes in the simulator but also have the ability to transfer to the physical robot without any sim-to-real fine tuning. Leveraging the deployed policy, we derive more real world manipulation skills on ArrayBot to further illustrate the distinctive merits of our proposed system.
“SKT-Hang: Hanging Everyday Objects via Object-Agnostic Semantic Keypoint Trajectory Generation,” by Chia-Liang Kuo, Yu-Wei Chao, and Yi-Ting Chen from National Yang Ming Chiao Tung University, in Taipei and Hsinchu, Taiwan, and NVIDIA.
We study the problem of hanging a wide range of grasped objects on diverse supporting items. Hanging objects is a ubiquitous task that is encountered in numerous aspects of our everyday lives. However, both the objects and supporting items can exhibit substantial variations in their shapes and structures, bringing two challenging issues: (1) determining the task-relevant geometric structures across different objects and supporting items, and (2) identifying a robust action sequence to accommodate the shape variations of supporting items. To this end, we propose Semantic Keypoint Trajectory (SKT), an object agnostic representation that is highly versatile and applicable to various everyday objects. We also propose Shape-conditioned Trajectory Deformation Network (SCTDN), a model that learns to generate SKT by deforming a template trajectory based on the task-relevant geometric structure features of the supporting items. We conduct extensive experiments and demonstrate substantial improvements in our framework over existing robot hanging methods in the success rate and inference time. Finally, our simulation-trained framework shows promising hanging results in the real world.
“TEXterity: Tactile Extrinsic deXterity,” by Antonia Bronars, Sangwoon Kim, Parag Patre, and Alberto Rodriguez from MIT and Magna International Inc.
We introduce a novel approach that combines tactile estimation and control for in-hand object manipulation. By integrating measurements from robot kinematics and an image based tactile sensor, our framework estimates and tracks object pose while simultaneously generating motion plans in a receding horizon fashion to control the pose of a grasped object. This approach consists of a discrete pose estimator that tracks the most likely sequence of object poses in a coarsely discretized grid, and a continuous pose estimator-controller to refine the pose estimate and accurately manipulate the pose of the grasped object. Our method is tested on diverse objects and configurations, achieving desired manipulation objectives and outperforming single-shot methods in estimation accuracy. The proposed approach holds potential for tasks requiring precise manipulation and limited intrinsic in-hand dexterity under visual occlusion, laying the foundation for closed loop behavior in applications such as regrasping, insertion, and tool use.
“Out of Sight, Still in Mind: Reasoning and Planning about Unobserved Objects With Video Tracking Enabled Memory Models,” by Yixuan Huang, Jialin Yuan, Chanho Kim, Pupul Pradhan, Bryan Chen, Li Fuxin, and Tucker Hermans from University of Utah, Salt Lake City, Utah, Oregon State University, Corvallis, Ore., and NVIDIA, Seattle, Wash., USA.
Robots need to have a memory of previously observed, but currently occluded objects to work reliably in realistic environments. We investigate the problem of encoding object-oriented memory into a multi-object manipulation reasoning and planning framework. We propose DOOM and LOOM, which leverage transformer relational dynamics to encode the history of trajectories given partial-view point clouds and an object discovery and tracking engine. Our approaches can perform multiple challenging tasks including reasoning with occluded objects, novel objects appearance, and object reappearance. Throughout our extensive simulation and real world experiments, we find that our approaches perform well in terms of different numbers of objects and different numbers
“Open Sourse Underwater Robot: Easys,” by Michikuni Eguchi, Koki Kato, Tatsuya Oshima, and Shunya Hara from University of Tsukuba and Osaka University, Japan.
“Sensorized Soft Skin for Dexterous Robotic Hands,” by Jana Egli, Benedek Forrai, Thomas Buchner, Jiangtao Su, Xiaodong Chen, and Robert K. Katzschmann from ETH Zurich, Switzerland, and Nanyang Technological University, Singapore.
Conventional industrial robots often use two fingered grippers or suction cups to manipulate objects or interact with the world. Because of their simplified design, they are unable to reproduce the dexterity of human hands when manipulating a wide range of objects. While the control of humanoid hands evolved greatly, hardware platforms still lack capabilities, particularly in tactile sensing and providing soft contact surfaces. In this work, we present a method that equips the skeleton of a tendon-driven humanoid hand with a soft and sensorized tactile skin. Multi-material 3D printing allows us to iteratively approach a cast skin design which preserves the robot’s dexterity in terms of range of motion and speed. We demonstrate that a soft skin enables frmer grasps and piezoresistive sensor integration enhances the hand’s tactile sensing capabilities.
-
Credentialing Adds Value to Training Programs
by Christine Cherevko on 16. May 2024. at 18:00

With careers in engineering and technology evolving so rapidly, a company’s commitment to upskilling its employees is imperative to their career growth. Maintaining the appropriate credentials—such as a certificate or digital badge that attests to successful completion of a specific set of learning objectives—can lead to increased job satisfaction, employee engagement, and higher salaries.
For many engineers, completing a certain number of professional development hours and continuing-education units each year is required to maintain a professional engineering license.
Many companies have found that offering training and credentialing opportunities helps them stay competitive in today’s job marketplace. The programs encourage promotion from within—which helps reduce turnover and costly recruiting expenses for organizations. Employees with a variety of credentials are more engaged in industry-related initiatives and are more likely to take on leadership roles than their noncredentialed counterparts. Technical training programs also give employees the opportunity to enhance their technical skills and demonstrate their willingness to learn new ones.
One way to strengthen and elevate in-house technical training is through the IEEE Credentialing Program. A credential is an assurance of quality education obtained for employers and a source of pride for learners because they can share that their credentials have been verified by the world’s largest technical professional organization.
In addition to supporting engineering professionals in achieving their career goals, the certificates and digital badges available through the program help companies enhance the credibility of their training events, conferences, and courses. Also, most countries accept IEEE certificates towards their domestic continuing-education requirements for engineers.
Start earning your certificates and digital badges with these IEEE courses. Learn how your organization can offer credentials for your courses here.
This article was updated from an earlier version on 20 May.
-
High-Speed Rail Finally Coming to the U.S.
by Willie D. Jones on 16. May 2024. at 13:11

In late April, the Miami-based rail company Brightline Trains broke ground on a project that the company promises will give the United States its first dedicated, high-speed passenger rail service. The 350-kilometer (218-mile) corridor, which the company calls Brightline West, will connect Las Vegas to the suburbs of Los Angeles. Brightline says it hopes to complete the project in time for the 2028 Summer Olympic Games, which will take place in Los Angeles.
Brightline has chosen Siemens American Pioneer 220 engines that will run at speeds averaging 165 kilometers per hour, with an advertised top speed of 320 km/h. That average speed still falls short of the Eurostar network connecting London, Paris, Brussels, and Amsterdam (300 km/h), Germany’s Intercity-Express 3 service (330 km/h), and the world’s fastest train service, China’s Beijing-to-Shanghai regional G trains (350 km/h).
There are currently only two rail lines in the U.S. that ever reach the 200 km/h mark, which is the unofficial minimum speed at which a train can be considered to be high-speed rail. Brightline, the company that is about to construct the L.A.-to-Las-Vegas Brightline West line, also operates a Miami-Orlando rail line that averages 111 km/h. The other is Amtrak’s Acela line between Boston and Washington, D.C.—and that line only qualifies as high-speed rail for just 80 km of its 735-km route. That’s a consequence of the rail status quo in the United States, in which slower freight trains typically have right of way on shared rail infrastructure.
As Vaclav Smil, professor emeritus at the University of Manitoba, noted in IEEE Spectrum in 2018, there has long been hope that the United States would catch up with Europe, China, and Japan, where high-speed regional rail travel has long been a regular fixture. “In a rational world, one that valued convenience, time, low energy intensity and low carbon conversions, the high-speed electric train would always be the first choice for [intercity travel],” Smil wrote at the time. And yet, in the United States, funding and regulatory approval for such projects have been in short supply.
Now, Brightline West, as well as a few preexisting rail projects that are at some stage of development, such as the California High-Speed Rail Network and the Texas Central Line, could be a bellwether for an attitude shift that could—belatedly—put trains closer to equal footing with cars and planes for travelers in the continental United States.
The U.S. government, like many national governments, has pledged to reduce greenhouse gas emissions. Because that generally requires decarbonizing transportation and improving energy efficiency, trains, which can run on electricity generated from fossil-fuel as well as non-fossil-fuel sources, are getting a big push. As Smil noted in 2018, trains use a fraction of a megajoule of energy per passenger-kilometer, while a lone driver in even one of the most efficient gasoline-powered cars will use orders of magnitude more energy per passenger-kilometer.
Brightline and Siemens did not respond to inquiries by Spectrum seeking to find out what innovations they plan to introduce that would make the L.A.-to-Las Vegas passenger line run faster or perhaps use less energy than its Asian and European counterparts. But Karen E. Philbrick, executive director of the Mineta Transportation Institute at San Jose State University, in California, says that’s beside the point. She notes that the United States, having focused on cars for the better part of the past century, already missed the period when major innovations were being made in high-speed rail. “What’s important about Brightline West and, say, the California High-speed Rail project, is not how innovative they are, but the fact that they’re happening at all. I am thrilled to see the U.S. catching up.”
Maybe Brightline or other groups seeking to get Americans off the roadways and onto railways will be able to seize the moment and create high-speed rail lines connecting other intraregional population centers in the United States. With enough of those pieces in place, it might someday be possible to ride the rails from California to New York in a single day, in the same way train passengers in China can get from Beijing to Shanghai between breakfast and lunch.
-
Never Recharge Your Consumer Electronics Again?
by Stephen Cass on 15. May 2024. at 16:25

Stephen Cass: Hello and welcome to Fixing the Future, an IEEE Spectrum podcast where we look at concrete solutions to tough problems. I’m your host Stephen Cass, a senior editor at IEEE Spectrum. And before I start, I just wanted to tell you that you can get the latest coverage of Spectrum‘s most important beats, including AI, climate change, and robotics, by signing up for one of our free newsletters. Just go to spectrum.ieee.org/newsletters to subscribe.
We all love our mobile devices where the progress of Moore’s Law has meant we’re able to pack an enormous amount of computing power in something that’s small enough that we can wear it as jewelery. But their Achilles heel is power. They eat up battery life requiring frequent battery changes or charging. One company that’s hoping to reduce our battery anxiety is Exeger, which wants to enable self-charging devices that convert ambient light into energy on the go. Here to talk about its so-called Powerfoyle solar cell technology is Exeger’s founder and CEO, Giovanni Fili. Giovanni, welcome to the show.
Giovanni Fili: Thank you.
Cass: So before we get into the details of the Powerfoyle technology, was I right in saying that the Achilles heel of our mobile devices is battery life? And if we could reduce or eliminate that problem, how would that actually influence the development of mobile and wearable tech beyond just not having to recharge as often?
Fili: Yeah. I mean, for sure, I think the global common problem or pain point is for sure battery anxiety in different ways, ranging from your mobile phone to your other portable devices, and of course, even EV like cars and all that. So what we’re doing is we’re trying to eliminate this or reduce or eliminate this battery anxiety by integrating— seamlessly integrating, I should say, a solar cell. So our solar cell can convert any light energy to electrical energy. So indoor, outdoor from any angle. We’re not angle dependent. And the solar cell can take the shape. It can look like leather, textile, brushed steel, wood, carbon fiber, almost anything, and can take light from all angles as well, and can be in different colors. It’s also very durable. So our idea is to integrate this flexible, thin film into any device and allow it to be self-powered, allowing for increased functionality in the device. Just look at the smartwatches. I mean, the first one that came, you could wear them for a few hours, and you had to charge them. And they packed them with more functionality. You still have to charge them every day. And you still have to charge them every day, regardless. But now, they’re packed with even more stuff. So as soon as you get more energy efficiency, you pack them with more functionality. So we’re enabling this sort of jump in functionality without compromising design, battery, sustainability, all of that. So yeah, so it’s been a long journey since I started working with this 17 years ago.
Cass: I actually wanted to ask about that. So how is Exeger positioned to attack this problem? Because it’s not like you’re the first company to try and do nice mobile charging solutions for mobile devices.
Fili: I can mention there, I think that the main thing that differentiates us from all other previous solutions is that we have invented a new electrode material, the anode and the cathode with a similar almost like battery. So we have anode, cathode. We have electrolytes inside. So this is a—
Cass: So just for readers who might not be familiar, a battery is basically you have an anode, which is the positive terminal—I hope I didn’t forgot that—cathode, which is a negative terminal, and then you have an electrolyte between them in the battery, and then chemical reactions between these three components, and it can get kind of complicated, produce an electric potential between one side and the other. And in a solar cell, also there’s an anode and a cathode and so on. Have I got that right, my little, brief sketch?
Fili: Yeah. Yeah. Yeah. And so what we add to that architecture is we add one layer of titanium dioxide nanoparticles. Titanium dioxide is the white in white wall paint, toothpaste, sunscreen, all that. And it’s a very safe and abundant material. And we use that porous layer of titanium nanoparticles. And then we deposit a dye, a color, a pigment on this layer. And this dye can be red, black, blue, green, any kind of color. And the dye will then absorb the photons, excite electrons that are injected into the titanium dioxide layer and then collected by the anode and then conducted out to the cable. And now, we use the electrons to light the lamp or a motor or whatever we do with it. And then they turn back to the cathode on the other side and inside the cell. So the electrons goes the other way and the inner way. So the plus, you can say, go inside ions in the electrolytes. So it’s a regenerative system.
So our innovation is a new— I mean, all solar cells, they have electrodes to collect the electrons. If you have silicon wafers or whatever you have, right? And you know that all these solar cells that you’ve seen, they have silver lines crossing the surface. The silver lines are there because the conductivity is quite poor, funny enough, in these materials. So high resistance. So then you need to deposit the silver lines there, and they’re called current collectors. So you need to collect the current. Our innovation is a new electrode material that has 1,000 times better conductivity than other flexible electrode materials. That allows us as the only company in the world to eliminate the silver lines. And we print all our layers as well. And as you print in your house, you can print a photo, an apple with a bite in it, you can print the name, you can print anything you want. We can print anything we want, and it will also be converting light energy to electric energy. So a solar cell.
Cass: So the key part is that the color dye is doing that initial work of converting the light. Do different colors affect the efficiency? I did see on your site that it comes in all these kind of different colors, but. And I was thinking to myself, well, is the black one the best? Is the red one the best? Or is it relatively insensitive to the visible color that I see when I look at these dyes?
Fili: So you’re completely right there. So black would give you the most. And if you go to different colors, typically you lose like 20, 30 percent. But fortunately enough for us, over 50 percent of the consumer electronic market is black products. So that’s good. So I think that you asked me how we’re positioned. I mean, with our totally unique integration possibilities, imagine this super thin, flexible film that works all day, every day from morning to sunset, indoor, outdoor, can look like leather. So we’ve made like a leather bag, right? The leather bag is the solar cell. The entire bag is the solar cell. You wouldn’t see it. It just looks like a normal leather bag.
Cass: So when you talk about flexible, you actually mean this— so sometimes when people talk about flexible electronics, they mean it can be put into a shape, but then you’re not supposed to bend it afterwards. When you’re talking about flexible electronics, you’re talking about the entire thing remains flexible and you can use it flexibly instead of just you can conform it once to a shape and then you kind of leave it alone.
Fili: Correct. So we just recently released a hearing protector with 3M. This great American company with more than 60,000 products across the world. So we have a global exclusivity contract with them where they have integrated our bendable, flexible solar film in the headband. So the headband is the solar cell, right? And where you previously had to change disposable battery every second week, two batteries every second week, now you never need to change the battery again. We just recharge this small rechargeable battery indoor and outdoor, just continues to charge all the time. And they have added a lot of extra really cool new functionality as well. So we’re eliminating the need for disposable batteries. We’re saving millions and millions of batteries. We’re saving the end user, the contractor, the guy who uses them a lot of hassle to buy this battery, store them. And we increase reliability and functionality because they will always be charged. You can trust them that they always work. So that’s where we are totally unique. The solar cell is super durable. If we can be in a professional hearing protector to use on airports, construction sites, mines, whatever you use, factories, oil rig platforms, you can do almost anything. So I don’t think any other solar cell would be able to pass those durability tests that we did. It’s crazy.
Cass: So I have a question. It kind of it’s more appropriate from my experience with utility solar cells and things you put on roofs. But how many watts per square meter can you deliver, we’ll say, in direct sunlight?
Fili: So our focus is on indirect sunlight, like shade, suboptimal light conditions, because that’s where you would typically be with these products. But if you compare to more of a silicon, which is what you typically use for calculators and all that stuff. So we are probably around twice as what they deliver in this dark conditions, two to three times, depending. If you use glass, if you use flexible, we’re probably three times even more, but. So we don’t do full sunshine utility scale solar. But if you look at these products like the hearing protector, we have done a lot of headphones with Adidas and other huge brands, we typically recharge like four times what they use. So if you look at— if you go outside, not in full sunshine, but half sunshine, let’s say 50,000 lux, you’re probably talking at about 13, 14 minutes to charge one hour of listening. So yeah, so we have sold a few hundred thousand products over the last three years when we started selling commercially. And - I don’t know - I haven’t heard anyone who has charged since. I mean, surely someone has, but typically the user never need to charge them again, just charge themself.
Cass: Well, that’s right, because for many years, I went to CES, and I often would buy these, or acquire these, little solar cell chargers. And it was such a disappointing experience because they really would only work in direct sunlight. And even then, it would take a very long time. So I want to talk a little bit about, then, to get to that, what were some of the biggest challenges you had to overcome on the way to developing this tech?
Fili: I mean, this is the fourth commercial solar cell technology in the world after 110 or something years of research. I mean, the Americans, the Bell Laboratory sent the first silicon cell, I think it’s in like 1955 or something, to space. And then there’s been this constant development and trying to find, but to develop a new energy source is as close to impossible as you get, more or less. Everybody tried and everybody failed. We didn’t know that, luckily enough. So just the whole-- so when I try to explain this, I get this question quite a lot. Imagine you found out something really cool, but there’s no one to ask. There’s no book to read. You just realize, “Okay, I have to make like hundreds of thousands, maybe millions of experiments to learn. And all of them, except finally one, they will all fail. But that’s okay.” You will fail, fail, fail. And then, “Oh, here’s the solution. Something that works. Okay. Good.” So we had to build on just constant failing, but it’s okay because you’re in a research phase. So we had to. I mean, we started off with this new nanomaterials, and then we had to make components of these materials. And then we had to make solar cells of the components, but there were no machines either. We have had to invent all the machines from scratch as well to make these components and the solar cells and some of the non-materials. That was also tough. How do you design a machine for something that doesn’t exist? It’s pretty difficult specification to give to a machine builder. So in the end, we had to build our own machine building capacity here. We’re like 50 guys building machines, so.
But now, I mean, today we have over 300 granted patents, another 90 that will be approved soon. We have a complete machine park that’s proprietary. We are now building the largest solar cell factory— one of the largest solar cell factories in Europe. It’s already operational, phase one. Now we’re expanding into phase two. And we’re completely vertically integrated. We don’t source anything from Russia, China; never did. Only US, Japan, and Europe. We run the factories on 100 percent renewable energy. We have zero emissions to air and water. And we don’t have any rare earth metals, no strange stuff in it. It’s like it all worked out. And now we have signed, like I said, global exclusivity deal with 3M. We have a global exclusivity deal with the largest company in the world on computer peripherals, like mouse, keyboard, that stuff. They can only work with us for years. We have signed one of the large, the big fives, the Americans, the huge CE company. Can’t tell you yet the name. We have a globally exclusive deal for electronic shelf labels, the small price tags in the stores. So we have a global solution with Vision Group, that’s the largest. They have 50 percent of the world market as well. And they have Walmart, IKEA, Target, all these huge companies. So now it’s happening. So we’re rolling out, starting to deploy massive volumes later this year.
Cass:So I’ll talk a little bit about that commercial experience because you talked about you had to create verticals. I mean, in Spectrum, we do cover other startups which have had these— they’re kind of starting from scratch. And they develop a technology, and it’s a great demo technology. But then it comes that point where you’re trying to integrate in as a supplier or as a technology partner with a large commercial entity, which has very specific ideas and how things are to be manufactured and delivered and so on. So can you talk a little bit about what it was like adapting to these partners like 3M and what changes you had to make and what things you learned in that process where you go from, “Okay, we have a great product and we could make our own small products, but we want to now connect in as part of this larger supply chain.”
Fili: It’s a very good question and it’s extremely tough. It’s a tough journey, right? Like to your point, these are the largest companies in the world. They have their way. And one of the first really tough lessons that we learned was that one factory wasn’t enough. We had to build two factories to have redundancy in manufacturing. Because single source is bad. Single source, single factory, that’s really bad. So we had to build two factories and we had to show them we were ready, willing and able to be a supplier to them. Because one thing is the product, right? But the second thing is, are you worthy supplier? And that means how much money you have in the bank. Are you going to be here in two, three, four years? What’s your ISO certifications like? REACH, RoHS, Prop 65. What’s your LCA? What’s your view on this? Blah, blah, blah. Do you have professional supply chain? Did you do audits on your suppliers? But now, I mean, we’ve had audits here by five of the largest companies in the world. We’ve all passed them. And so then you qualify as a worthy supplier. Then comes your product integration work, like you mentioned. And I think it’s a lot about— I mean, that’s our main feature. The main unique selling point with Exeger is that we can integrate into other people’s products. Because when you develop this kind of crazy technology-- “Okay, so this is solar cell. Wow. Okay.” And it can look like anything. And it works all the time. And all the other stuff is sustainable and all that. Which product do you go for? So I asked myself—I’m an entrepreneur since the age of 15. I’ve started a number of companies. I lost so much money. I can’t believe it. And managed to earn a little bit more. But I realized, “Okay, how do you select? Where do you start? Which product?”
Okay, so I sat down. I was like, “When does it sell well? When do you see market success?” When something is important. When something is important, it’s going to work. It’s not the best tech. It has to be important enough. And then, you need distribution and scale and all that. Okay, how do you know if something is important? You can’t. Okay. What if you take something that’s already is— I mean, something new, you can’t know if it’s going to work. But if we can integrate into something that’s already selling in the billions of units per year, like headphones— I think this year, one billion headphones are going to be sold or something. Okay, apparently, obviously that’s important for people. Okay, let’s develop technology that can be integrated into something that’s already important and allow it to stay, keep all the good stuff, the design, the weight, the thickness, all of that, even improve the LCA better for the environment. And it’s self-powered. And it will allow the user to participate and help a little bit to a better world, right? With no charge cable, no charging in the wall, less batteries and all that. So our strategy was to develop such a strong technology so that we could integrate into these companies/partners products.
Cass: So I guess the question there is— so you come to a company, the company has its own internal development engineers. It’s got its own people coming up with product ideas and so on. How do you evangelize within a company to say, “Look, you get in the door, you show your demo,” to say, product manager who’s thinking of new product lines, “You guys should think about making products with our technology.” How do you evangelize that they think, “Okay, yeah, I’m going to spend the next six months of my life betting on these headphones, on this technology that I didn’t invent that I’m kind of trusting.” How do you get that internal buy-in with the internal engineers and the internal product developers and product managers?
Fili: That’s the Holy Grail, right? It’s very, very, very difficult. Takes a lot of time. It’s very expensive. And the point, I think you’re touching a little bit when you’re asking me now, because they don’t have a guy waiting to buy or a division or department waiting to buy this flexible indoor solar cell that can look like leather. They don’t have anyone. Who’s going to buy? Who’s the decision maker? There is not one. There’s a bunch, right? Because this will affect the battery people. This will affect the antenna people. This will affect the branding people. It will affect the mechanic people, etc., etc., etc. So there’s so many people that can say no. No one can say yes alone. All of them can say no alone. Any one of them can block the project, but to proceed, all of them have to say yes. So it’s a very, very tough equation. So that’s why when we realized this— this was another big learning that we had that we couldn’t go with the sales guy. We couldn’t go with two sales guys. We had to go with an entire team. So we needed to bring our design guy, our branding person, our mechanics person, our software engineer. We had to go like huge teams to be able to answer all the questions and mitigate and explain.
So we had to go both top down and explain to the head of product or head of sustainability, “Okay, if you have 100 million products out in five years and they’re going to be using 50 batteries per year, that’s 5 billion batteries per year. That’s not good, right? What if we can eliminate all these batteries? That’s good for sustainability.” “Okay. Good.” “That’s also good for total cost. We can lower total cost of ownership.” “Okay, that’s also good.” “And you can sell this and this and this way. And by the way, here’s a narrative we offer you. We have also made some assets, movies, pictures, texts. This is how other people talk about this.” But it’s a very, very tough start. How do you get the first big name in? And big companies, they have a lot to risk, a lot to lose as well. So my advice would be to start smaller. I mean, we started mainly due to COVID, to be honest. Because Sweden stayed open during COVID, which was great. We lived our lives almost like normal. But we couldn’t work with any international companies because they were all closed or no one went to the office. So we had to turn to Swedish companies, and we developed a few products during COVID. We launched like four or five products on the market with smaller Swedish companies, and we launched so much. And then we could just send these headphones to the large companies and tell them, “You know what? Here’s a headphone. Use it for a few months. We’ll call you later.” And then they call us that, “You know what? We have used them for three months. No one has charged. This is sick. It actually works.” We’re like, “Yeah, we know.” And then that just made it so much easier. And now anyone who wants to make a deal with us, they can just buy these products anywhere online or in-store across the whole world and try them for themselves.
And we send them also samples. They can buy, they can order from our website, like development kits. We have software, we have partnered up with Qualcomm, early semiconductor. All the big electronics companies, we’re now qualified partners with them. So all the electronics is powerful already. So now it’s very easy now to build prototypes if you want to test something. We have offices across the world. So now it’s much easier. But my advice to anyone who would want to start with this is try and get a few customers in. The important thing is that they also care about the project. If we go to one of these large companies, 3M, they have 60,000 products. If they have 60,001, yeah. But for us, it’s like the project. And we have managed to land it in a way. So it’s also important for them now because it just touches so many of their important areas that they work with, so.
Cass: So in terms of future directions for the technology, do you have a development pathway? What kind of future milestones are you hoping to hit?
Fili: For sure. So at the moment, we’re focusing on consumer electronics market, IoT, smart home. So I think the next big thing will be the smart workplace where you see huge construction sites and other areas where we connect the workers, anything from the smart helmet. You get hit in your head, how hard was it? I mean, why can’t we tell you that? That’s just ridiculous. There’s all these sensors already available. Someone just needs to power the helmet. Location services. Is the right person in the right place with the proper training or not? On the construction side, do you have the training to work with dynamite, for example, or heavy lifts or different stuff? So you can add the geofencing in different sites. You can add health data, digital health tracking, pulse, breathing, temperature, different stuff. Compliance, of course. Are you following all the rules? Are you wearing your helmet? Is the helmet buttoned? Are you wearing the proper other gear, whatever it is? Otherwise, you can’t start your engine, or you can’t go into this site, or you can’t whatever. I think that’s going to greatly improve the proactive safety and health a lot and increase profits for employers a lot too at the same time. In a few years, I think we’re going to see the American unions are going to be our best sales force. Because when they see the greatness of this whole system, they’re going to demand it in all tenders, all biggest projects. They’re going to say, “Hey, we want to have the connected worker safety stuff here.” Because you can just stream-- if you’re working, you can stream music, talk to your colleagues, enjoy connected safety without invading the privacy, knowing that you’re good. If you fall over, if you faint, if you get a heart attack, whatever, in a few seconds, the right people will know and they will take their appropriate actions. It’s just really, really cool, this stuff.
Cass: Well, it’ll be interesting to see how that turns out. But I’m afraid that’s all we have time for today, although this is fascinating. But today, so Giovanni, I want to thank you very much for coming on the show.
Fili: Thank you so much for having me.
Cass: So today we were talking with Giovanni Fili, who is Exeger’s founder and CEO, about their new flexible powerfoyle solar cell technology. For IEEE Spectrum‘s Fixing the Future, I’m Stephen Cass, and I hope you’ll join me next time.
-
How to Put a Data Center in a Shoebox
by Anna Herr on 15. May 2024. at 15:00

Scientists have predicted that by 2040, almost 50 percent of the world’s electric power will be used in computing. What’s more, this projection was made before the sudden explosion of generative AI. The amount of computing resources used to train the largest AI models has been doubling roughly every 6 months for more than the past decade. At this rate, by 2030 training a single artificial-intelligence model would take one hundred times as much computing resources as the combined annual resources of the current top ten supercomputers. Simply put, computing will require colossal amounts of power, soon exceeding what our planet can provide.
One way to manage the unsustainable energy requirements of the computing sector is to fundamentally change the way we compute. Superconductors could let us do just that.
Superconductors offer the possibility of drastically lowering energy consumption because they do not dissipate energy when passing current. True, superconductors work only at cryogenic temperatures, requiring some cooling overhead. But in exchange, they offer virtually zero-resistance interconnects, digital logic built on ultrashort pulses that require minimal energy, and the capacity for incredible computing density due to easy 3D chip stacking.
Are the advantages enough to overcome the cost of cryogenic cooling? Our work suggests they most certainly are. As the scale of computing resources gets larger, the marginal cost of the cooling overhead gets smaller. Our research shows that starting at around 10 16 floating-point operations per second (tens of petaflops) the superconducting computer handily becomes more power efficient than its classical cousin. This is exactly the scale of typical high-performance computers today, so the time for a superconducting supercomputer is now.
At Imec, we have spent the past two years developing superconducting processing units that can be manufactured using standard CMOS tools. A processor based on this work would be one hundred times as energy efficient as the most efficient chips today, and it would lead to a computer that fits a data-center’s worth of computing resources into a system the size of a shoebox.
The Physics of Energy-Efficient Computation
Superconductivity—that superpower that allows certain materials to transmit electricity without resistance at low enough temperatures—was discovered back in 1911, and the idea of using it for computing has been around since the mid-1950s. But despite the promise of lower power usage and higher compute density, the technology couldn’t compete with the astounding advance of CMOS scaling under Moore’s Law. Research has continued through the decades, with a superconducting CPU demonstrated by a group at Yokohama National University as recently as 2020. However, as an aid to computing, superconductivity has stayed largely confined to the laboratory.
To bring this technology out of the lab and toward a scalable design that stands a chance of being competitive in the real world, we had to change our approach here at Imec. Instead of inventing a system from the bottom up—that is, starting with what works in a physics lab and hoping it is useful—we designed it from the top down—starting with the necessary functionality, and working directly with CMOS engineers and a full-stack development team to ensure manufacturability. The team worked not only on a fabrication process, but also software architectures, logic gates, and standard-cell libraries of logic and memory elements to build a complete technology.
The foundational ideas behind energy-efficient computation, however, have been developed as far back as 1991. In conventional processors, much of the power consumed and heat dissipated comes from moving information among logic units, or between logic and memory elements rather than from actual operations. Interconnects made of superconducting material, however, do not dissipate any energy. The wires have zero electrical resistance, and therefore, little energy is required to move bits within the processor. This property of having extremely low energy losses holds true even at very high communication frequencies, where losses would skyrocket ordinary interconnects.
Further energy savings come from the way logic is done inside the superconducting computer. Instead of the transistor, the basic element in superconducting logic is the Josephson-junction.
A Josephson junction is a sandwich—a thin slice of insulating material squeezed between two superconductors. Connect the two superconductors, and you have yourself a Josephson-junction loop.
Under normal conditions, the insulating “meat” in the sandwich is so thin that it does not deter a supercurrent—the whole sandwich just acts as a superconductor. However, if you ramp up the current past a threshold known as a critical current, the superconducting “bread slices” around the insulator get briefly knocked out of their superconducting state. In this transition period, the junction emits a tiny voltage pulse, lasting just a picosecond and dissipating just 2 x 10 -20 joules, a hundred-billionth of what it takes to write a single bit of information into conventional flash memory.
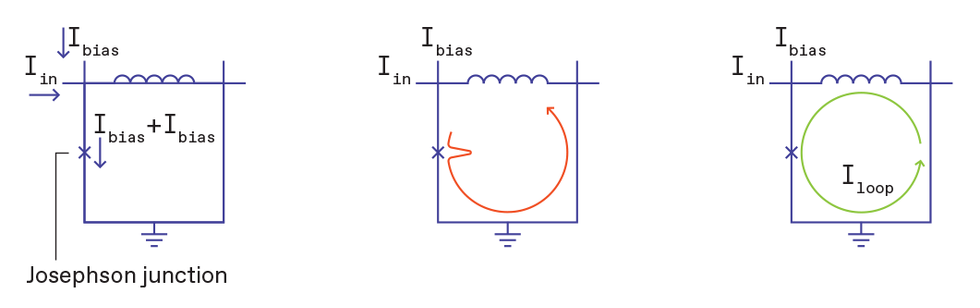 A single flux quantum develops in a Josephson-junction loop via a three-step process. First, a current just above the critical value is passed through the junction. The junction then emits a single-flux-quantum voltage pulse. The voltage pulse passes through the inductor, creating a persistent current in the loop. A Josephson junction is indicated by an x on circuit diagrams. Chris Philpot
A single flux quantum develops in a Josephson-junction loop via a three-step process. First, a current just above the critical value is passed through the junction. The junction then emits a single-flux-quantum voltage pulse. The voltage pulse passes through the inductor, creating a persistent current in the loop. A Josephson junction is indicated by an x on circuit diagrams. Chris Philpot
The key is that, due to a phenomenon called magnetic flux quantization in the superconducting loop, this pulse is always exactly the same. It is known as a “single flux quantum” (SFQ) of magnetic flux, and it is fixed to have a value of 2.07 millivolt-picoseconds. Put an inductor inside the Josephson-junction loop, and the voltage pulse drives a current. Since the loop is superconducting, this current will continue going around the loop indefinitely, without using any further energy.
Logical operations inside the superconducting computer are made by manipulating these tiny, quantized voltage pulses. A Josephson-junction loop with an SFQ’s worth of persistent current acts as a logical 1, while a current-free loop is a logical 0.
To store information, the Josephson-junction-based version of SRAM in CPU cache, also uses single flux quanta. To store one bit, two Josephson-junction loops need to be placed next to each other. An SFQ with a persistent current in the left-hand loop is a memory element storing a logical 0, whereas no current in the left but a current in the right loop is a logical 1.
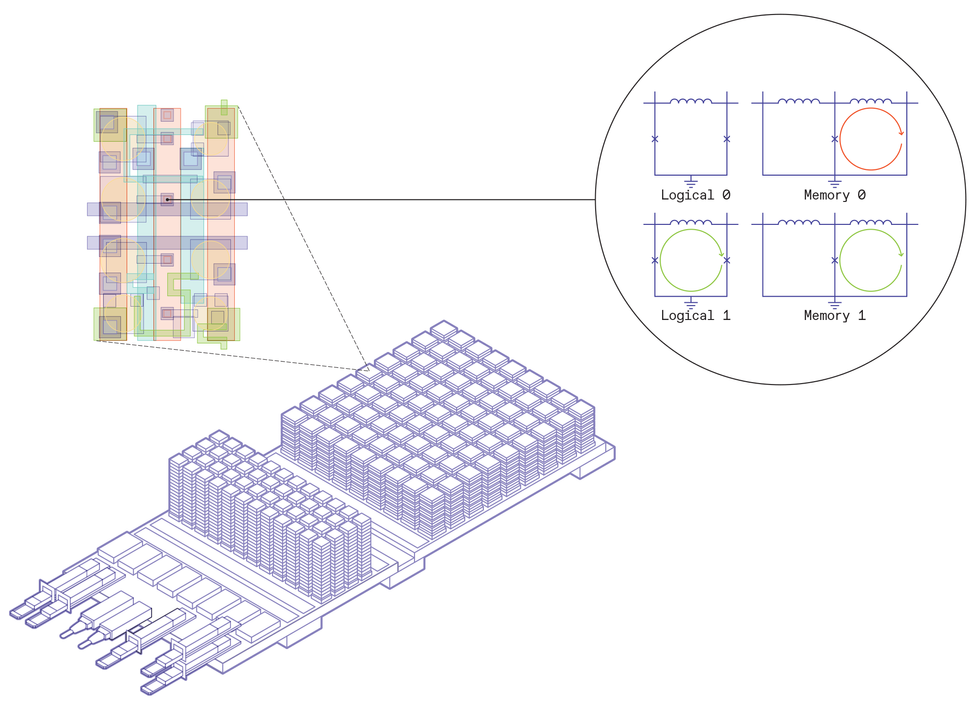 Designing a superconductor-based data center required full-stack innovation. Imec’s board design contains three main elements: the input and output, leading data to the room temperature world, the conventional DRAM, stacked high and cooled to 77 kelvins, and the superconducting processing units, also stacked, and cooled to 4 K. Inside the superconducting processing unit, basic logic and memory elements are laid out to perform computations. A magnification of the chip shows the basic building blocks: For logic, a Josephson-junction loop without a persistent current indicates a logical 0, while a loop with one single flux quantum’s worth of current represents a logical 1. For memory, two Josephson junction loops are connected together. An SFQ’s worth of persistent current in the left loop is a memory 0, and a current in the right loop is a memory 1. Chris Philpot
Designing a superconductor-based data center required full-stack innovation. Imec’s board design contains three main elements: the input and output, leading data to the room temperature world, the conventional DRAM, stacked high and cooled to 77 kelvins, and the superconducting processing units, also stacked, and cooled to 4 K. Inside the superconducting processing unit, basic logic and memory elements are laid out to perform computations. A magnification of the chip shows the basic building blocks: For logic, a Josephson-junction loop without a persistent current indicates a logical 0, while a loop with one single flux quantum’s worth of current represents a logical 1. For memory, two Josephson junction loops are connected together. An SFQ’s worth of persistent current in the left loop is a memory 0, and a current in the right loop is a memory 1. Chris Philpot
Progress Through Full-Stack Development
To go from a lab curiosity to a chip prototype ready for fabrication, we had to innovate the full stack of hardware. This came in three main layers: engineering the basic materials used, circuit development, and architectural design. The three layers had to go together—a new set of materials requires new circuit designs, and new circuit designs require novel architectures to incorporate them. Codevelopment across all three stages, with a strict adherence to CMOS manufacturing capabilities, was the key to success.
At the materials level, we had to step away from the previous lab-favorite superconducting material: niobium. While niobium is easy to model and behaves very well under predictable lab conditions, it is very difficult to scale down. Niobium is sensitive to both process temperature and its surrounding materials, so it is not compatible with standard CMOS processing. Therefore, we switched to the related compound niobium titanium nitride for our basic superconducting material. Niobium titanium nitride can withstand temperatures used in CMOS fabrication without losing its superconducting capabilities, and it reacts much less with its surrounding layers, making it a much more practical choice.
 The basic building block of superconducting logic and memory is the Josephson junction. At Imec, these junctions have been manufactured using a new set of materials, allowing the team to scale down the technology without losing functionality. Here, a tunneling electron microscope image shows a Josephson junction made with alpha-silicon insulator sandwiched between niobium titanium nitride superconductors, achieving a critical dimension of 210 nanometers. Imec
The basic building block of superconducting logic and memory is the Josephson junction. At Imec, these junctions have been manufactured using a new set of materials, allowing the team to scale down the technology without losing functionality. Here, a tunneling electron microscope image shows a Josephson junction made with alpha-silicon insulator sandwiched between niobium titanium nitride superconductors, achieving a critical dimension of 210 nanometers. Imec
Additionally, we employed a new material for the meat layer of the Josephson-junction sandwich—amorphous, or alpha, silicon. Conventional Josephson-junction materials, most notably aluminum oxide, didn’t scale down well. Aluminum was used because it “wets” the niobium, smoothing the surface, and the oxide was grown in a well-controlled manner. However, to get to the ultrahigh densities that we are targeting, we would have to make the oxide too thin to be practically manufacturable. Alpha silicon, in contrast, allowed us to use a much thicker barrier for the same critical current.
We also had to devise a new way to power the Josephson junctions that would scale down to the size of a chip. Previously, lab-based superconducting computers used transformers to deliver current to their circuit elements. However, having a bulky transformer near each circuit element is unworkable. Instead, we designed a way to deliver power to all the elements on the chip at once by creating a resonant circuit, with specialized capacitors interspersed throughout the chip.
At the circuit level, we had to redesign the entire logic and memory structure to take advantage of the new materials’ capabilities. We designed a novel logic architecture that we call pulse-conserving logic. The key requirement for pulse-conserving logic is that the elements have as many inputs as outputs and that the total number of single flux quanta is conserved. The logic is performed by routing the SFQs through a combination of Josephson-junction loops and inductors to the appropriate outputs, resulting in logical ORs and ANDs. To complement the logic architecture, we also redesigned a compatible Josephson-junction-based SRAM.
Lastly, we had to make architectural innovations to take full advantage of the novel materials and circuit designs. Among these was cooling conventional silicon DRAM down to 77 kelvins and designing a glass bridge between the 77-K section and the main superconducting section. The bridge houses thin wires that allow communication without thermal mixing. We also came up with a way of stacking chips on top of each other and are developing vertical superconducting interconnects to link between circuit boards.
A Data Center the Size of a Shoebox
The result is a superconductor-based chip design that’s optimized for AI processing. A zoom in on one of its boards reveals many similarities with a typical 3D CMOS system-on-chip. The board is populated by computational chips: We call it a superconductor processing unit (SPU), with embedded superconducting SRAM, DRAM memory stacks, and switches, all interconnected on silicon interposer or on glass-bridge advanced packaging technologies.
But there are also some striking differences. First, most of the chip is to be submerged in liquid helium for cooling to a mere 4 K. This includes the SPUs and SRAM, which depend on superconducting logic rather than CMOS, and are housed on an interposer board. Next, there is a glass bridge to a warmer area, a balmy 77 K that hosts the DRAM. The DRAM technology is not superconducting, but conventional silicon cooled down from room temperature, making it more efficient. From there, bespoke connectors lead data to and from the room-temperature world.
 Davide Comai
Davide Comai
Moore’s law relies on fitting progressively more computing resources into the same space. As scaling down transistors gets more and more difficult, the semiconductor industry is turning toward 3D stacking of chips to keep up the density gains. In classical CMOS-based technology, it is very challenging to stack computational chips on top of each other because of the large amount of power, and therefore heat, that is dissipated within the chips. In superconducting technology, the little power that is dissipated is easily removed by the liquid helium. Logic chips can be directly stacked using advanced 3D integration technologies resulting in shorter and faster connections between the chips, and a smaller footprint.
It is also straightforward to stack multiple boards of 3D superconducting chips on top of each other, leaving only a small space between them. We modeled a stack of 100 such boards, all operating within the same cooling environment and contained in a 20- by 20- by 12-centimeter volume, roughly the size of a shoebox. We calculated that this stack can perform 20 exaflops (in BF16 number format), 20 times the capacity of the largest supercomputer today. What’s more, the system promises to consume only 500 kilowatts of total power. This translates to energy efficiency one hundred times as high as the most efficient supercomputer today.
So far, we’ve scaled down Josephson junctions and interconnect dimensions over three succeeding generations. Going forward, Imec’s road map includes tackling 3D superconducting chip-integration and cooling technologies. For the first generation, the road map envisions the stacking of about 100 boards to obtain the target performance of 20 exaflops. Gradually, more and more logic chips will be stacked, and the number of boards will be reduced. This will further increase performance while reducing complexity and cost.
The Superconducting Vision
We don’t envision that superconducting digital technology will replace conventional CMOS computing, but we do expect it to complement CMOS for specific applications and fuel innovations in new ones. For one, this technology would integrate seamlessly with quantum computers that are also built upon superconducting technology. Perhaps more significantly, we believe it will support the growth in AI and machine learning processing and help provide cloud-based training of big AI models in a much more sustainable way than is currently possible.
In addition, with this technology we can engineer data centers with much smaller footprints. Drastically smaller data centers can be placed close to their target applications, rather than being in some far-off football-stadium-size facility.
Such transformative server technology is a dream for scientists. It opens doors to online training of AI models on real data that are part of an actively changing environment. Take potential robotic farms as an example. Today, training these would be a challenging task, where the required processing capabilities are available only in far-away, power-hungry data centers. With compact, nearby data centers, the data could be processed at once, allowing an AI to learn from current conditions on the farm
Similarly, these miniature data centers can be interspersed in energy grids, learning right away at each node and distributing electricity more efficiently throughout the world. Imagine smart cities, mobile health care systems, manufacturing, farming, and more, all benefiting from instant feedback from adjacent AI learners, optimizing and improving decision making in real time.
This article appears in the June 2024 print issue as “A Data Center in a Shoebox.”
-
This Member Gets a Charge from Promoting Sustainability
by Joanna Goodrich on 14. May 2024. at 18:00

Ever since she was an undergraduate student in Turkey, Simay Akar has been interested in renewable energy technology. As she progressed through her career after school, she chose not to develop the technology herself but to promote it. She has held marketing positions with major energy companies, and now she runs two startups.
One of Akar’s companies develops and manufactures lithium-ion batteries and recycles them. The other consults with businesses to help them achieve their sustainability goals.
Simay Akar
Employer
AK Energy Consulting
Title
CEO
Member grade
Senior member
Alma mater
Middle East Technical University in Ankara, Turkey
“I love the industry and the people in this business,” Akar says. “They are passionate about renewable energy and want their work to make a difference.”
Akar, a senior member, has become an active IEEE volunteer as well, holding leadership positions. First she served as student branch coordinator, then as a student chapter coordinator, and then as a member of several administrative bodies including the IEEE Young Professionals committee.
Akar received this year’s IEEE Theodore W. Hissey Outstanding Young Professional Award for her “leadership and inspiration of young professionals with significant contributions in the technical fields of photovoltaics and sustainable energy storage.” The award is sponsored by IEEE Young Professionals and the IEEE Photonics and Power & Energy societies.
Akar says she’s honored to get the award because “Theodore W. Hissey’s commitment to supporting young professionals across all of IEEE’s vast fields is truly commendable.” Hissey, who died in 2023, was an IEEE Life Fellow and IEEE director emeritus who supported the IEEE Young Professionals community for years.
“This award acknowledges the potential we hold to make a significant impact,” Akar says, “and it motivates me to keep pushing the boundaries in sustainable energy and inspire others to do the same.”
A career in sustainable technology
After graduating with a degree in the social impact of technology from Middle East Technical University, in Ankara, Turkey, Akar worked at several energy companies. Among them was Talesun Solar in Suzhou, China, where she was head of overseas marketing. She left to become the sales and marketing director for Eko Renewable Energy, in Istanbul.
In 2020 she founded Innoses in Shanghai. The company makes batteries for electric vehicles and customizes them for commercial, residential, and off-grid renewable energy systems such as solar panels. Additionally, Innoses recycles lithium-ion batteries, which otherwise end up in landfills, leaching hazardous chemicals.
“Recycling batteries helps cut down on pollution and greenhouse gas emissions,” Akar says. “That’s something we can all feel good about.”
She says there are two main methods of recycling batteries: melting and shredding.
Melting batteries is done by heating them until their parts separate. Valuable metals including cobalt and nickel are collected and cleaned to be reused in new batteries.
A shredding machine with high-speed rotating blades cuts batteries into small pieces. The different components are separated and treated with solutions to break them down further. Lithium, copper, and other metals are collected and cleaned to be reused.
The melting method tends to be better for collecting cobalt and nickel, while shredding is better for recovering lithium and copper, Akar says.
“This happens because each method focuses on different parts of the battery, so some metals are easier to extract depending on how they are processed,” she says. The chosen method depends on factors such as the composition of the batteries, the efficiency of the recycling process, and the desired metals to be recovered.
“There are a lot of environmental concerns related to battery usage,” Akar says. “But, if the right recycling process can be completed, batteries can also be sustainable. The right process could keep pollution and emissions low and protect the health of workers and surrounding communities.”
 Akar worked at several energy companies including Talesun Solar in Suzhou, China, which manufactures solar cells like the one she is holding.Simay Akar
Akar worked at several energy companies including Talesun Solar in Suzhou, China, which manufactures solar cells like the one she is holding.Simay AkarHelping businesses with sustainability
After noticing many businesses were struggling to become more sustainable, in 2021 Akar founded AK Energy Consulting in Istanbul. Through discussions with company leaders, she found they “need guidance and support from someone who understands not only sustainable technology but also the best way renewable energy can help the planet,” she says.
“My goal for the firm is simple: Be a force for change and create a future that’s sustainable and prosperous for everyone,” she says.
Akar and her staff meet with business leaders to better understand their sustainability goals. They identify areas where companies can improve, assess the impact the recommended changes can have, and research the latest sustainable technology. Her consulting firm also helps businesses understand how to meet government compliance regulations.
“By embracing sustainability, companies can create positive social, environmental, and economic impact while thriving in a rapidly changing world,” Akar says. “The best part of my job is seeing real change happen. Watching my clients switch to renewable energy, adopt eco-friendly practices, and hit their green goals is like a pat on the back.”
Serving on IEEE boards and committees
Akar has been a dedicated IEEE volunteer since joining the organization in 2007 as an undergraduate student and serving as chair of her school’s student branch. After graduating, she held other roles including Region 8 student branch coordinator, student chapter coordinator, and the region’s IEEE Women in Engineering committee chair.
In her nearly 20 years as a volunteer, Akar has been a member of several IEEE boards and committees including the Young Professionals committee, the Technical Activities Board, and the Nominations and Appointments Committee for top-level positions.
She is an active member of the IEEE Power & Energy Society and is a former IEEE PES liaison to the Women in Engineering committee. She is also a past vice chair of the society’s Women in Power group, which supports career advancement and education and provides networking opportunities.
“My volunteering experiences have helped me gain a deep understanding of how IEEE operates,” she says. “I’ve accumulated invaluable knowledge, and the work I’ve done has been incredibly fulfilling.”
As a member of the IEEE–Eta Kappa Nu honor society, Akar has mentored members of the next generation of technologists. She also served as a mentor in the IEEE Member and Geographic Activities Volunteer Leadership Training Program, which provides members with resources and an overview of IEEE, including its culture and mission. The program also offers participants training in management and leadership skills.
Akar says her experiences as an IEEE member have helped shape her career. When she transitioned from working as a marketer to being an entrepreneur, she joined IEEE Entrepreneurship, eventually serving as its vice chair of products. She also was chair of the Region 10 entrepreneurship committee.
“I had engineers I could talk to about emerging technologies and how to make a difference through Innoses,” she says. “I also received a lot of support from the group.”
Akar says she is committed to IEEE’s mission of advancing technology for humanity. She currently chairs the IEEE Humanitarian Technology Board’s best practices and projects committee. She also is chair of the IEEE MOVE global committee. The mobile outreach vehicle program provides communities affected by natural disasters with power and Internet access.
“Through my leadership,” Akar says, “I hope to contribute to the development of innovative solutions that improve the well-being of communities worldwide.”
-
Startup Sends Bluetooth Into Low Earth Orbit
by Margo Anderson on 13. May 2024. at 19:54

A recent Bluetooth connection between a device on Earth and a satellite in orbit signals a potential new space race—this time, for global location-tracking networks.
Seattle-based startup Hubble Network announced today that it had a letter of understanding with San Francisco-based startup Life360 to develop a global, satellite-based Internet of Things (IoT) tracking system. The announcement follows on the heels of a 29 April announcement from Hubble Network that it had established the first Bluetooth connection between a device on Earth and a satellite. The pair of announcements sets the stage for an IoT tracking system that aims to rival Apple’s AirTags, Samsung’s Galaxy SmartTag2, and the Cube GPS Tracker.
Bluetooth, the wireless technology that connects home speakers and earbuds to phones, typically traverses meters, not hundreds of kilometers (520 km, in the case of Hubble Network’s two orbiting satellites). The trick to extending the tech’s range, Hubble Network says, lies in the startup’s patented, high-sensitivity signal detection system on a LEO satellite.
“We believe this is comparable to when GPS was first made available for public use.” —Alex Haro, Hubble Network
The caveat, however, is that the connection is device-to-satellite only. The satellite can’t ping devices back on Earth to say “signal received,” for example. This is because location-tracking tags operate on tiny energy budgets—often powered by button-sized batteries and running on a single charge for months or even years at a stretch. Tags are also able to perform only minimal signal processing. That means that tracking devices cannot include the sensitive phased-array antennas and digital beamforming needed to tease out a vanishingly tiny Bluetooth signal racing through the stratosphere.
“There is a massive enterprise and industrial market for ‘send only’ applications,” says Alex Haro, CEO of Hubble Network. “Once deployed, these sensors and devices don’t need Internet connectivity except to send out their location and telemetry data, such as temperature, humidity, shock, and moisture. Hubble enables sensors and asset trackers to be deployed globally in a very battery- and cost-efficient manner.”
Other applications for the company’s technologies, Haro says, include asset tracking, environmental monitoring, container and pallet tracking, predictive maintenance, smart agriculture applications, fleet management, smart buildings, and electrical grid monitoring.
“To give you a sense of how much better Hubble Network is compared to existing satellite providers like Globalstar,” Haro says, “We are 50 times cheaper and have 20 times longer battery life. For example, we can build a Tile device that is locatable anywhere in the world without any cellular reception and lasts for years on a single coin cell battery. This will be a game-changer in the AirTag market for consumers.”
 Hubble Network chief space officer John Kim (left) and two company engineers perform tests on the company’s signal-sensing satellite technology. Hubble Network
Hubble Network chief space officer John Kim (left) and two company engineers perform tests on the company’s signal-sensing satellite technology. Hubble NetworkThe Hubble Network system—and presumably the enhanced Life360 Tags that should follow today’s announcement—use a lower energy iteration of the familiar Bluetooth wireless protocol.
Like its more famous cousin, Bluetooth Low-Energy (BLE) uses the 2.4 gigahertz band—a globally unlicensed spectrum band that many Wi-Fi routers, microwave ovens, baby monitors, wireless microphones, and other consumer devices also use.
Haro says BLE offered the most compelling, supposedly “short-range” wireless standard for Hubble Network’s purposes. By contrast, he says, the long-range, wide-area network LoRaWAN operates on a communications band, 900 megahertz, that some countries and regions regulate differently from others—making a potentially global standard around it that much more difficult to establish and maintain. Plus, he says, 2.4 GHz antennas can be roughly one-third the size of a standard LoRaWAN antenna, which makes a difference when launching material into space, when every gram matters.
Haro says that Hubble Network’s technology does require changing the sending device’s software in order to communicate with a BLE receiver satellite in orbit. And it doesn’t require any hardware modifications of the device, save one—adding a standard BLE antenna. “This is the first time that a Bluetooth chip can send data from the ground to a satellite in orbit,” Haro says. “We require the Hubble software stack loaded onto the chip to make this possible, but no physical modifications are needed. Off-the-shelf BLE chips are now capable of communicating directly with LEO satellites.”
“We believe this is comparable to when GPS was first made available for public use,” Haro adds. “It was a groundbreaking moment in technology history that significantly impacted everyday users in ways previously unavailable.”
What remains, of course, is the next hardest part: Launching all of the satellites needed to create a globally available tracking network. As to whether other companies or countries will be developing their own competitor technologies, now that Bluetooth has been revealed to have long-range communication capabilities, Haro did not speculate beyond what he envisions for his own company’s LEO ambitions.
“We currently have our first two satellites in orbit as of 4 March,” Haro says. “We plan to continue launching more satellites, aiming to have 32 in orbit by early 2026. Our pilot customers are already updating and testing their devices on our network, and we will continue to scale our constellation over the next 3 to 5 years.”
-
Disney's Robots Use Rockets to Stick the Landing
by Morgan Pope on 12. May 2024. at 13:00

It’s hard to think of a more dramatic way to make an entrance than falling from the sky. While it certainly happens often enough on the silver screen, whether or not it can be done in real life is a tantalizing challenge for our entertainment robotics team at Disney Research.
Falling is tricky for two reasons. The first and most obvious is what Douglas Adams referred to as “the sudden stop at the end.” Every second of free fall means another 9.8 m/s of velocity, and that can quickly add up to an extremely difficult energy dissipation problem. The other tricky thing about falling, especially for terrestrial animals like us, is that our normal methods for controlling our orientation disappear. We are used to relying on contact forces between our body and the environment to control which way we’re pointing. In the air, there’s nothing to push on except the air itself!
Finding a solution to these problems is a big, open-ended challenge. In the clip below, you can see one approach we’ve taken to start chipping away at it.
The video shows a small, stick-like robot with an array of four ducted fans attached to its top. The robot has a piston-like foot that absorbs the impact of a small fall, and then the ducted fans keep the robot standing by counteracting any tilting motion using aerodynamic thrust.
 Raphael Pilon [left] and Marcela de los Rios evaluate the performance of the monopod balancing robot.Disney Research
Raphael Pilon [left] and Marcela de los Rios evaluate the performance of the monopod balancing robot.Disney ResearchThe standing portion demonstrates that pushing on the air isn’t only useful during freefall. Conventional walking and hopping robots depend on ground contact forces to maintain the required orientation. These forces can ramp up quickly because of the stiffness of the system, necessitating high bandwidth control strategies. Aerodynamic forces are relatively soft, but even so, they were sufficient to keep our robots standing. And since these forces can also be applied during the flight phase of running or hopping, this approach might lead to robots that run before they walk. The thing that defines a running gait is the existence of a “flight phase” - a time when none of the feet are in contact with the ground. A running robot with aerodynamic control authority could potentially use a gait with a long flight phase. This would shift the burden of the control effort to mid-flight, simplifying the leg design and possibly making rapid bipedal motion more tractable than a moderate pace.
 Richard Landon uses a test rig to evaluate the thrust profile of a ducted fan.Disney Research
Richard Landon uses a test rig to evaluate the thrust profile of a ducted fan.Disney ResearchIn the next video, a slightly larger robot tackles a much more dramatic fall, from 65’ in the air. This simple machine has two piston-like feet and a similar array of ducted fans on top. The fans not only stabilize the robot upon landing, they also help keep it oriented properly as it falls. Inside each foot is a plug of single-use compressible foam. Crushing the foam on impact provides a nice, constant force profile, which maximizes the amount of energy dissipated per inch of contraction.
In the case of this little robot, the mechanical energy dissipation in the pistons is less than the total energy needed to be dissipated from the fall, so the rest of the mechanism takes a pretty hard hit. The size of the robot is an advantage in this case, because scaling laws mean that the strength-to-weight ratio is in its favor.
The strength of a component is a function of its cross-sectional area, while the weight of a component is a function of its volume. Area is proportional to length squared, while volume is proportional to length cubed. This means that as an object gets smaller, its weight becomes relatively small. This is why a toddler can be half the height of an adult but only a fraction of that adult’s weight, and why ants and spiders can run around on long, spindly legs. Our tiny robots take advantage of this, but we can’t stop there if we want to represent some of our bigger characters.
 Louis Lambie and Michael Lynch assemble an early ducted fan test platform. The platform was mounted on guidewires and was used for lifting capacity tests.Disney Research
Louis Lambie and Michael Lynch assemble an early ducted fan test platform. The platform was mounted on guidewires and was used for lifting capacity tests.Disney ResearchIn most aerial robotics applications, control is provided by a system that is capable of supporting the entire weight of the robot. In our case, being able to hover isn’t a necessity. The clip below shows an investigation into how much thrust is needed to control the orientation of a fairly large, heavy robot. The robot is supported on a gimbal, allowing it to spin freely. At the extremities are mounted arrays of ducted fans. The fans don’t have enough force to keep the frame in the air, but they do have a lot of control authority over the orientation.
Complicated robots are less likely to survive unscathed when subjected to the extremely high accelerations of a direct ground impact, as you can see in this early test that didn’t quite go according to plan.
In this last video, we use a combination of the previous techniques and add one more capability – a dramatic mid-air stop. Ducted fans are part of this solution, but the high-speed deceleration is principally accomplished by a large water rocket. Then the mechanical legs only have to handle the last ten feet of dropping acceleration.
Whether it’s using water or rocket fuel, the principle underlying a rocket is the same – mass is ejected from the rocket at high speed, producing a reaction force in the opposite direction via Newton’s third law. The higher the flow rate and the denser the fluid, the more force is produced. To get a high flow rate and a quick response time, we needed a wide nozzle that went from closed to open cleanly in a matter of milliseconds. We designed a system using a piece of copper foil and a custom punch mechanism that accomplished just that.
 Grant Imahara pressurizes a test tank to evaluate an early valve prototype [left]. The water rocket in action - note the laminar, two-inch-wide flow as it passes through the specially designed nozzleDisney Research
Grant Imahara pressurizes a test tank to evaluate an early valve prototype [left]. The water rocket in action - note the laminar, two-inch-wide flow as it passes through the specially designed nozzleDisney ResearchOnce the water rocket has brought the robot to a mid-air stop, the ducted fans are able to hold it in a stable hover about ten feet above the deck. When they cut out, the robot falls again and the legs absorb the impact. In the video, the robot has a couple of loose tethers attached as a testing precaution, but they don’t provide any support, power, or guidance.
“It might not be so obvious as to what this can be directly used for today, but these rough proof-of-concept experiments show that we might be able to work within real-world physics to do the high falls our characters do on the big screen, and someday actually stick the landing,” explains Tony Dohi, the project lead.
There are still a large number of problems for future projects to address. Most characters have legs that bend on hinges rather than compress like pistons, and don’t wear a belt made of ducted fans. Beyond issues of packaging and form, making sure that the robot lands exactly where it intends to land has interesting implications for perception and control. Regardless, we think we can confirm that this kind of entrance has–if you’ll excuse the pun–quite the impact.
-
Video Friday: Robot Bees
by Evan Ackerman on 10. May 2024. at 16:26

Video Friday is your weekly selection of awesome robotics videos, collected by your friends at IEEE Spectrum robotics. We also post a weekly calendar of upcoming robotics events for the next few months. Please send us your events for inclusion.
ICRA 2024: 13–17 May 2024, YOKOHAMA, JAPAN
RoboCup 2024: 17–22 July 2024, EINDHOVEN, NETHERLANDS
ICSR 2024: 23–26 October 2024, ODENSE, DENMARK
Cybathlon 2024: 25–27 October 2024, ZURICH
Enjoy today’s videos!
Festo has robot bees!
It’s a very clever design, but the size makes me terrified of whatever the bees are that Festo seems to be familiar with.
[ Festo ]
Boing, boing, boing!
[ USC ]
Why the heck would you take the trouble to program a robot to make sweet potato chips and then not scarf them down yourself?
[ Dino Robotics ]
Mobile robots can transport payloads far greater than their mass through vehicle traction. However, off-road terrain features substantial variation in height, grade, and friction, which can cause traction to degrade or fail catastrophically. This paper presents a system that utilizes a vehicle-mounted, multipurpose manipulator to physically adapt the robot with unique anchors suitable for a particular terrain for autonomous payload transport.
[ DART Lab ]
Turns out that working on a collaborative task with a robot can make humans less efficient, because we tend to overestimate the robot’s capabilities.
[ CHI 2024 ]
Wing posts a video with the title “What Do Wing’s Drones Sound Like” but only includes a brief snippet—though nothing without background room noise—revealing to curious viewers and listeners exactly what Wing’s drones sound like.
Because, look, a couple seconds of muted audio underneath a voiceover is in fact not really answering the question.
[ Wing ]
This first instance of ROB 450 in Winter 2024 challenged students to synthesize the knowledge acquired through their Robotics undergraduate courses at the University of Michigan to use a systematic and iterative design and analysis process and apply it to solving a real, open-ended Robotics problem.
This Microsoft Future Leaders in Robotics and AI Seminar is from Catie Cuan at Stanford, on “Choreorobotics: Teaching Robots How to Dance With Humans.”
As robots transition from industrial and research settings into everyday environments, robots must be able to (1) learn from humans while benefiting from the full range of the humans’ knowledge and (2) learn to interact with humans in safe, intuitive, and social ways. I will present a series of compelling robot behaviors, where human perception and interaction are foregrounded in a variety of tasks.
[ UMD ]
-
The New Shadow Hand Can Take a Beating
by Evan Ackerman on 10. May 2024. at 14:00

For years, Shadow Robot Company’s Shadow Hand has arguably been the gold standard for robotic manipulation. Beautiful and expensive, it is able to mimic the form factor and functionality of human hands, which has made it ideal for complex tasks. I’ve personally experienced how amazing it is to use Shadow Hands in a teleoperation context, and it’s hard to imagine anything better.
The problem with the original Shadow hand was (and still is) fragility. In a research environment, this has been fine, except that research is changing: Roboticists no longer carefully program manipulation tasks by, uh, hand. Now it’s all about machine learning, in which you need robotic hands to massively fail over and over again until they build up enough data to understand how to succeed.
“We’ve aimed for robustness and performance over anthropomorphism and human size and shape.” —Rich Walker, Shadow Robot Company
Doing this with a Shadow Hand was just not realistic, which Google DeepMind understood five years ago when it asked Shadow Robot to build it a new hand with hardware that could handle the kind of training environments that now typify manipulation research. So Shadow Robot spent the last half-decade-ish working on a new, three-fingered Shadow Hand, which the company unveiled today. The company is calling it, appropriately enough, “the new Shadow Hand.”
As you can see, this thing is an absolute beast. Shadow Robot says that the new hand is “robust against a significant amount of misuse, including aggressive force demands, abrasion and impacts.” Part of the point, though, is that what robot-hand designers might call “misuse,” robot-manipulation researchers might very well call “progress,” and the hand is designed to stand up to manipulation research that pushes the envelope of what robotic hardware and software are physically capable of.
Shadow Robot understands that despite its best engineering efforts, this new hand will still occasionally break (because it’s a robot and that’s what robots do), so the company designed it to be modular and easy to repair. Each finger is its own self-contained unit that can be easily swapped out, with five Maxon motors in the base of the finger driving the four finger joints through cables in a design that eliminates backlash. The cables themselves will need replacement from time to time, but it’s much easier to do this on the new Shadow Hand than it was on the original. Shadow Robot says that you can swap out an entire New Hand’s worth of cables in the same time it would take you to replace a single cable on the old hand.
 Shadow Robot
Shadow RobotThe new Shadow Hand itself is somewhat larger than a typical human hand, and heavier too: Each modular finger unit weighs 1.2 kilograms, and the entire three-fingered hand is just over 4 kg. The fingers have humanlike kinematics, and each joint can move up to 180 degrees per second with the capability of exerting at least 8 newtons of force at each fingertip. Both force control and position control are available, and the entire hand runs Robot Operating System, the Open Source Robotics Foundation’s collection of open-source software libraries and tools.
One of the coolest new features of this hand is the tactile sensing. Shadow Robot has decided to take the optical route with fingertip sensors, GelSight-style. Each fingertip is covered in soft, squishy gel with thousands of embedded particles. Cameras in the fingers behind the gel track each of those particles, and when the fingertip touches something, the particles move. Based on that movement, the fingertips can very accurately detect the magnitude and direction of even very small forces. And there are even more sensors on the insides of the fingers too, with embedded Hall effect sensors to help provide feedback during grasping and manipulation tasks.
 Shadow Robot
Shadow RobotThe most striking difference here is how completely different of a robotic-manipulation philosophy this new hand represents for Shadow Robot. “We’ve aimed for robustness and performance over anthropomorphism and human size and shape,” says Rich Walker, director of Shadow Robot Company. “There’s a very definite design choice there to get something that really behaves much more like an optimized manipulator rather than a humanlike hand.”
Walker explains that Shadow Robot sees two different approaches to manipulation within the robotics community right now: There’s imitation learning, where a human does a task and then a robot tries to do the task the same way, and then there’s reinforcement learning, where a robot tries to figure out how do the task by itself. “Obviously, this hand was built from the ground up to make reinforcement learning easy.”
The hand was also built from the ground up to be rugged and repairable, which had a significant effect on the form factor. To make the fingers modular, they have to be chunky, and trying to cram five of them onto one hand was just not practical. But because of this modularity, Shadow Robot could make you a five-fingered hand if you really wanted one. Or a two-fingered hand. Or (and this is the company’s suggestion, not mine) “a giant spider.” Really, though, it’s probably not useful to get stuck on the form factor. Instead, focus more on what the hand can do. In fact, Shadow Robot tells me that the best way to think about the hand in the context of agility is as having three thumbs, not three fingers, but Walker says that “if we describe it as that, people get confused.”
There’s still definitely a place for the original anthropomorphic Shadow Hand, and Shadow Robot has no plans to discontinue it. “It’s clear that for some people anthropomorphism is a deal breaker, they have to have it,” Walker says. “But for a lot of people, the idea that they could have something which is really robust and dexterous and can gather lots of data, that’s exciting enough to be worth saying okay, what can we do with this? We’re very interested to find out what happens.”
The Shadow New Hand is available now, starting at about US $74,000 depending on configuration.
-
Commercial Space Stations Approach Launch Phase
by Andrew Jones on 10. May 2024. at 13:00

A changing of the guard in space stations is on the horizon as private companies work toward providing new opportunities for science, commerce, and tourism in outer space.
Blue Origin is one of a number of private-sector actors aiming to harbor commercial activities in low Earth orbit (LEO) as the creaking and leaking International Space Station (ISS) approaches its drawdown. Partners in Blue Origin’s Orbital Reef program, including firms Redwire, Sierra Space, and Boeing, are each reporting progress in their respective components of the program. The collaboration itself may not be on such strong ground. Such endeavors may also end up slowed and controlled by regulation so far absent from many new, commercial areas of space.
Orbital Reef recently aced testing milestones for its critical life support system, with assistance from NASA. These included hitting targets for trace contaminant control, water contaminant oxidation, urine water recovery, and water tank tests—all of which are required to operate effectively and efficiently to enable finite resources to keep delicate human beings alive in orbit for long timeframes.
Blue Origin, founded by Jeff Bezos, is characteristically tight-lipped on its progress and challenges and declined to provide further comment on progress beyond NASA’s life-support press statement.
The initiative is backed by NASA’s Commercial LEO Destinations (CLD) program, through which the agency is providing funding to encourage the private sector to build space habitats. NASA may also be the main client starting out, although the wider goal is to foster a sustainable commercial presence in LEO.
The Space-Based Road Ahead
The challenge Orbital Reef faces is considerable: reimagining successful earthbound technologies—such as regenerative life-support systems, expandable habitats and 3D printing—but now in orbit, on a commercially viable platform. The technologies must also adhere to unforgiving constraints of getting mass and volume to space, and operating on a significantly reduced budget compared to earlier national space station programs.
Add to that autonomy and redundancy that so many mission-critical functions will demand, as well as high-bandwidth communications required to return data and allow streaming and connectivity for visitors.
In one recent step forward for Orbital Reef, Sierra Space, headquartered in Louisville, Colo., performed an Ultimate Burst Pressure (UBP) test on its architecture in January. This involved inflating, to the point of failure, the woven fabric pressure shell—including Vectran, a fabric that becomes rigid and stronger than steel when pressurized on orbit—for its Large Integrated Flexible Environment (LIFE) habitat. Sierra’s test reached 530,000 pascals (77 pounds per square inch) before it burst—marking a successful failure that far surpassed NASA’s recommended safety level of 419,200 Pa (60.8 psi).
Notably, the test article was 300 cubic meters in volume, or one-third the volume of ISS—a megaproject constructed by some 15 countries over more than 30 launches. LIFE will contain 10 crew cabins along with living, galley, and gym areas. This is expected to form part of the modular Orbital Reef complex. The company stated last year it aimed to launch a pathfinder version of LIFE around the end of 2026.
Inflating and Expanding Expectations
Whereas the size of ISS modules and those of China’s new, three-module Tiangong space station, constructed in 2021–22, was dependent on the size of the payload bay or fairing of the shuttle or rocket doing the launching, using expandable quarters allows Orbital Reef to offer habitable areas multiples (in this case five times) greater than the volume of the 5-meter rocket fairing to be used to transport the system to orbit.
Other modules will include Node, with an airlock and docking facilities, also developed by Sierra Space, as well as a spherical Core module developed by Blue Origin. Finally, Boeing is developing a research module, which will include a science cupola, akin to that on the ISS, external payload facilities, and a series of laboratories.
Orbital Reef will be relying on some technologies developed for and spun off from the ISS project, which was completed in 2011 at a cost of US $100 billion. The new station will be operating on fractions of such budgets, with Blue Origin awarded $130 million of a total $415.6 million given to three companies in 2021.
“NASA is using a two-phase strategy to, first, support the development of commercial destinations and, secondly, enable the agency to purchase services as one of many customers” says NASA spokesperson Anna Schneider, at NASA’s Johnson Space Center.
For instance, Northrop Grumman is working on its Persistent Platform to provide autonomous and robotic capabilities for commercial science and manufacturing capabilities in LEO.
Such initiatives could face politically constructed hurdles, however. Last year, some industry advocates opposed a White House proposal that would see new commercial space activities such as space stations regulated.
Meanwhile, the European Space Agency (ESA) signed a memorandum of understanding in late 2023 with Airbus and Voyager Space, headquartered in Denver, which would give ESA access to a planned Starlab space station after the ISS is transitioned out. That two-module orbital outpost will also be inflatable and is now expected to be launched in 2028.
China also is exploring opening its Tiangong station to commercial activities, including its own version of NASA’s commercial cargo and extending the station with new modules—and new competition for the world’s emerging space station sector.
-
Your Next Great AI Engineer Already Works for You
by CodeSignal on 09. May 2024. at 18:42

The AI future has arrived. From tech and finance, to healthcare, retail, and manufacturing, nearly every industry today has begun to incorporate artificial intelligence (AI) into their technology platforms and business operations. The result is a surging talent demand for engineers who can design, implement, leverage, and manage AI systems.
Over the next decade, the need for AI talent will only continue to grow. The US Bureau of Labor Statistics expects demand for AI engineers to increase by 23 percent by 2030 and demand for machine learning (ML) engineers, a subfield of AI, to grow by up to 22 percent.
In the tech industry, this demand is in full swing. Job postings that call for skills in generative AI increased by an incredible 1,848 percent in 2023, a recent labor market analysis shows. The analysis also found that there were over 385,000 postings for AI roles in 2023.
 Figure 1: Growth of job postings requiring skills in generative AI, 2022-2023
Figure 1: Growth of job postings requiring skills in generative AI, 2022-2023
To capitalize on the transformative potential of AI, companies cannot simply hire new AI engineers: there just aren’t enough of them yet. To address the global shortage of AI engineering talent, you must upskill and reskill your existing engineers.
Essential skills for AI and ML
AI and its subfields, machine learning (ML) and natural language processing (NLP), all involve training algorithms on large sets of data to produce models that can perform complex tasks. As a result, different types of AI engineering roles require many of the same core skills.
CodeSignal’s Talent Science team and technical subject matter experts have conducted extensive skills mapping of AI engineering roles to define the skills required of these roles. These are the core skills they identified for two popular AI roles: ML engineering and NLP engineering.
Machine learning (ML) engineering core skills

Natural language processing (NLP) engineering core skills

Developing AI skills on your teams
A recent McKinsey report finds that upskilling and reskilling are core ways that organizations fill AI skills gaps on their teams. Alexander Sukharevsky, Senior Partner at McKinsey, explains in the report: “When it comes to sourcing AI talent, the most popular strategy among all respondents is reskilling existing employees. Nearly half of the companies we surveyed are doing so.”
So: what is the best way to develop the AI skills you need within your existing teams? To answer that, we first need to dive deeper into how humans learn new skills.
Components of effective skills development
Most corporate learning programs today use the model of traditional classroom learning where one teacher, with one lesson, serves many learners. An employee starts by choosing a program, often with little guidance. Once they begin the course, lessons likely use videos to deliver instruction and are followed by quizzes to gauge their retention of the information.
There are several problems with this model:
- Decades of research show that the traditional, one-to-many model of learning is not the most effective way to learn. Educational psychologist Benjamin Bloom observed that students who learned through one-on-one tutoring outperformed their peers by two standard deviations; that is, they performed better than 98 percent of those who learned in traditional classroom environments. The superiority of one-on-one tutoring over classroom learning has been dubbed the 2-sigma problem in education (see Figure 2 below).
- Multiple-choice quizzes provide a poor signal of employees’ skills—especially for specialized technical skills like AI and ML engineering. Quizzes also do not give learners the opportunity to apply what they’ve learned in a realistic context or in the flow of their work.
- Without guidance grounded in their current skills, strengths, and goals—as well as their team’s needs—employees may choose courses or learning programs that are mismatched to their level of skill proficiency or goals.

Developing your team members’ mastery of the AI and ML skills your team needs requires a learning program that delivers the following:
- One-on-one tutoring. Today’s best-in-class technical learning programs use AI-powered assistants that are contextually aware and fully integrated with the learning environment to deliver personalized, one-on-one guidance and feedback to learners at scale.
The use of AI to support their learning will come as no surprise to your developers and other technical employees: a recent survey shows that 81 percent of developers already use AI tools in their work—and of those, 76 percent use them to learn new knowledge and skills.
- Practice-based learning. Decades of research show that people learn best with active practice, not passive intake of information. The learning program you use to level up your team’s skills in AI and ML should be practice-centered and make use of coding exercises that simulate real AI and ML engineering work.
- Outcome-driven tools. Lastly, the best technical upskilling programs ensure employees actually build relevant skills (not just check a box) and apply what they learn on the job. Learning programs should also give managers visibility into their team members’ skill growth and mastery. Your platform should include benchmarking data, to allow you to compare your team’s skills to the larger population of technical talent, as well as integrations with your existing learning systems.
Deep dive: Practice-based learning for AI skills
Below is an example of an advanced practice exercise from the Introduction to Neural Networks with TensorFlow course in CodeSignal Develop.
Example practice: Implementing layers in a neural network
In this practice exercise, learners build their skills in designing neural network layers to improve the performance of the network. Learners implement their solution in a realistic IDE and built-in terminal in the right side of the screen, and interact with Cosmo, an AI-powered tutor and guide, in the panel on the left side of the screen.
Practice description: Now that you have trained a model with additional epochs, let’s tweak the neural network’s architecture. Your task is to implement a second dense layer in the neural network to potentially improve its learning capabilities. Remember: Configuring layers effectively is crucial for the model’s performance!

Conclusion
The demand for AI and ML engineers is here, and will continue to grow over the coming years as AI technologies become critical to more and more organizations across all industries. Companies seeking to fill AI and ML skills gaps on their teams must invest in upskilling and reskilling their existing technical teams with crucial AI and ML skills.
Learn more:
-
Management Versus Technical Track
by Tariq Samad on 09. May 2024. at 18:00

This article is part of our exclusive career advice series in partnership with the IEEE Technology and Engineering Management Society.
As you begin your professional career freshly armed with an engineering degree, your initial roles and responsibilities are likely to revolve around the knowledge and competencies you learned at school. If you do well in your job, you’re apt to be promoted, gaining more responsibilities such as managing projects, interacting with other departments, making presentations to management, and meeting with customers. You probably also will gain a general understanding of how your company and the business world work.
At some point in your career, you’re likely to be asked an important question: Are you interested in a management role?
There is no right or wrong answer. Engineers have fulfilling, rewarding careers as individual contributors and as managers—and companies need both. You should decide your path based on your interests and ambitions as well as your strengths and shortcomings.
However, the specific considerations involved aren’t always obvious. To help you, this article covers some of the differences between the two career paths, as well as factors that might influence you.
The remarks are based on our personal experiences in corporate careers spanning decades in the managerial track and the technical track. Tariq worked at Honeywell; Gus at 3M. We have included advice from IEEE Technology and Engineering Management Society colleagues.
Opting for either track isn’t a career-long commitment. Many engineers who go into management return to the technical track, in some cases of their own volition. And management opportunities can be adopted late in one’s career, again based on individual preferences or organizational needs.
In either case, there tends to be a cost to switching tracks. While the decision of which track to take certainly isn’t irrevocable, it behooves engineers to understand the pros and cons involved.
Differences between the two tracks
Broadly, the managerial track is similar across all companies. It starts with supervising small groups, extends through middle-management layers, progresses up to leadership positions and, ultimately, the executive suite. Management backgrounds can vary, however. For example, although initial management levels in a technology organization generally require an engineering or science degree, some top leaders in a company might be more familiar with sales, marketing, or finance.
It’s a different story for climbing the technical ladder. Beyond the first engineering-level positions, there is no standard model. In some cases individual contributors hit the career ceiling below the management levels. In others, formal roles exist that are equivalent to junior management positions in terms of pay scale and other aspects.
“Engineers have fulfilling, rewarding careers as individual contributors and as managers—and companies need both.”
Some organizations have a well-defined promotional system with multiple salary bands for technical staff, parallel to those for management positions. Senior technologists often have a title such as Fellow, staff scientist, or architect, with top-of-the-ladder positions including corporate Fellow, chief engineer/scientist, and enterprise architect.
Organizational structures vary considerably among small companies—including startups, medium companies, and large corporations. Small businesses often don’t have formal or extensive technical tracks, but their lack of structure can make it easier to advance in responsibilities and qualifications while staying deeply technical.
In more established companies, structures and processes tend to be well defined and set by policy.
For those interested in the technical track, the robustness of a company’s technical ladder can be a factor in joining the company. Conversely, if you’re interested in the technical ladder and you’re working for a company that does not offer one, that might be a reason to look for opportunities elsewhere.
Understanding the career paths a company offers is especially important for technologists.
The requirements for success
First and foremost, the track you lean toward should align with aspirations for your career—and your personal life.
As you advance in the management path, you can drive business and organizational success through decisions you make and influence. You also will be expected to shape and nurture employees in your organization by providing feedback and guidance. You likely will have more control over resources—people as well as funding—and more opportunity for defining and executing strategy.
The technical path has much going for it as well, especially if you are passionate about solving technical challenges and increasing your expertise in your area of specialization. You won’t be supervising large numbers of employees, but you will manage significant projects and programs that give you chances to propose and define such initiatives. You also likely will have more control of your time and not have to deal with the stress involved with being responsible for the performance of the people and groups reporting to you.
The requirements for success in the two tracks offer contrasts as well. Technical expertise is an entry requirement for the technical track. It’s not just technical depth, however. As you advance, technical breadth is likely to become increasingly important and will need to be supplemented by an understanding of the business, including markets, customers, economics, and government regulations.
Pure technical expertise will never be the sole performance criterion. Soft skills such as verbal and written communication, getting along with people, time management, and teamwork are crucial for managers and leaders.
On the financial side, salaries and growth prospects generally will be higher on the managerial track. Executive tiers can include substantial bonuses and stock options. Salary growth is typically slower for senior technologists.
Managerial and technical paths are not always mutually exclusive. It is, in fact, not uncommon for staff members who are on the technical ladder to supervise small teams. And some senior managers are able to maintain their technical expertise and earn recognition for it.
We recommend you take time to consider which of the two tracks is more attractive—before you get asked to choose. If you’re early in your career, you don’t need to make this important decision now. You can keep your options open and discuss them with your peers, senior colleagues, and management. And you can contemplate and clarify what your objectives and preferences are. When the question does come up, you’ll be better prepared to answer it.
-
Andrew Ng: Unbiggen AI
by Eliza Strickland on 09. February 2022. at 15:31

Andrew Ng has serious street cred in artificial intelligence. He pioneered the use of graphics processing units (GPUs) to train deep learning models in the late 2000s with his students at Stanford University, cofounded Google Brain in 2011, and then served for three years as chief scientist for Baidu, where he helped build the Chinese tech giant’s AI group. So when he says he has identified the next big shift in artificial intelligence, people listen. And that’s what he told IEEE Spectrum in an exclusive Q&A.
Ng’s current efforts are focused on his company Landing AI, which built a platform called LandingLens to help manufacturers improve visual inspection with computer vision. He has also become something of an evangelist for what he calls the data-centric AI movement, which he says can yield “small data” solutions to big issues in AI, including model efficiency, accuracy, and bias.
Andrew Ng on...
- What’s next for really big models
- The career advice he didn’t listen to
- Defining the data-centric AI movement
- Synthetic data
- Why Landing AI asks its customers to do the work
The great advances in deep learning over the past decade or so have been powered by ever-bigger models crunching ever-bigger amounts of data. Some people argue that that’s an unsustainable trajectory. Do you agree that it can’t go on that way?
Andrew Ng: This is a big question. We’ve seen foundation models in NLP [natural language processing]. I’m excited about NLP models getting even bigger, and also about the potential of building foundation models in computer vision. I think there’s lots of signal to still be exploited in video: We have not been able to build foundation models yet for video because of compute bandwidth and the cost of processing video, as opposed to tokenized text. So I think that this engine of scaling up deep learning algorithms, which has been running for something like 15 years now, still has steam in it. Having said that, it only applies to certain problems, and there’s a set of other problems that need small data solutions.
When you say you want a foundation model for computer vision, what do you mean by that?
Ng: This is a term coined by Percy Liang and some of my friends at Stanford to refer to very large models, trained on very large data sets, that can be tuned for specific applications. For example, GPT-3 is an example of a foundation model [for NLP]. Foundation models offer a lot of promise as a new paradigm in developing machine learning applications, but also challenges in terms of making sure that they’re reasonably fair and free from bias, especially if many of us will be building on top of them.
What needs to happen for someone to build a foundation model for video?
Ng: I think there is a scalability problem. The compute power needed to process the large volume of images for video is significant, and I think that’s why foundation models have arisen first in NLP. Many researchers are working on this, and I think we’re seeing early signs of such models being developed in computer vision. But I’m confident that if a semiconductor maker gave us 10 times more processor power, we could easily find 10 times more video to build such models for vision.
Having said that, a lot of what’s happened over the past decade is that deep learning has happened in consumer-facing companies that have large user bases, sometimes billions of users, and therefore very large data sets. While that paradigm of machine learning has driven a lot of economic value in consumer software, I find that that recipe of scale doesn’t work for other industries.
It’s funny to hear you say that, because your early work was at a consumer-facing company with millions of users.
Ng: Over a decade ago, when I proposed starting the Google Brain project to use Google’s compute infrastructure to build very large neural networks, it was a controversial step. One very senior person pulled me aside and warned me that starting Google Brain would be bad for my career. I think he felt that the action couldn’t just be in scaling up, and that I should instead focus on architecture innovation.
“In many industries where giant data sets simply don’t exist, I think the focus has to shift from big data to good data. Having 50 thoughtfully engineered examples can be sufficient to explain to the neural network what you want it to learn.”
—Andrew Ng, CEO & Founder, Landing AII remember when my students and I published the first NeurIPS workshop paper advocating using CUDA, a platform for processing on GPUs, for deep learning—a different senior person in AI sat me down and said, “CUDA is really complicated to program. As a programming paradigm, this seems like too much work.” I did manage to convince him; the other person I did not convince.
I expect they’re both convinced now.
Ng: I think so, yes.
Over the past year as I’ve been speaking to people about the data-centric AI movement, I’ve been getting flashbacks to when I was speaking to people about deep learning and scalability 10 or 15 years ago. In the past year, I’ve been getting the same mix of “there’s nothing new here” and “this seems like the wrong direction.”
How do you define data-centric AI, and why do you consider it a movement?
Ng: Data-centric AI is the discipline of systematically engineering the data needed to successfully build an AI system. For an AI system, you have to implement some algorithm, say a neural network, in code and then train it on your data set. The dominant paradigm over the last decade was to download the data set while you focus on improving the code. Thanks to that paradigm, over the last decade deep learning networks have improved significantly, to the point where for a lot of applications the code—the neural network architecture—is basically a solved problem. So for many practical applications, it’s now more productive to hold the neural network architecture fixed, and instead find ways to improve the data.
When I started speaking about this, there were many practitioners who, completely appropriately, raised their hands and said, “Yes, we’ve been doing this for 20 years.” This is the time to take the things that some individuals have been doing intuitively and make it a systematic engineering discipline.
The data-centric AI movement is much bigger than one company or group of researchers. My collaborators and I organized a data-centric AI workshop at NeurIPS, and I was really delighted at the number of authors and presenters that showed up.
You often talk about companies or institutions that have only a small amount of data to work with. How can data-centric AI help them?
Ng: You hear a lot about vision systems built with millions of images—I once built a face recognition system using 350 million images. Architectures built for hundreds of millions of images don’t work with only 50 images. But it turns out, if you have 50 really good examples, you can build something valuable, like a defect-inspection system. In many industries where giant data sets simply don’t exist, I think the focus has to shift from big data to good data. Having 50 thoughtfully engineered examples can be sufficient to explain to the neural network what you want it to learn.
When you talk about training a model with just 50 images, does that really mean you’re taking an existing model that was trained on a very large data set and fine-tuning it? Or do you mean a brand new model that’s designed to learn only from that small data set?
Ng: Let me describe what Landing AI does. When doing visual inspection for manufacturers, we often use our own flavor of RetinaNet. It is a pretrained model. Having said that, the pretraining is a small piece of the puzzle. What’s a bigger piece of the puzzle is providing tools that enable the manufacturer to pick the right set of images [to use for fine-tuning] and label them in a consistent way. There’s a very practical problem we’ve seen spanning vision, NLP, and speech, where even human annotators don’t agree on the appropriate label. For big data applications, the common response has been: If the data is noisy, let’s just get a lot of data and the algorithm will average over it. But if you can develop tools that flag where the data’s inconsistent and give you a very targeted way to improve the consistency of the data, that turns out to be a more efficient way to get a high-performing system.
“Collecting more data often helps, but if you try to collect more data for everything, that can be a very expensive activity.”
—Andrew NgFor example, if you have 10,000 images where 30 images are of one class, and those 30 images are labeled inconsistently, one of the things we do is build tools to draw your attention to the subset of data that’s inconsistent. So you can very quickly relabel those images to be more consistent, and this leads to improvement in performance.
Could this focus on high-quality data help with bias in data sets? If you’re able to curate the data more before training?
Ng: Very much so. Many researchers have pointed out that biased data is one factor among many leading to biased systems. There have been many thoughtful efforts to engineer the data. At the NeurIPS workshop, Olga Russakovsky gave a really nice talk on this. At the main NeurIPS conference, I also really enjoyed Mary Gray’s presentation, which touched on how data-centric AI is one piece of the solution, but not the entire solution. New tools like Datasheets for Datasets also seem like an important piece of the puzzle.
One of the powerful tools that data-centric AI gives us is the ability to engineer a subset of the data. Imagine training a machine-learning system and finding that its performance is okay for most of the data set, but its performance is biased for just a subset of the data. If you try to change the whole neural network architecture to improve the performance on just that subset, it’s quite difficult. But if you can engineer a subset of the data you can address the problem in a much more targeted way.
When you talk about engineering the data, what do you mean exactly?
Ng: In AI, data cleaning is important, but the way the data has been cleaned has often been in very manual ways. In computer vision, someone may visualize images through a Jupyter notebook and maybe spot the problem, and maybe fix it. But I’m excited about tools that allow you to have a very large data set, tools that draw your attention quickly and efficiently to the subset of data where, say, the labels are noisy. Or to quickly bring your attention to the one class among 100 classes where it would benefit you to collect more data. Collecting more data often helps, but if you try to collect more data for everything, that can be a very expensive activity.
For example, I once figured out that a speech-recognition system was performing poorly when there was car noise in the background. Knowing that allowed me to collect more data with car noise in the background, rather than trying to collect more data for everything, which would have been expensive and slow.
What about using synthetic data, is that often a good solution?
Ng: I think synthetic data is an important tool in the tool chest of data-centric AI. At the NeurIPS workshop, Anima Anandkumar gave a great talk that touched on synthetic data. I think there are important uses of synthetic data that go beyond just being a preprocessing step for increasing the data set for a learning algorithm. I’d love to see more tools to let developers use synthetic data generation as part of the closed loop of iterative machine learning development.
Do you mean that synthetic data would allow you to try the model on more data sets?
Ng: Not really. Here’s an example. Let’s say you’re trying to detect defects in a smartphone casing. There are many different types of defects on smartphones. It could be a scratch, a dent, pit marks, discoloration of the material, other types of blemishes. If you train the model and then find through error analysis that it’s doing well overall but it’s performing poorly on pit marks, then synthetic data generation allows you to address the problem in a more targeted way. You could generate more data just for the pit-mark category.
“In the consumer software Internet, we could train a handful of machine-learning models to serve a billion users. In manufacturing, you might have 10,000 manufacturers building 10,000 custom AI models.”
—Andrew NgSynthetic data generation is a very powerful tool, but there are many simpler tools that I will often try first. Such as data augmentation, improving labeling consistency, or just asking a factory to collect more data.
To make these issues more concrete, can you walk me through an example? When a company approaches Landing AI and says it has a problem with visual inspection, how do you onboard them and work toward deployment?
Ng: When a customer approaches us we usually have a conversation about their inspection problem and look at a few images to verify that the problem is feasible with computer vision. Assuming it is, we ask them to upload the data to the LandingLens platform. We often advise them on the methodology of data-centric AI and help them label the data.
One of the foci of Landing AI is to empower manufacturing companies to do the machine learning work themselves. A lot of our work is making sure the software is fast and easy to use. Through the iterative process of machine learning development, we advise customers on things like how to train models on the platform, when and how to improve the labeling of data so the performance of the model improves. Our training and software supports them all the way through deploying the trained model to an edge device in the factory.
How do you deal with changing needs? If products change or lighting conditions change in the factory, can the model keep up?
Ng: It varies by manufacturer. There is data drift in many contexts. But there are some manufacturers that have been running the same manufacturing line for 20 years now with few changes, so they don’t expect changes in the next five years. Those stable environments make things easier. For other manufacturers, we provide tools to flag when there’s a significant data-drift issue. I find it really important to empower manufacturing customers to correct data, retrain, and update the model. Because if something changes and it’s 3 a.m. in the United States, I want them to be able to adapt their learning algorithm right away to maintain operations.
In the consumer software Internet, we could train a handful of machine-learning models to serve a billion users. In manufacturing, you might have 10,000 manufacturers building 10,000 custom AI models. The challenge is, how do you do that without Landing AI having to hire 10,000 machine learning specialists?
So you’re saying that to make it scale, you have to empower customers to do a lot of the training and other work.
Ng: Yes, exactly! This is an industry-wide problem in AI, not just in manufacturing. Look at health care. Every hospital has its own slightly different format for electronic health records. How can every hospital train its own custom AI model? Expecting every hospital’s IT personnel to invent new neural-network architectures is unrealistic. The only way out of this dilemma is to build tools that empower the customers to build their own models by giving them tools to engineer the data and express their domain knowledge. That’s what Landing AI is executing in computer vision, and the field of AI needs other teams to execute this in other domains.
Is there anything else you think it’s important for people to understand about the work you’re doing or the data-centric AI movement?
Ng: In the last decade, the biggest shift in AI was a shift to deep learning. I think it’s quite possible that in this decade the biggest shift will be to data-centric AI. With the maturity of today’s neural network architectures, I think for a lot of the practical applications the bottleneck will be whether we can efficiently get the data we need to develop systems that work well. The data-centric AI movement has tremendous energy and momentum across the whole community. I hope more researchers and developers will jump in and work on it.
This article appears in the April 2022 print issue as “Andrew Ng, AI Minimalist.”
-
How AI Will Change Chip Design
by Rina Diane Caballar on 08. February 2022. at 14:00

The end of Moore’s Law is looming. Engineers and designers can do only so much to miniaturize transistors and pack as many of them as possible into chips. So they’re turning to other approaches to chip design, incorporating technologies like AI into the process.
Samsung, for instance, is adding AI to its memory chips to enable processing in memory, thereby saving energy and speeding up machine learning. Speaking of speed, Google’s TPU V4 AI chip has doubled its processing power compared with that of its previous version.
But AI holds still more promise and potential for the semiconductor industry. To better understand how AI is set to revolutionize chip design, we spoke with Heather Gorr, senior product manager for MathWorks’ MATLAB platform.
How is AI currently being used to design the next generation of chips?
Heather Gorr: AI is such an important technology because it’s involved in most parts of the cycle, including the design and manufacturing process. There’s a lot of important applications here, even in the general process engineering where we want to optimize things. I think defect detection is a big one at all phases of the process, especially in manufacturing. But even thinking ahead in the design process, [AI now plays a significant role] when you’re designing the light and the sensors and all the different components. There’s a lot of anomaly detection and fault mitigation that you really want to consider.
 Heather GorrMathWorks
Heather GorrMathWorksThen, thinking about the logistical modeling that you see in any industry, there is always planned downtime that you want to mitigate; but you also end up having unplanned downtime. So, looking back at that historical data of when you’ve had those moments where maybe it took a bit longer than expected to manufacture something, you can take a look at all of that data and use AI to try to identify the proximate cause or to see something that might jump out even in the processing and design phases. We think of AI oftentimes as a predictive tool, or as a robot doing something, but a lot of times you get a lot of insight from the data through AI.
What are the benefits of using AI for chip design?
Gorr: Historically, we’ve seen a lot of physics-based modeling, which is a very intensive process. We want to do a reduced order model, where instead of solving such a computationally expensive and extensive model, we can do something a little cheaper. You could create a surrogate model, so to speak, of that physics-based model, use the data, and then do your parameter sweeps, your optimizations, your Monte Carlo simulations using the surrogate model. That takes a lot less time computationally than solving the physics-based equations directly. So, we’re seeing that benefit in many ways, including the efficiency and economy that are the results of iterating quickly on the experiments and the simulations that will really help in the design.
So it’s like having a digital twin in a sense?
Gorr: Exactly. That’s pretty much what people are doing, where you have the physical system model and the experimental data. Then, in conjunction, you have this other model that you could tweak and tune and try different parameters and experiments that let sweep through all of those different situations and come up with a better design in the end.
So, it’s going to be more efficient and, as you said, cheaper?
Gorr: Yeah, definitely. Especially in the experimentation and design phases, where you’re trying different things. That’s obviously going to yield dramatic cost savings if you’re actually manufacturing and producing [the chips]. You want to simulate, test, experiment as much as possible without making something using the actual process engineering.
We’ve talked about the benefits. How about the drawbacks?
Gorr: The [AI-based experimental models] tend to not be as accurate as physics-based models. Of course, that’s why you do many simulations and parameter sweeps. But that’s also the benefit of having that digital twin, where you can keep that in mind—it’s not going to be as accurate as that precise model that we’ve developed over the years.
Both chip design and manufacturing are system intensive; you have to consider every little part. And that can be really challenging. It’s a case where you might have models to predict something and different parts of it, but you still need to bring it all together.
One of the other things to think about too is that you need the data to build the models. You have to incorporate data from all sorts of different sensors and different sorts of teams, and so that heightens the challenge.
How can engineers use AI to better prepare and extract insights from hardware or sensor data?
Gorr: We always think about using AI to predict something or do some robot task, but you can use AI to come up with patterns and pick out things you might not have noticed before on your own. People will use AI when they have high-frequency data coming from many different sensors, and a lot of times it’s useful to explore the frequency domain and things like data synchronization or resampling. Those can be really challenging if you’re not sure where to start.
One of the things I would say is, use the tools that are available. There’s a vast community of people working on these things, and you can find lots of examples [of applications and techniques] on GitHub or MATLAB Central, where people have shared nice examples, even little apps they’ve created. I think many of us are buried in data and just not sure what to do with it, so definitely take advantage of what’s already out there in the community. You can explore and see what makes sense to you, and bring in that balance of domain knowledge and the insight you get from the tools and AI.
What should engineers and designers consider when using AI for chip design?
Gorr: Think through what problems you’re trying to solve or what insights you might hope to find, and try to be clear about that. Consider all of the different components, and document and test each of those different parts. Consider all of the people involved, and explain and hand off in a way that is sensible for the whole team.
How do you think AI will affect chip designers’ jobs?
Gorr: It’s going to free up a lot of human capital for more advanced tasks. We can use AI to reduce waste, to optimize the materials, to optimize the design, but then you still have that human involved whenever it comes to decision-making. I think it’s a great example of people and technology working hand in hand. It’s also an industry where all people involved—even on the manufacturing floor—need to have some level of understanding of what’s happening, so this is a great industry for advancing AI because of how we test things and how we think about them before we put them on the chip.
How do you envision the future of AI and chip design?
Gorr: It’s very much dependent on that human element—involving people in the process and having that interpretable model. We can do many things with the mathematical minutiae of modeling, but it comes down to how people are using it, how everybody in the process is understanding and applying it. Communication and involvement of people of all skill levels in the process are going to be really important. We’re going to see less of those superprecise predictions and more transparency of information, sharing, and that digital twin—not only using AI but also using our human knowledge and all of the work that many people have done over the years.
-
Atomically Thin Materials Significantly Shrink Qubits
by Dexter Johnson on 07. February 2022. at 16:12

Quantum computing is a devilishly complex technology, with many technical hurdles impacting its development. Of these challenges two critical issues stand out: miniaturization and qubit quality.
IBM has adopted the superconducting qubit road map of reaching a 1,121-qubit processor by 2023, leading to the expectation that 1,000 qubits with today’s qubit form factor is feasible. However, current approaches will require very large chips (50 millimeters on a side, or larger) at the scale of small wafers, or the use of chiplets on multichip modules. While this approach will work, the aim is to attain a better path toward scalability.
Now researchers at MIT have been able to both reduce the size of the qubits and done so in a way that reduces the interference that occurs between neighboring qubits. The MIT researchers have increased the number of superconducting qubits that can be added onto a device by a factor of 100.
“We are addressing both qubit miniaturization and quality,” said William Oliver, the director for the Center for Quantum Engineering at MIT. “Unlike conventional transistor scaling, where only the number really matters, for qubits, large numbers are not sufficient, they must also be high-performance. Sacrificing performance for qubit number is not a useful trade in quantum computing. They must go hand in hand.”
The key to this big increase in qubit density and reduction of interference comes down to the use of two-dimensional materials, in particular the 2D insulator hexagonal boron nitride (hBN). The MIT researchers demonstrated that a few atomic monolayers of hBN can be stacked to form the insulator in the capacitors of a superconducting qubit.
Just like other capacitors, the capacitors in these superconducting circuits take the form of a sandwich in which an insulator material is sandwiched between two metal plates. The big difference for these capacitors is that the superconducting circuits can operate only at extremely low temperatures—less than 0.02 degrees above absolute zero (-273.15 °C).
 Superconducting qubits are measured at temperatures as low as 20 millikelvin in a dilution refrigerator.Nathan Fiske/MIT
Superconducting qubits are measured at temperatures as low as 20 millikelvin in a dilution refrigerator.Nathan Fiske/MITIn that environment, insulating materials that are available for the job, such as PE-CVD silicon oxide or silicon nitride, have quite a few defects that are too lossy for quantum computing applications. To get around these material shortcomings, most superconducting circuits use what are called coplanar capacitors. In these capacitors, the plates are positioned laterally to one another, rather than on top of one another.
As a result, the intrinsic silicon substrate below the plates and to a smaller degree the vacuum above the plates serve as the capacitor dielectric. Intrinsic silicon is chemically pure and therefore has few defects, and the large size dilutes the electric field at the plate interfaces, all of which leads to a low-loss capacitor. The lateral size of each plate in this open-face design ends up being quite large (typically 100 by 100 micrometers) in order to achieve the required capacitance.
In an effort to move away from the large lateral configuration, the MIT researchers embarked on a search for an insulator that has very few defects and is compatible with superconducting capacitor plates.
“We chose to study hBN because it is the most widely used insulator in 2D material research due to its cleanliness and chemical inertness,” said colead author Joel Wang, a research scientist in the Engineering Quantum Systems group of the MIT Research Laboratory for Electronics.
On either side of the hBN, the MIT researchers used the 2D superconducting material, niobium diselenide. One of the trickiest aspects of fabricating the capacitors was working with the niobium diselenide, which oxidizes in seconds when exposed to air, according to Wang. This necessitates that the assembly of the capacitor occur in a glove box filled with argon gas.
While this would seemingly complicate the scaling up of the production of these capacitors, Wang doesn’t regard this as a limiting factor.
“What determines the quality factor of the capacitor are the two interfaces between the two materials,” said Wang. “Once the sandwich is made, the two interfaces are “sealed” and we don’t see any noticeable degradation over time when exposed to the atmosphere.”
This lack of degradation is because around 90 percent of the electric field is contained within the sandwich structure, so the oxidation of the outer surface of the niobium diselenide does not play a significant role anymore. This ultimately makes the capacitor footprint much smaller, and it accounts for the reduction in cross talk between the neighboring qubits.
“The main challenge for scaling up the fabrication will be the wafer-scale growth of hBN and 2D superconductors like [niobium diselenide], and how one can do wafer-scale stacking of these films,” added Wang.
Wang believes that this research has shown 2D hBN to be a good insulator candidate for superconducting qubits. He says that the groundwork the MIT team has done will serve as a road map for using other hybrid 2D materials to build superconducting circuits.