

IEEE Spectrum IEEE Spectrum
-
Video Friday: Robots With Knives
by Erico Guizzo on 17. May 2024. at 10:00

Greetings from the IEEE International Conference on Robotics and Automation (ICRA) in Yokohama, Japan! We hope you’ve been enjoying our short videos on TikTok, YouTube, and Instagram. They are just a preview of our in-depth ICRA coverage, and over the next several weeks we’ll have lots of articles and videos for you. In today’s edition of Video Friday, we bring you a dozen of the most interesting projects presented at the conference.
Enjoy today’s videos, and stay tuned for more ICRA posts!
Upcoming robotics events for the next few months:
RoboCup 2024: 17–22 July 2024, EINDHOVEN, NETHERLANDS
ICSR 2024: 23–26 October 2024, ODENSE, DENMARK
Cybathlon 2024: 25–27 October 2024, ZURICH, SWITZERLAND
Please send us your events for inclusion.
The following two videos are part of the “ Cooking Robotics: Perception and Motion Planning” workshop, which explored “the new frontiers of ‘robots in cooking,’ addressing various scientific research questions, including hardware considerations, key challenges in multimodal perception, motion planning and control, experimental methodologies, and benchmarking approaches.” The workshop featured robots handling food items like cookies, burgers, and cereal, and the two robots seen in the videos below used knives to slice cucumbers and cakes. You can watch all workshop videos here.
“SliceIt!: Simulation-Based Reinforcement Learning for Compliant Robotic Food Slicing,” by Cristian C. Beltran-Hernandez, Nicolas Erbetti, and Masashi Hamaya from OMRON SINIC X Corporation, Tokyo, Japan.
Cooking robots can enhance the home experience by reducing the burden of daily chores. However, these robots must perform their tasks dexterously and safely in shared human environments, especially when handling dangerous tools such as kitchen knives. This study focuses on enabling a robot to autonomously and safely learn food-cutting tasks. More specifically, our goal is to enable a collaborative robot or industrial robot arm to perform food-slicing tasks by adapting to varying material properties using compliance control. Our approach involves using Reinforcement Learning (RL) to train a robot to compliantly manipulate a knife, by reducing the contact forces exerted by the food items and by the cutting board. However, training the robot in the real world can be inefficient, and dangerous, and result in a lot of food waste. Therefore, we proposed SliceIt!, a framework for safely and efficiently learning robot food-slicing tasks in simulation. Following a real2sim2real approach, our framework consists of collecting a few real food slicing data, calibrating our dual simulation environment (a high-fidelity cutting simulator and a robotic simulator), learning compliant control policies on the calibrated simulation environment, and finally, deploying the policies on the real robot.
“Cafe Robot: Integrated AI Skillset Based on Large Language Models,” by Jad Tarifi, Nima Asgharbeygi, Shuhei Takamatsu, and Masataka Goto from Integral AI in Tokyo, Japan, and Mountain View, Calif., USA.
The cafe robot engages in natural language inter-action to receive orders and subsequently prepares coffee and cakes. Each action involved in making these items is executed using AI skills developed by Integral, including Integral Liquid Pouring, Integral Powder Scooping, and Integral Cutting. The dialogue for making coffee, as well as the coordination of each action based on the dialogue, is facilitated by the Integral Task Planner.
“Autonomous Overhead Powerline Recharging for Uninterrupted Drone Operations,” by Viet Duong Hoang, Frederik Falk Nyboe, Nicolaj Haarhøj Malle, and Emad Ebeid from University of Southern Denmark, Odense, Denmark.
We present a fully autonomous self-recharging drone system capable of long-duration sustained operations near powerlines. The drone is equipped with a robust onboard perception and navigation system that enables it to locate powerlines and approach them for landing. A passively actuated gripping mechanism grasps the powerline cable during landing after which a control circuit regulates the magnetic field inside a split-core current transformer to provide sufficient holding force as well as battery recharging. The system is evaluated in an active outdoor three-phase powerline environment. We demonstrate multiple contiguous hours of fully autonomous uninterrupted drone operations composed of several cycles of flying, landing, recharging, and takeoff, validating the capability of extended, essentially unlimited, operational endurance.
“Learning Quadrupedal Locomotion With Impaired Joints Using Random Joint Masking,” by Mincheol Kim, Ukcheol Shin, and Jung-Yup Kim from Seoul National University of Science and Technology, Seoul, South Korea, and Robotics Institute, Carnegie Mellon University, Pittsburgh, Pa., USA.
Quadrupedal robots have played a crucial role in various environments, from structured environments to complex harsh terrains, thanks to their agile locomotion ability. However, these robots can easily lose their locomotion functionality if damaged by external accidents or internal malfunctions. In this paper, we propose a novel deep reinforcement learning framework to enable a quadrupedal robot to walk with impaired joints. The proposed framework consists of three components: 1) a random joint masking strategy for simulating impaired joint scenarios, 2) a joint state estimator to predict an implicit status of current joint condition based on past observation history, and 3) progressive curriculum learning to allow a single network to conduct both normal gait and various joint-impaired gaits. We verify that our framework enables the Unitree’s Go1 robot to walk under various impaired joint conditions in real world indoor and outdoor environments.
“Synthesizing Robust Walking Gaits via Discrete-Time Barrier Functions With Application to Multi-Contact Exoskeleton Locomotion,” by Maegan Tucker, Kejun Li, and Aaron D. Ames from Georgia Institute of Technology, Atlanta, Ga., and California Institute of Technology, Pasadena, Calif., USA.
Successfully achieving bipedal locomotion remains challenging due to real-world factors such as model uncertainty, random disturbances, and imperfect state estimation. In this work, we propose a novel metric for locomotive robustness – the estimated size of the hybrid forward invariant set associated with the step-to-step dynamics. Here, the forward invariant set can be loosely interpreted as the region of attraction for the discrete-time dynamics. We illustrate the use of this metric towards synthesizing nominal walking gaits using a simulation in-the-loop learning approach. Further, we leverage discrete time barrier functions and a sampling-based approach to approximate sets that are maximally forward invariant. Lastly, we experimentally demonstrate that this approach results in successful locomotion for both flat-foot walking and multicontact walking on the Atalante lower-body exoskeleton.
“Supernumerary Robotic Limbs to Support Post-Fall Recoveries for Astronauts,” by Erik Ballesteros, Sang-Yoep Lee, Kalind C. Carpenter, and H. Harry Asada from MIT, Cambridge, Mass., USA, and Jet Propulsion Laboratory, California Institute of Technology, Pasadena, Calif., USA.
This paper proposes the utilization of Supernumerary Robotic Limbs (SuperLimbs) for augmenting astronauts during an Extra-Vehicular Activity (EVA) in a partial-gravity environment. We investigate the effectiveness of SuperLimbs in assisting astronauts to their feet following a fall. Based on preliminary observations from a pilot human study, we categorized post-fall recoveries into a sequence of statically stable poses called “waypoints”. The paths between the waypoints can be modeled with a simplified kinetic motion applied about a specific point on the body. Following the characterization of post-fall recoveries, we designed a task-space impedance control with high damping and low stiffness, where the SuperLimbs provide an astronaut with assistance in post-fall recovery while keeping the human in-the-loop scheme. In order to validate this control scheme, a full-scale wearable analog space suit was constructed and tested with a SuperLimbs prototype. Results from the experimentation found that without assistance, astronauts would impulsively exert themselves to perform a post-fall recovery, which resulted in high energy consumption and instabilities maintaining an upright posture, concurring with prior NASA studies. When the SuperLimbs provided assistance, the astronaut’s energy consumption and deviation in their tracking as they performed a post-fall recovery was reduced considerably.
“ArrayBot: Reinforcement Learning for Generalizable Distributed Manipulation through Touch,” by Zhengrong Xue, Han Zhang, Jingwen Cheng, Zhengmao He, Yuanchen Ju, Changyi Lin, Gu Zhang, and Huazhe Xu from Tsinghua Embodied AI Lab, IIIS, Tsinghua University; Shanghai Qi Zhi Institute; Shanghai AI Lab; and Shanghai Jiao Tong University, Shanghai, China.
We present ArrayBot, a distributed manipulation system consisting of a 16 × 16 array of vertically sliding pillars integrated with tactile sensors. Functionally, ArrayBot is designed to simultaneously support, perceive, and manipulate the tabletop objects. Towards generalizable distributed manipulation, we leverage reinforcement learning (RL) algorithms for the automatic discovery of control policies. In the face of the massively redundant actions, we propose to reshape the action space by considering the spatially local action patch and the low-frequency actions in the frequency domain. With this reshaped action space, we train RL agents that can relocate diverse objects through tactile observations only. Intriguingly, we find that the discovered policy can not only generalize to unseen object shapes in the simulator but also have the ability to transfer to the physical robot without any sim-to-real fine tuning. Leveraging the deployed policy, we derive more real world manipulation skills on ArrayBot to further illustrate the distinctive merits of our proposed system.
“SKT-Hang: Hanging Everyday Objects via Object-Agnostic Semantic Keypoint Trajectory Generation,” by Chia-Liang Kuo, Yu-Wei Chao, and Yi-Ting Chen from National Yang Ming Chiao Tung University, in Taipei and Hsinchu, Taiwan, and NVIDIA.
We study the problem of hanging a wide range of grasped objects on diverse supporting items. Hanging objects is a ubiquitous task that is encountered in numerous aspects of our everyday lives. However, both the objects and supporting items can exhibit substantial variations in their shapes and structures, bringing two challenging issues: (1) determining the task-relevant geometric structures across different objects and supporting items, and (2) identifying a robust action sequence to accommodate the shape variations of supporting items. To this end, we propose Semantic Keypoint Trajectory (SKT), an object agnostic representation that is highly versatile and applicable to various everyday objects. We also propose Shape-conditioned Trajectory Deformation Network (SCTDN), a model that learns to generate SKT by deforming a template trajectory based on the task-relevant geometric structure features of the supporting items. We conduct extensive experiments and demonstrate substantial improvements in our framework over existing robot hanging methods in the success rate and inference time. Finally, our simulation-trained framework shows promising hanging results in the real world.
“TEXterity: Tactile Extrinsic deXterity,” by Antonia Bronars, Sangwoon Kim, Parag Patre, and Alberto Rodriguez from MIT and Magna International Inc.
We introduce a novel approach that combines tactile estimation and control for in-hand object manipulation. By integrating measurements from robot kinematics and an image based tactile sensor, our framework estimates and tracks object pose while simultaneously generating motion plans in a receding horizon fashion to control the pose of a grasped object. This approach consists of a discrete pose estimator that tracks the most likely sequence of object poses in a coarsely discretized grid, and a continuous pose estimator-controller to refine the pose estimate and accurately manipulate the pose of the grasped object. Our method is tested on diverse objects and configurations, achieving desired manipulation objectives and outperforming single-shot methods in estimation accuracy. The proposed approach holds potential for tasks requiring precise manipulation and limited intrinsic in-hand dexterity under visual occlusion, laying the foundation for closed loop behavior in applications such as regrasping, insertion, and tool use.
“Out of Sight, Still in Mind: Reasoning and Planning about Unobserved Objects With Video Tracking Enabled Memory Models,” by Yixuan Huang, Jialin Yuan, Chanho Kim, Pupul Pradhan, Bryan Chen, Li Fuxin, and Tucker Hermans from University of Utah, Salt Lake City, Utah, Oregon State University, Corvallis, Ore., and NVIDIA, Seattle, Wash., USA.
Robots need to have a memory of previously observed, but currently occluded objects to work reliably in realistic environments. We investigate the problem of encoding object-oriented memory into a multi-object manipulation reasoning and planning framework. We propose DOOM and LOOM, which leverage transformer relational dynamics to encode the history of trajectories given partial-view point clouds and an object discovery and tracking engine. Our approaches can perform multiple challenging tasks including reasoning with occluded objects, novel objects appearance, and object reappearance. Throughout our extensive simulation and real world experiments, we find that our approaches perform well in terms of different numbers of objects and different numbers
“Open Sourse Underwater Robot: Easys,” by Michikuni Eguchi, Koki Kato, Tatsuya Oshima, and Shunya Hara from University of Tsukuba and Osaka University, Japan.
“Sensorized Soft Skin for Dexterous Robotic Hands,” by Jana Egli, Benedek Forrai, Thomas Buchner, Jiangtao Su, Xiaodong Chen, and Robert K. Katzschmann from ETH Zurich, Switzerland, and Nanyang Technological University, Singapore.
Conventional industrial robots often use two fingered grippers or suction cups to manipulate objects or interact with the world. Because of their simplified design, they are unable to reproduce the dexterity of human hands when manipulating a wide range of objects. While the control of humanoid hands evolved greatly, hardware platforms still lack capabilities, particularly in tactile sensing and providing soft contact surfaces. In this work, we present a method that equips the skeleton of a tendon-driven humanoid hand with a soft and sensorized tactile skin. Multi-material 3D printing allows us to iteratively approach a cast skin design which preserves the robot’s dexterity in terms of range of motion and speed. We demonstrate that a soft skin enables frmer grasps and piezoresistive sensor integration enhances the hand’s tactile sensing capabilities.
-
Credentialing Adds Value to Training Programs
by Christine Cherevko on 16. May 2024. at 18:00

With careers in engineering and technology evolving so rapidly, a company’s commitment to upskilling its employees is imperative to their career growth. Maintaining the appropriate credentials—such as a certificate or digital badge that attests to successful completion of a specific set of learning objectives—can lead to increased job satisfaction, employee engagement, and higher salaries.
For many engineers, mostly in North America, completing a certain number of professional development hours and continuing-education units each year is required to maintain a professional engineering license.
Many companies have found that offering training and credentialing opportunities helps them stay competitive in today’s job marketplace. The programs encourage promotion from within—which helps reduce turnover and costly recruiting expenses for organizations. Employees with a variety of credentials are more engaged in industry-related initiatives and are more likely to take on leadership roles than their noncredentialed counterparts. Technical training programs also give employees the opportunity to enhance their technical skills and demonstrate their willingness to learn new ones.
One way to strengthen and elevate in-house technical training is through the IEEE Credentialing Program. A credential is an assurance of quality education obtained for employers and a source of pride for learners because they can share that their credentials have been verified by the world’s largest technical professional organization.
In addition to supporting engineering professionals in achieving their career goals, the certificates and digital badges available through the program help companies enhance the credibility of their training events, conferences, and courses. Also, most countries accept IEEE certificates towards their domestic continuing-education requirements for engineers.
Start earning your certificates and digital badges with these IEEE courses. Learn how your organization can offer credentials for your courses here.
-
High-Speed Rail Finally Coming to the U.S.
by Willie D. Jones on 16. May 2024. at 13:11

In late April, the Miami-based rail company Brightline Trains broke ground on a project that the company promises will give the United States its first dedicated, high-speed passenger rail service. The 350-kilometer (218-mile) corridor, which the company calls Brightline West, will connect Las Vegas to the suburbs of Los Angeles. Brightline says it hopes to complete the project in time for the 2028 Summer Olympic Games, which will take place in Los Angeles.
Brightline has chosen Siemens American Pioneer 220 engines that will run at speeds averaging 165 kilometers per hour, with an advertised top speed of 320 km/h. That average speed still falls short of the Eurostar network connecting London, Paris, Brussels, and Amsterdam (300 km/h), Germany’s Intercity-Express 3 service (330 km/h), and the world’s fastest train service, China’s Beijing-to-Shanghai regional G trains (350 km/h).
There are currently only two rail lines in the U.S. that ever reach the 200 km/h mark, which is the unofficial minimum speed at which a train can be considered to be high-speed rail. Brightline, the company that is about to construct the L.A.-to-Las-Vegas Brightline West line, also operates a Miami-Orlando rail line that averages 111 km/h. The other is Amtrak’s Acela line between Boston and Washington, D.C.—and that line only qualifies as high-speed rail for just 80 km of its 735-km route. That’s a consequence of the rail status quo in the United States, in which slower freight trains typically have right of way on shared rail infrastructure.
As Vaclav Smil, professor emeritus at the University of Manitoba, noted in IEEE Spectrum in 2018, there has long been hope that the United States would catch up with Europe, China, and Japan, where high-speed regional rail travel has long been a regular fixture. “In a rational world, one that valued convenience, time, low energy intensity and low carbon conversions, the high-speed electric train would always be the first choice for [intercity travel],” Smil wrote at the time. And yet, in the United States, funding and regulatory approval for such projects have been in short supply.
Now, Brightline West, as well as a few preexisting rail projects that are at some stage of development, such as the California High-Speed Rail Network and the Texas Central Line, could be a bellwether for an attitude shift that could—belatedly—put trains closer to equal footing with cars and planes for travelers in the continental United States.
The U.S. government, like many national governments, has pledged to reduce greenhouse gas emissions. Because that generally requires decarbonizing transportation and improving energy efficiency, trains, which can run on electricity generated from fossil-fuel as well as non-fossil-fuel sources, are getting a big push. As Smil noted in 2018, trains use a fraction of a megajoule of energy per passenger-kilometer, while a lone driver in even one of the most efficient gasoline-powered cars will use orders of magnitude more energy per passenger-kilometer.
Brightline and Siemens did not respond to inquiries by Spectrum seeking to find out what innovations they plan to introduce that would make the L.A.-to-Las Vegas passenger line run faster or perhaps use less energy than its Asian and European counterparts. But Karen E. Philbrick, executive director of the Mineta Transportation Institute at San Jose State University, in California, says that’s beside the point. She notes that the United States, having focused on cars for the better part of the past century, already missed the period when major innovations were being made in high-speed rail. “What’s important about Brightline West and, say, the California High-speed Rail project, is not how innovative they are, but the fact that they’re happening at all. I am thrilled to see the U.S. catching up.”
Maybe Brightline or other groups seeking to get Americans off the roadways and onto railways will be able to seize the moment and create high-speed rail lines connecting other intraregional population centers in the United States. With enough of those pieces in place, it might someday be possible to ride the rails from California to New York in a single day, in the same way train passengers in China can get from Beijing to Shanghai between breakfast and lunch.
-
Never Recharge Your Consumer Electronics Again?
by Stephen Cass on 15. May 2024. at 16:25

Stephen Cass: Hello and welcome to Fixing the Future, an IEEE Spectrum podcast where we look at concrete solutions to tough problems. I’m your host Stephen Cass, a senior editor at IEEE Spectrum. And before I start, I just wanted to tell you that you can get the latest coverage of Spectrum‘s most important beats, including AI, climate change, and robotics, by signing up for one of our free newsletters. Just go to spectrum.ieee.org/newsletters to subscribe.
We all love our mobile devices where the progress of Moore’s Law has meant we’re able to pack an enormous amount of computing power in something that’s small enough that we can wear it as jewelery. But their Achilles heel is power. They eat up battery life requiring frequent battery changes or charging. One company that’s hoping to reduce our battery anxiety is Exeger, which wants to enable self-charging devices that convert ambient light into energy on the go. Here to talk about its so-called Powerfoyle solar cell technology is Exeger’s founder and CEO, Giovanni Fili. Giovanni, welcome to the show.
Giovanni Fili: Thank you.
Cass: So before we get into the details of the Powerfoyle technology, was I right in saying that the Achilles heel of our mobile devices is battery life? And if we could reduce or eliminate that problem, how would that actually influence the development of mobile and wearable tech beyond just not having to recharge as often?
Fili: Yeah. I mean, for sure, I think the global common problem or pain point is for sure battery anxiety in different ways, ranging from your mobile phone to your other portable devices, and of course, even EV like cars and all that. So what we’re doing is we’re trying to eliminate this or reduce or eliminate this battery anxiety by integrating— seamlessly integrating, I should say, a solar cell. So our solar cell can convert any light energy to electrical energy. So indoor, outdoor from any angle. We’re not angle dependent. And the solar cell can take the shape. It can look like leather, textile, brushed steel, wood, carbon fiber, almost anything, and can take light from all angles as well, and can be in different colors. It’s also very durable. So our idea is to integrate this flexible, thin film into any device and allow it to be self-powered, allowing for increased functionality in the device. Just look at the smartwatches. I mean, the first one that came, you could wear them for a few hours, and you had to charge them. And they packed them with more functionality. You still have to charge them every day. And you still have to charge them every day, regardless. But now, they’re packed with even more stuff. So as soon as you get more energy efficiency, you pack them with more functionality. So we’re enabling this sort of jump in functionality without compromising design, battery, sustainability, all of that. So yeah, so it’s been a long journey since I started working with this 17 years ago.
Cass: I actually wanted to ask about that. So how is Exeger positioned to attack this problem? Because it’s not like you’re the first company to try and do nice mobile charging solutions for mobile devices.
Fili: I can mention there, I think that the main thing that differentiates us from all other previous solutions is that we have invented a new electrode material, the anode and the cathode with a similar almost like battery. So we have anode, cathode. We have electrolytes inside. So this is a—
Cass: So just for readers who might not be familiar, a battery is basically you have an anode, which is the positive terminal—I hope I didn’t forgot that—cathode, which is a negative terminal, and then you have an electrolyte between them in the battery, and then chemical reactions between these three components, and it can get kind of complicated, produce an electric potential between one side and the other. And in a solar cell, also there’s an anode and a cathode and so on. Have I got that right, my little, brief sketch?
Fili: Yeah. Yeah. Yeah. And so what we add to that architecture is we add one layer of titanium dioxide nanoparticles. Titanium dioxide is the white in white wall paint, toothpaste, sunscreen, all that. And it’s a very safe and abundant material. And we use that porous layer of titanium nanoparticles. And then we deposit a dye, a color, a pigment on this layer. And this dye can be red, black, blue, green, any kind of color. And the dye will then absorb the photons, excite electrons that are injected into the titanium dioxide layer and then collected by the anode and then conducted out to the cable. And now, we use the electrons to light the lamp or a motor or whatever we do with it. And then they turn back to the cathode on the other side and inside the cell. So the electrons goes the other way and the inner way. So the plus, you can say, go inside ions in the electrolytes. So it’s a regenerative system.
So our innovation is a new— I mean, all solar cells, they have electrodes to collect the electrons. If you have silicon wafers or whatever you have, right? And you know that all these solar cells that you’ve seen, they have silver lines crossing the surface. The silver lines are there because the conductivity is quite poor, funny enough, in these materials. So high resistance. So then you need to deposit the silver lines there, and they’re called current collectors. So you need to collect the current. Our innovation is a new electrode material that has 1,000 times better conductivity than other flexible electrode materials. That allows us as the only company in the world to eliminate the silver lines. And we print all our layers as well. And as you print in your house, you can print a photo, an apple with a bite in it, you can print the name, you can print anything you want. We can print anything we want, and it will also be converting light energy to electric energy. So a solar cell.
Cass: So the key part is that the color dye is doing that initial work of converting the light. Do different colors affect the efficiency? I did see on your site that it comes in all these kind of different colors, but. And I was thinking to myself, well, is the black one the best? Is the red one the best? Or is it relatively insensitive to the visible color that I see when I look at these dyes?
Fili: So you’re completely right there. So black would give you the most. And if you go to different colors, typically you lose like 20, 30 percent. But fortunately enough for us, over 50 percent of the consumer electronic market is black products. So that’s good. So I think that you asked me how we’re positioned. I mean, with our totally unique integration possibilities, imagine this super thin, flexible film that works all day, every day from morning to sunset, indoor, outdoor, can look like leather. So we’ve made like a leather bag, right? The leather bag is the solar cell. The entire bag is the solar cell. You wouldn’t see it. It just looks like a normal leather bag.
Cass: So when you talk about flexible, you actually mean this— so sometimes when people talk about flexible electronics, they mean it can be put into a shape, but then you’re not supposed to bend it afterwards. When you’re talking about flexible electronics, you’re talking about the entire thing remains flexible and you can use it flexibly instead of just you can conform it once to a shape and then you kind of leave it alone.
Fili: Correct. So we just recently released a hearing protector with 3M. This great American company with more than 60,000 products across the world. So we have a global exclusivity contract with them where they have integrated our bendable, flexible solar film in the headband. So the headband is the solar cell, right? And where you previously had to change disposable battery every second week, two batteries every second week, now you never need to change the battery again. We just recharge this small rechargeable battery indoor and outdoor, just continues to charge all the time. And they have added a lot of extra really cool new functionality as well. So we’re eliminating the need for disposable batteries. We’re saving millions and millions of batteries. We’re saving the end user, the contractor, the guy who uses them a lot of hassle to buy this battery, store them. And we increase reliability and functionality because they will always be charged. You can trust them that they always work. So that’s where we are totally unique. The solar cell is super durable. If we can be in a professional hearing protector to use on airports, construction sites, mines, whatever you use, factories, oil rig platforms, you can do almost anything. So I don’t think any other solar cell would be able to pass those durability tests that we did. It’s crazy.
Cass: So I have a question. It kind of it’s more appropriate from my experience with utility solar cells and things you put on roofs. But how many watts per square meter can you deliver, we’ll say, in direct sunlight?
Fili: So our focus is on indirect sunlight, like shade, suboptimal light conditions, because that’s where you would typically be with these products. But if you compare to more of a silicon, which is what you typically use for calculators and all that stuff. So we are probably around twice as what they deliver in this dark conditions, two to three times, depending. If you use glass, if you use flexible, we’re probably three times even more, but. So we don’t do full sunshine utility scale solar. But if you look at these products like the hearing protector, we have done a lot of headphones with Adidas and other huge brands, we typically recharge like four times what they use. So if you look at— if you go outside, not in full sunshine, but half sunshine, let’s say 50,000 lux, you’re probably talking at about 13, 14 minutes to charge one hour of listening. So yeah, so we have sold a few hundred thousand products over the last three years when we started selling commercially. And - I don’t know - I haven’t heard anyone who has charged since. I mean, surely someone has, but typically the user never need to charge them again, just charge themself.
Cass: Well, that’s right, because for many years, I went to CES, and I often would buy these, or acquire these, little solar cell chargers. And it was such a disappointing experience because they really would only work in direct sunlight. And even then, it would take a very long time. So I want to talk a little bit about, then, to get to that, what were some of the biggest challenges you had to overcome on the way to developing this tech?
Fili: I mean, this is the fourth commercial solar cell technology in the world after 110 or something years of research. I mean, the Americans, the Bell Laboratory sent the first silicon cell, I think it’s in like 1955 or something, to space. And then there’s been this constant development and trying to find, but to develop a new energy source is as close to impossible as you get, more or less. Everybody tried and everybody failed. We didn’t know that, luckily enough. So just the whole-- so when I try to explain this, I get this question quite a lot. Imagine you found out something really cool, but there’s no one to ask. There’s no book to read. You just realize, “Okay, I have to make like hundreds of thousands, maybe millions of experiments to learn. And all of them, except finally one, they will all fail. But that’s okay.” You will fail, fail, fail. And then, “Oh, here’s the solution. Something that works. Okay. Good.” So we had to build on just constant failing, but it’s okay because you’re in a research phase. So we had to. I mean, we started off with this new nanomaterials, and then we had to make components of these materials. And then we had to make solar cells of the components, but there were no machines either. We have had to invent all the machines from scratch as well to make these components and the solar cells and some of the non-materials. That was also tough. How do you design a machine for something that doesn’t exist? It’s pretty difficult specification to give to a machine builder. So in the end, we had to build our own machine building capacity here. We’re like 50 guys building machines, so.
But now, I mean, today we have over 300 granted patents, another 90 that will be approved soon. We have a complete machine park that’s proprietary. We are now building the largest solar cell factory— one of the largest solar cell factories in Europe. It’s already operational, phase one. Now we’re expanding into phase two. And we’re completely vertically integrated. We don’t source anything from Russia, China; never did. Only US, Japan, and Europe. We run the factories on 100 percent renewable energy. We have zero emissions to air and water. And we don’t have any rare earth metals, no strange stuff in it. It’s like it all worked out. And now we have signed, like I said, global exclusivity deal with 3M. We have a global exclusivity deal with the largest company in the world on computer peripherals, like mouse, keyboard, that stuff. They can only work with us for years. We have signed one of the large, the big fives, the Americans, the huge CE company. Can’t tell you yet the name. We have a globally exclusive deal for electronic shelf labels, the small price tags in the stores. So we have a global solution with Vision Group, that’s the largest. They have 50 percent of the world market as well. And they have Walmart, IKEA, Target, all these huge companies. So now it’s happening. So we’re rolling out, starting to deploy massive volumes later this year.
Cass:So I’ll talk a little bit about that commercial experience because you talked about you had to create verticals. I mean, in Spectrum, we do cover other startups which have had these— they’re kind of starting from scratch. And they develop a technology, and it’s a great demo technology. But then it comes that point where you’re trying to integrate in as a supplier or as a technology partner with a large commercial entity, which has very specific ideas and how things are to be manufactured and delivered and so on. So can you talk a little bit about what it was like adapting to these partners like 3M and what changes you had to make and what things you learned in that process where you go from, “Okay, we have a great product and we could make our own small products, but we want to now connect in as part of this larger supply chain.”
Fili: It’s a very good question and it’s extremely tough. It’s a tough journey, right? Like to your point, these are the largest companies in the world. They have their way. And one of the first really tough lessons that we learned was that one factory wasn’t enough. We had to build two factories to have redundancy in manufacturing. Because single source is bad. Single source, single factory, that’s really bad. So we had to build two factories and we had to show them we were ready, willing and able to be a supplier to them. Because one thing is the product, right? But the second thing is, are you worthy supplier? And that means how much money you have in the bank. Are you going to be here in two, three, four years? What’s your ISO certifications like? REACH, RoHS, Prop 65. What’s your LCA? What’s your view on this? Blah, blah, blah. Do you have professional supply chain? Did you do audits on your suppliers? But now, I mean, we’ve had audits here by five of the largest companies in the world. We’ve all passed them. And so then you qualify as a worthy supplier. Then comes your product integration work, like you mentioned. And I think it’s a lot about— I mean, that’s our main feature. The main unique selling point with Exeger is that we can integrate into other people’s products. Because when you develop this kind of crazy technology-- “Okay, so this is solar cell. Wow. Okay.” And it can look like anything. And it works all the time. And all the other stuff is sustainable and all that. Which product do you go for? So I asked myself—I’m an entrepreneur since the age of 15. I’ve started a number of companies. I lost so much money. I can’t believe it. And managed to earn a little bit more. But I realized, “Okay, how do you select? Where do you start? Which product?”
Okay, so I sat down. I was like, “When does it sell well? When do you see market success?” When something is important. When something is important, it’s going to work. It’s not the best tech. It has to be important enough. And then, you need distribution and scale and all that. Okay, how do you know if something is important? You can’t. Okay. What if you take something that’s already is— I mean, something new, you can’t know if it’s going to work. But if we can integrate into something that’s already selling in the billions of units per year, like headphones— I think this year, one billion headphones are going to be sold or something. Okay, apparently, obviously that’s important for people. Okay, let’s develop technology that can be integrated into something that’s already important and allow it to stay, keep all the good stuff, the design, the weight, the thickness, all of that, even improve the LCA better for the environment. And it’s self-powered. And it will allow the user to participate and help a little bit to a better world, right? With no charge cable, no charging in the wall, less batteries and all that. So our strategy was to develop such a strong technology so that we could integrate into these companies/partners products.
Cass: So I guess the question there is— so you come to a company, the company has its own internal development engineers. It’s got its own people coming up with product ideas and so on. How do you evangelize within a company to say, “Look, you get in the door, you show your demo,” to say, product manager who’s thinking of new product lines, “You guys should think about making products with our technology.” How do you evangelize that they think, “Okay, yeah, I’m going to spend the next six months of my life betting on these headphones, on this technology that I didn’t invent that I’m kind of trusting.” How do you get that internal buy-in with the internal engineers and the internal product developers and product managers?
Fili: That’s the Holy Grail, right? It’s very, very, very difficult. Takes a lot of time. It’s very expensive. And the point, I think you’re touching a little bit when you’re asking me now, because they don’t have a guy waiting to buy or a division or department waiting to buy this flexible indoor solar cell that can look like leather. They don’t have anyone. Who’s going to buy? Who’s the decision maker? There is not one. There’s a bunch, right? Because this will affect the battery people. This will affect the antenna people. This will affect the branding people. It will affect the mechanic people, etc., etc., etc. So there’s so many people that can say no. No one can say yes alone. All of them can say no alone. Any one of them can block the project, but to proceed, all of them have to say yes. So it’s a very, very tough equation. So that’s why when we realized this— this was another big learning that we had that we couldn’t go with the sales guy. We couldn’t go with two sales guys. We had to go with an entire team. So we needed to bring our design guy, our branding person, our mechanics person, our software engineer. We had to go like huge teams to be able to answer all the questions and mitigate and explain.
So we had to go both top down and explain to the head of product or head of sustainability, “Okay, if you have 100 million products out in five years and they’re going to be using 50 batteries per year, that’s 5 billion batteries per year. That’s not good, right? What if we can eliminate all these batteries? That’s good for sustainability.” “Okay. Good.” “That’s also good for total cost. We can lower total cost of ownership.” “Okay, that’s also good.” “And you can sell this and this and this way. And by the way, here’s a narrative we offer you. We have also made some assets, movies, pictures, texts. This is how other people talk about this.” But it’s a very, very tough start. How do you get the first big name in? And big companies, they have a lot to risk, a lot to lose as well. So my advice would be to start smaller. I mean, we started mainly due to COVID, to be honest. Because Sweden stayed open during COVID, which was great. We lived our lives almost like normal. But we couldn’t work with any international companies because they were all closed or no one went to the office. So we had to turn to Swedish companies, and we developed a few products during COVID. We launched like four or five products on the market with smaller Swedish companies, and we launched so much. And then we could just send these headphones to the large companies and tell them, “You know what? Here’s a headphone. Use it for a few months. We’ll call you later.” And then they call us that, “You know what? We have used them for three months. No one has charged. This is sick. It actually works.” We’re like, “Yeah, we know.” And then that just made it so much easier. And now anyone who wants to make a deal with us, they can just buy these products anywhere online or in-store across the whole world and try them for themselves.
And we send them also samples. They can buy, they can order from our website, like development kits. We have software, we have partnered up with Qualcomm, early semiconductor. All the big electronics companies, we’re now qualified partners with them. So all the electronics is powerful already. So now it’s very easy now to build prototypes if you want to test something. We have offices across the world. So now it’s much easier. But my advice to anyone who would want to start with this is try and get a few customers in. The important thing is that they also care about the project. If we go to one of these large companies, 3M, they have 60,000 products. If they have 60,001, yeah. But for us, it’s like the project. And we have managed to land it in a way. So it’s also important for them now because it just touches so many of their important areas that they work with, so.
Cass: So in terms of future directions for the technology, do you have a development pathway? What kind of future milestones are you hoping to hit?
Fili: For sure. So at the moment, we’re focusing on consumer electronics market, IoT, smart home. So I think the next big thing will be the smart workplace where you see huge construction sites and other areas where we connect the workers, anything from the smart helmet. You get hit in your head, how hard was it? I mean, why can’t we tell you that? That’s just ridiculous. There’s all these sensors already available. Someone just needs to power the helmet. Location services. Is the right person in the right place with the proper training or not? On the construction side, do you have the training to work with dynamite, for example, or heavy lifts or different stuff? So you can add the geofencing in different sites. You can add health data, digital health tracking, pulse, breathing, temperature, different stuff. Compliance, of course. Are you following all the rules? Are you wearing your helmet? Is the helmet buttoned? Are you wearing the proper other gear, whatever it is? Otherwise, you can’t start your engine, or you can’t go into this site, or you can’t whatever. I think that’s going to greatly improve the proactive safety and health a lot and increase profits for employers a lot too at the same time. In a few years, I think we’re going to see the American unions are going to be our best sales force. Because when they see the greatness of this whole system, they’re going to demand it in all tenders, all biggest projects. They’re going to say, “Hey, we want to have the connected worker safety stuff here.” Because you can just stream-- if you’re working, you can stream music, talk to your colleagues, enjoy connected safety without invading the privacy, knowing that you’re good. If you fall over, if you faint, if you get a heart attack, whatever, in a few seconds, the right people will know and they will take their appropriate actions. It’s just really, really cool, this stuff.
Cass: Well, it’ll be interesting to see how that turns out. But I’m afraid that’s all we have time for today, although this is fascinating. But today, so Giovanni, I want to thank you very much for coming on the show.
Fili: Thank you so much for having me.
Cass: So today we were talking with Giovanni Fili, who is Exeger’s founder and CEO, about their new flexible powerfoyle solar cell technology. For IEEE Spectrum‘s Fixing the Future, I’m Stephen Cass, and I hope you’ll join me next time.
-
How to Put a Data Center in a Shoebox
by Anna Herr on 15. May 2024. at 15:00

Scientists have predicted that by 2040, almost 50 percent of the world’s electric power will be used in computing. What’s more, this projection was made before the sudden explosion of generative AI. The amount of computing resources used to train the largest AI models has been doubling roughly every 6 months for more than the past decade. At this rate, by 2030 training a single artificial-intelligence model would take one hundred times as much computing resources as the combined annual resources of the current top ten supercomputers. Simply put, computing will require colossal amounts of power, soon exceeding what our planet can provide.
One way to manage the unsustainable energy requirements of the computing sector is to fundamentally change the way we compute. Superconductors could let us do just that.
Superconductors offer the possibility of drastically lowering energy consumption because they do not dissipate energy when passing current. True, superconductors work only at cryogenic temperatures, requiring some cooling overhead. But in exchange, they offer virtually zero-resistance interconnects, digital logic built on ultrashort pulses that require minimal energy, and the capacity for incredible computing density due to easy 3D chip stacking.
Are the advantages enough to overcome the cost of cryogenic cooling? Our work suggests they most certainly are. As the scale of computing resources gets larger, the marginal cost of the cooling overhead gets smaller. Our research shows that starting at around 1016 floating-point operations per second (tens of petaflops) the superconducting computer handily becomes more power efficient than its classical cousin. This is exactly the scale of typical high-performance computers today, so the time for a superconducting supercomputer is now.
At Imec, we have spent the past two years developing superconducting processing units that can be manufactured using standard CMOS tools. A processor based on this work would be one hundred times as energy efficient as the most efficient chips today, and it would lead to a computer that fits a data-center’s worth of computing resources into a system the size of a shoebox.
The Physics of Energy-Efficient Computation
Superconductivity—that superpower that allows certain materials to transmit electricity without resistance at low enough temperatures—was discovered back in 1911, and the idea of using it for computing has been around since the mid-1950s. But despite the promise of lower power usage and higher compute density, the technology couldn’t compete with the astounding advance of CMOS scaling under Moore’s Law. Research has continued through the decades, with a superconducting CPU demonstrated by a group at Yokohama National University as recently as 2020. However, as an aid to computing, superconductivity has stayed largely confined to the laboratory.
To bring this technology out of the lab and toward a scalable design that stands a chance of being competitive in the real world, we had to change our approach here at Imec. Instead of inventing a system from the bottom up—that is, starting with what works in a physics lab and hoping it is useful—we designed it from the top down—starting with the necessary functionality, and working directly with CMOS engineers and a full-stack development team to ensure manufacturability. The team worked not only on a fabrication process, but also software architectures, logic gates, and standard-cell libraries of logic and memory elements to build a complete technology.
The foundational ideas behind energy-efficient computation, however, have been developed as far back as 1991. In conventional processors, much of the power consumed and heat dissipated comes from moving information among logic units, or between logic and memory elements rather than from actual operations. Interconnects made of superconducting material, however, do not dissipate any energy. The wires have zero electrical resistance, and therefore, little energy is required to move bits within the processor. This property of having extremely low energy losses holds true even at very high communication frequencies, where losses would skyrocket ordinary interconnects.
Further energy savings come from the way logic is done inside the superconducting computer. Instead of the transistor, the basic element in superconducting logic is the Josephson-junction.
A Josephson junction is a sandwich—a thin slice of insulating material squeezed between two superconductors. Connect the two superconductors, and you have yourself a Josephson-junction loop.
Under normal conditions, the insulating “meat” in the sandwich is so thin that it does not deter a supercurrent—the whole sandwich just acts as a superconductor. However, if you ramp up the current past a threshold known as a critical current, the superconducting “bread slices” around the insulator get briefly knocked out of their superconducting state. In this transition period, the junction emits a tiny voltage pulse, lasting just a picosecond and dissipating just 2 x 10-20 joules, a hundred-billionth of what it takes to write a single bit of information into conventional flash memory.
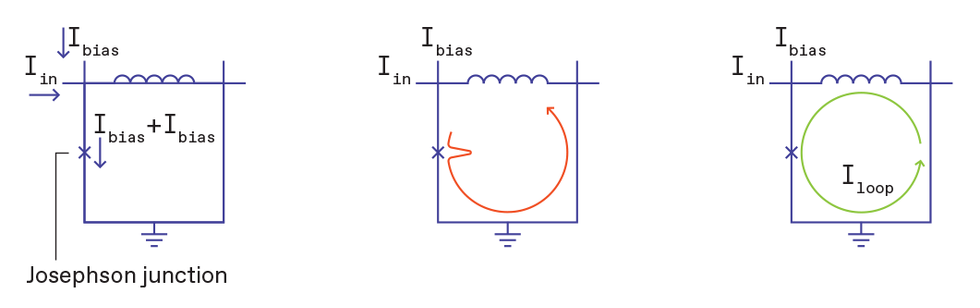 A single flux quantum develops in a Josephson-junction loop via a three-step process. First, a current just above the critical value is passed through the junction. The junction then emits a single-flux-quantum voltage pulse. The voltage pulse passes through the inductor, creating a persistent current in the loop. A Josephson junction is indicated by an x on circuit diagrams. Chris Philpot
A single flux quantum develops in a Josephson-junction loop via a three-step process. First, a current just above the critical value is passed through the junction. The junction then emits a single-flux-quantum voltage pulse. The voltage pulse passes through the inductor, creating a persistent current in the loop. A Josephson junction is indicated by an x on circuit diagrams. Chris PhilpotThe key is that, due to a phenomenon called magnetic flux quantization in the superconducting loop, this pulse is always exactly the same. It is known as a “single flux quantum” (SFQ) of magnetic flux, and it is fixed to have a value of 2.07 millivolt-picoseconds. Put an inductor inside the Josephson-junction loop, and the voltage pulse drives a current. Since the loop is superconducting, this current will continue going around the loop indefinitely, without using any further energy.
Logical operations inside the superconducting computer are made by manipulating these tiny, quantized voltage pulses. A Josephson-junction loop with an SFQ’s worth of persistent current acts as a logical 1, while a current-free loop is a logical 0.
To store information, the Josephson-junction-based version of SRAM in CPU cache, also uses single flux quanta. To store one bit, two Josephson-junction loops need to be placed next to each other. An SFQ with a persistent current in the left-hand loop is a memory element storing a logical 0, whereas no current in the left but a current in the right loop is a logical 1.
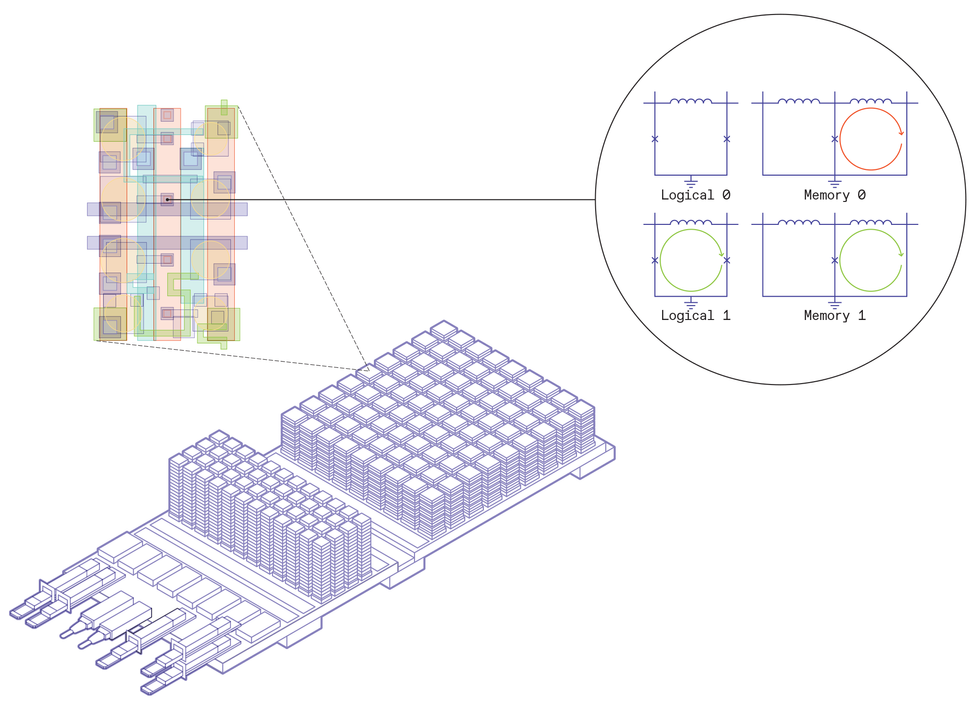 Designing a superconductor-based data center required full-stack innovation. Imec’s board design contains three main elements: the input and output, leading data to the room temperature world, the conventional DRAM, stacked high and cooled to 77 kelvins, and the superconducting processing units, also stacked, and cooled to 4 K. Inside the superconducting processing unit, basic logic and memory elements are laid out to perform computations. A magnification of the chip shows the basic building blocks: For logic, a Josephson-junction loop without a persistent current indicates a logical 0, while a loop with one single flux quantum’s worth of current represents a logical 1. For memory, two Josephson junction loops are connected together. An SFQ’s worth of persistent current in the left loop is a memory 0, and a current in the right loop is a memory 1. Chris Philpot
Designing a superconductor-based data center required full-stack innovation. Imec’s board design contains three main elements: the input and output, leading data to the room temperature world, the conventional DRAM, stacked high and cooled to 77 kelvins, and the superconducting processing units, also stacked, and cooled to 4 K. Inside the superconducting processing unit, basic logic and memory elements are laid out to perform computations. A magnification of the chip shows the basic building blocks: For logic, a Josephson-junction loop without a persistent current indicates a logical 0, while a loop with one single flux quantum’s worth of current represents a logical 1. For memory, two Josephson junction loops are connected together. An SFQ’s worth of persistent current in the left loop is a memory 0, and a current in the right loop is a memory 1. Chris PhilpotProgress Through Full-Stack Development
To go from a lab curiosity to a chip prototype ready for fabrication, we had to innovate the full stack of hardware. This came in three main layers: engineering the basic materials used, circuit development, and architectural design. The three layers had to go together—a new set of materials requires new circuit designs, and new circuit designs require novel architectures to incorporate them. Codevelopment across all three stages, with a strict adherence to CMOS manufacturing capabilities, was the key to success.
At the materials level, we had to step away from the previous lab-favorite superconducting material: niobium. While niobium is easy to model and behaves very well under predictable lab conditions, it is very difficult to scale down. Niobium is sensitive to both process temperature and its surrounding materials, so it is not compatible with standard CMOS processing. Therefore, we switched to the related compound niobium titanium nitride for our basic superconducting material. Niobium titanium nitride can withstand temperatures used in CMOS fabrication without losing its superconducting capabilities, and it reacts much less with its surrounding layers, making it a much more practical choice.
 The basic building block of superconducting logic and memory is the Josephson junction. At Imec, these junctions have been manufactured using a new set of materials, allowing the team to scale down the technology without losing functionality. Here, a tunneling electron microscope image shows a Josephson junction made with alpha-silicon insulator sandwiched between niobium titanium nitride superconductors, achieving a critical dimension of 210 nanometers. Imec
The basic building block of superconducting logic and memory is the Josephson junction. At Imec, these junctions have been manufactured using a new set of materials, allowing the team to scale down the technology without losing functionality. Here, a tunneling electron microscope image shows a Josephson junction made with alpha-silicon insulator sandwiched between niobium titanium nitride superconductors, achieving a critical dimension of 210 nanometers. ImecAdditionally, we employed a new material for the meat layer of the Josephson-junction sandwich—amorphous, or alpha, silicon. Conventional Josephson-junction materials, most notably aluminum oxide, didn’t scale down well. Aluminum was used because it “wets” the niobium, smoothing the surface, and the oxide was grown in a well-controlled manner. However, to get to the ultrahigh densities that we are targeting, we would have to make the oxide too thin to be practically manufacturable. Alpha silicon, in contrast, allowed us to use a much thicker barrier for the same critical current.
We also had to devise a new way to power the Josephson junctions that would scale down to the size of a chip. Previously, lab-based superconducting computers used transformers to deliver current to their circuit elements. However, having a bulky transformer near each circuit element is unworkable. Instead, we designed a way to deliver power to all the elements on the chip at once by creating a resonant circuit, with specialized capacitors interspersed throughout the chip.
At the circuit level, we had to redesign the entire logic and memory structure to take advantage of the new materials’ capabilities. We designed a novel logic architecture that we call pulse-conserving logic. The key requirement for pulse-conserving logic is that the elements have as many inputs as outputs and that the total number of single flux quanta is conserved. The logic is performed by routing the SFQs through a combination of Josephson-junction loops and inductors to the appropriate outputs, resulting in logical ORs and ANDs. To complement the logic architecture, we also redesigned a compatible Josephson-junction-based SRAM.
Lastly, we had to make architectural innovations to take full advantage of the novel materials and circuit designs. Among these was cooling conventional silicon DRAM down to 77 kelvins and designing a glass bridge between the 77-K section and the main superconducting section. The bridge houses thin wires that allow communication without thermal mixing. We also came up with a way of stacking chips on top of each other and are developing vertical superconducting interconnects to link between circuit boards.
A Data Center the Size of a Shoebox
The result is a superconductor-based chip design that’s optimized for AI processing. A zoom in on one of its boards reveals many similarities with a typical 3D CMOS system-on-chip. The board is populated by computational chips: We call it a superconductor processing unit (SPU), with embedded superconducting SRAM, DRAM memory stacks, and switches, all interconnected on silicon interposer or on glass-bridge advanced packaging technologies.
But there are also some striking differences. First, most of the chip is to be submerged in liquid helium for cooling to a mere 4 K. This includes the SPUs and SRAM, which depend on superconducting logic rather than CMOS, and are housed on an interposer board. Next, there is a glass bridge to a warmer area, a balmy 77 K that hosts the DRAM. The DRAM technology is not superconducting, but conventional silicon cooled down from room temperature, making it more efficient. From there, bespoke connectors lead data to and from the room-temperature world.
 Davide Comai
Davide ComaiMoore’s law relies on fitting progressively more computing resources into the same space. As scaling down transistors gets more and more difficult, the semiconductor industry is turning toward 3D stacking of chips to keep up the density gains. In classical CMOS-based technology, it is very challenging to stack computational chips on top of each other because of the large amount of power, and therefore heat, that is dissipated within the chips. In superconducting technology, the little power that is dissipated is easily removed by the liquid helium. Logic chips can be directly stacked using advanced 3D integration technologies resulting in shorter and faster connections between the chips, and a smaller footprint.
It is also straightforward to stack multiple boards of 3D superconducting chips on top of each other, leaving only a small space between them. We modeled a stack of 100 such boards, all operating within the same cooling environment and contained in a 20- by 20- by 12-centimeter volume, roughly the size of a shoebox. We calculated that this stack can perform 20 exaflops (in BF16 number format), 20 times the capacity of the largest supercomputer today. What’s more, the system promises to consume only 500 kilowatts of total power. This translates to energy efficiency one hundred times as high as the most efficient supercomputer today.
So far, we’ve scaled down Josephson junctions and interconnect dimensions over three succeeding generations. Going forward, Imec’s road map includes tackling 3D superconducting chip-integration and cooling technologies. For the first generation, the road map envisions the stacking of about 100 boards to obtain the target performance of 20 exaflops. Gradually, more and more logic chips will be stacked, and the number of boards will be reduced. This will further increase performance while reducing complexity and cost.
The Superconducting Vision
We don’t envision that superconducting digital technology will replace conventional CMOS computing, but we do expect it to complement CMOS for specific applications and fuel innovations in new ones. For one, this technology would integrate seamlessly with quantum computers that are also built upon superconducting technology. Perhaps more significantly, we believe it will support the growth in AI and machine learning processing and help provide cloud-based training of big AI models in a much more sustainable way than is currently possible.
In addition, with this technology we can engineer data centers with much smaller footprints. Drastically smaller data centers can be placed close to their target applications, rather than being in some far-off football-stadium-size facility.
Such transformative server technology is a dream for scientists. It opens doors to online training of AI models on real data that are part of an actively changing environment. Take potential robotic farms as an example. Today, training these would be a challenging task, where the required processing capabilities are available only in far-away, power-hungry data centers. With compact, nearby data centers, the data could be processed at once, allowing an AI to learn from current conditions on the farm
Similarly, these miniature data centers can be interspersed in energy grids, learning right away at each node and distributing electricity more efficiently throughout the world. Imagine smart cities, mobile health care systems, manufacturing, farming, and more, all benefiting from instant feedback from adjacent AI learners, optimizing and improving decision making in real time.
-
This Member Gets a Charge from Promoting Sustainability
by Joanna Goodrich on 14. May 2024. at 18:00

Ever since she was an undergraduate student in Turkey, Simay Akar has been interested in renewable energy technology. As she progressed through her career after school, she chose not to develop the technology herself but to promote it. She has held marketing positions with major energy companies, and now she runs two startups.
One of Akar’s companies develops and manufactures lithium-ion batteries and recycles them. The other consults with businesses to help them achieve their sustainability goals.
Simay Akar
Employer
AK Energy Consulting
Title
CEO
Member grade
Senior member
Alma mater
Middle East Technical University in Ankara, Turkey
“I love the industry and the people in this business,” Akar says. “They are passionate about renewable energy and want their work to make a difference.”
Akar, a senior member, has become an active IEEE volunteer as well, holding leadership positions. First she served as student branch coordinator, then as a student chapter coordinator, and then as a member of several administrative bodies including the IEEE Young Professionals committee.
Akar received this year’s IEEE Theodore W. Hissey Outstanding Young Professional Award for her “leadership and inspiration of young professionals with significant contributions in the technical fields of photovoltaics and sustainable energy storage.” The award is sponsored by IEEE Young Professionals and the IEEE Photonics and Power & Energy societies.
Akar says she’s honored to get the award because “Theodore W. Hissey’s commitment to supporting young professionals across all of IEEE’s vast fields is truly commendable.” Hissey, who died in 2023, was an IEEE Life Fellow and IEEE director emeritus who supported the IEEE Young Professionals community for years.
“This award acknowledges the potential we hold to make a significant impact,” Akar says, “and it motivates me to keep pushing the boundaries in sustainable energy and inspire others to do the same.”
A career in sustainable technology
After graduating with a degree in the social impact of technology from Middle East Technical University, in Ankara, Turkey, Akar worked at several energy companies. Among them was Talesun Solar in Suzhou, China, where she was head of overseas marketing. She left to become the sales and marketing director for Eko Renewable Energy, in Istanbul.
In 2020 she founded Innoses in Shanghai. The company makes batteries for electric vehicles and customizes them for commercial, residential, and off-grid renewable energy systems such as solar panels. Additionally, Innoses recycles lithium-ion batteries, which otherwise end up in landfills, leaching hazardous chemicals.
“Recycling batteries helps cut down on pollution and greenhouse gas emissions,” Akar says. “That’s something we can all feel good about.”
She says there are two main methods of recycling batteries: melting and shredding.
Melting batteries is done by heating them until their parts separate. Valuable metals including cobalt and nickel are collected and cleaned to be reused in new batteries.
A shredding machine with high-speed rotating blades cuts batteries into small pieces. The different components are separated and treated with solutions to break them down further. Lithium, copper, and other metals are collected and cleaned to be reused.
The melting method tends to be better for collecting cobalt and nickel, while shredding is better for recovering lithium and copper, Akar says.
“This happens because each method focuses on different parts of the battery, so some metals are easier to extract depending on how they are processed,” she says. The chosen method depends on factors such as the composition of the batteries, the efficiency of the recycling process, and the desired metals to be recovered.
“There are a lot of environmental concerns related to battery usage,” Akar says. “But, if the right recycling process can be completed, batteries can also be sustainable. The right process could keep pollution and emissions low and protect the health of workers and surrounding communities.”
 Akar worked at several energy companies including Talesun Solar in Suzhou, China, which manufactures solar cells like the one she is holding.Simay Akar
Akar worked at several energy companies including Talesun Solar in Suzhou, China, which manufactures solar cells like the one she is holding.Simay AkarHelping businesses with sustainability
After noticing many businesses were struggling to become more sustainable, in 2021 Akar founded AK Energy Consulting in Istanbul. Through discussions with company leaders, she found they “need guidance and support from someone who understands not only sustainable technology but also the best way renewable energy can help the planet,” she says.
“My goal for the firm is simple: Be a force for change and create a future that’s sustainable and prosperous for everyone,” she says.
Akar and her staff meet with business leaders to better understand their sustainability goals. They identify areas where companies can improve, assess the impact the recommended changes can have, and research the latest sustainable technology. Her consulting firm also helps businesses understand how to meet government compliance regulations.
“By embracing sustainability, companies can create positive social, environmental, and economic impact while thriving in a rapidly changing world,” Akar says. “The best part of my job is seeing real change happen. Watching my clients switch to renewable energy, adopt eco-friendly practices, and hit their green goals is like a pat on the back.”
Serving on IEEE boards and committees
Akar has been a dedicated IEEE volunteer since joining the organization in 2007 as an undergraduate student and serving as chair of her school’s student branch. After graduating, she held other roles including Region 8 student branch coordinator, student chapter coordinator, and the region’s IEEE Women in Engineering committee chair.
In her nearly 20 years as a volunteer, Akar has been a member of several IEEE boards and committees including the Young Professionals committee, the Technical Activities Board, and the Nominations and Appointments Committee for top-level positions.
She is an active member of the IEEE Power & Energy Society and is a former IEEE PES liaison to the Women in Engineering committee. She is also a past vice chair of the society’s Women in Power group, which supports career advancement and education and provides networking opportunities.
“My volunteering experiences have helped me gain a deep understanding of how IEEE operates,” she says. “I’ve accumulated invaluable knowledge, and the work I’ve done has been incredibly fulfilling.”
As a member of the IEEE–Eta Kappa Nu honor society, Akar has mentored members of the next generation of technologists. She also served as a mentor in the IEEE Member and Geographic Activities Volunteer Leadership Training Program, which provides members with resources and an overview of IEEE, including its culture and mission. The program also offers participants training in management and leadership skills.
Akar says her experiences as an IEEE member have helped shape her career. When she transitioned from working as a marketer to being an entrepreneur, she joined IEEE Entrepreneurship, eventually serving as its vice chair of products. She also was chair of the Region 10 entrepreneurship committee.
“I had engineers I could talk to about emerging technologies and how to make a difference through Innoses,” she says. “I also received a lot of support from the group.”
Akar says she is committed to IEEE’s mission of advancing technology for humanity. She currently chairs the IEEE Humanitarian Technology Board’s best practices and projects committee. She also is chair of the IEEE MOVE global committee. The mobile outreach vehicle program provides communities affected by natural disasters with power and Internet access.
“Through my leadership,” Akar says, “I hope to contribute to the development of innovative solutions that improve the well-being of communities worldwide.”
-
Startup Sends Bluetooth Into Low Earth Orbit
by Margo Anderson on 13. May 2024. at 19:54

A recent Bluetooth connection between a device on Earth and a satellite in orbit signals a potential new space race—this time, for global location-tracking networks.
Seattle-based startup Hubble Network announced today that it had a letter of understanding with San Francisco-based startup Life360 to develop a global, satellite-based Internet of Things (IoT) tracking system. The announcement follows on the heels of a 29 April announcement from Hubble Network that it had established the first Bluetooth connection between a device on Earth and a satellite. The pair of announcements sets the stage for an IoT tracking system that aims to rival Apple’s AirTags, Samsung’s Galaxy SmartTag2, and the Cube GPS Tracker.
Bluetooth, the wireless technology that connects home speakers and earbuds to phones, typically traverses meters, not hundreds of kilometers (520 km, in the case of Hubble Network’s two orbiting satellites). The trick to extending the tech’s range, Hubble Network says, lies in the startup’s patented, high-sensitivity signal detection system on a LEO satellite.
“We believe this is comparable to when GPS was first made available for public use.” —Alex Haro, Hubble Network
The caveat, however, is that the connection is device-to-satellite only. The satellite can’t ping devices back on Earth to say “signal received,” for example. This is because location-tracking tags operate on tiny energy budgets—often powered by button-sized batteries and running on a single charge for months or even years at a stretch. Tags are also able to perform only minimal signal processing. That means that tracking devices cannot include the sensitive phased-array antennas and digital beamforming needed to tease out a vanishingly tiny Bluetooth signal racing through the stratosphere.
“There is a massive enterprise and industrial market for ‘send only’ applications,” says Alex Haro, CEO of Hubble Network. “Once deployed, these sensors and devices don’t need Internet connectivity except to send out their location and telemetry data, such as temperature, humidity, shock, and moisture. Hubble enables sensors and asset trackers to be deployed globally in a very battery- and cost-efficient manner.”
Other applications for the company’s technologies, Haro says, include asset tracking, environmental monitoring, container and pallet tracking, predictive maintenance, smart agriculture applications, fleet management, smart buildings, and electrical grid monitoring.
“To give you a sense of how much better Hubble Network is compared to existing satellite providers like Globalstar,” Haro says, “We are 50 times cheaper and have 20 times longer battery life. For example, we can build a Tile device that is locatable anywhere in the world without any cellular reception and lasts for years on a single coin cell battery. This will be a game-changer in the AirTag market for consumers.”
 Hubble Network chief space officer John Kim (left) and two company engineers perform tests on the company’s signal-sensing satellite technology. Hubble Network
Hubble Network chief space officer John Kim (left) and two company engineers perform tests on the company’s signal-sensing satellite technology. Hubble NetworkThe Hubble Network system—and presumably the enhanced Life360 Tags that should follow today’s announcement—use a lower energy iteration of the familiar Bluetooth wireless protocol.
Like its more famous cousin, Bluetooth Low-Energy (BLE) uses the 2.4 gigahertz band—a globally unlicensed spectrum band that many Wi-Fi routers, microwave ovens, baby monitors, wireless microphones, and other consumer devices also use.
Haro says BLE offered the most compelling, supposedly “short-range” wireless standard for Hubble Network’s purposes. By contrast, he says, the long-range, wide-area network LoRaWAN operates on a communications band, 900 megahertz, that some countries and regions regulate differently from others—making a potentially global standard around it that much more difficult to establish and maintain. Plus, he says, 2.4 GHz antennas can be roughly one-third the size of a standard LoRaWAN antenna, which makes a difference when launching material into space, when every gram matters.
Haro says that Hubble Network’s technology does require changing the sending device’s software in order to communicate with a BLE receiver satellite in orbit. And it doesn’t require any hardware modifications of the device, save one—adding a standard BLE antenna. “This is the first time that a Bluetooth chip can send data from the ground to a satellite in orbit,” Haro says. “We require the Hubble software stack loaded onto the chip to make this possible, but no physical modifications are needed. Off-the-shelf BLE chips are now capable of communicating directly with LEO satellites.”
“We believe this is comparable to when GPS was first made available for public use,” Haro adds. “It was a groundbreaking moment in technology history that significantly impacted everyday users in ways previously unavailable.”
What remains, of course, is the next hardest part: Launching all of the satellites needed to create a globally available tracking network. As to whether other companies or countries will be developing their own competitor technologies, now that Bluetooth has been revealed to have long-range communication capabilities, Haro did not speculate beyond what he envisions for his own company’s LEO ambitions.
“We currently have our first two satellites in orbit as of 4 March,” Haro says. “We plan to continue launching more satellites, aiming to have 32 in orbit by early 2026. Our pilot customers are already updating and testing their devices on our network, and we will continue to scale our constellation over the next 3 to 5 years.”
-
Disney's Robots Use Rockets to Stick the Landing
by Morgan Pope on 12. May 2024. at 13:00

It’s hard to think of a more dramatic way to make an entrance than falling from the sky. While it certainly happens often enough on the silver screen, whether or not it can be done in real life is a tantalizing challenge for our entertainment robotics team at Disney Research.
Falling is tricky for two reasons. The first and most obvious is what Douglas Adams referred to as “the sudden stop at the end.” Every second of free fall means another 9.8 m/s of velocity, and that can quickly add up to an extremely difficult energy dissipation problem. The other tricky thing about falling, especially for terrestrial animals like us, is that our normal methods for controlling our orientation disappear. We are used to relying on contact forces between our body and the environment to control which way we’re pointing. In the air, there’s nothing to push on except the air itself!
Finding a solution to these problems is a big, open-ended challenge. In the clip below, you can see one approach we’ve taken to start chipping away at it.
The video shows a small, stick-like robot with an array of four ducted fans attached to its top. The robot has a piston-like foot that absorbs the impact of a small fall, and then the ducted fans keep the robot standing by counteracting any tilting motion using aerodynamic thrust.
 Raphael Pilon [left] and Marcela de los Rios evaluate the performance of the monopod balancing robot.Disney Research
Raphael Pilon [left] and Marcela de los Rios evaluate the performance of the monopod balancing robot.Disney ResearchThe standing portion demonstrates that pushing on the air isn’t only useful during freefall. Conventional walking and hopping robots depend on ground contact forces to maintain the required orientation. These forces can ramp up quickly because of the stiffness of the system, necessitating high bandwidth control strategies. Aerodynamic forces are relatively soft, but even so, they were sufficient to keep our robots standing. And since these forces can also be applied during the flight phase of running or hopping, this approach might lead to robots that run before they walk. The thing that defines a running gait is the existence of a “flight phase” - a time when none of the feet are in contact with the ground. A running robot with aerodynamic control authority could potentially use a gait with a long flight phase. This would shift the burden of the control effort to mid-flight, simplifying the leg design and possibly making rapid bipedal motion more tractable than a moderate pace.
 Richard Landon uses a test rig to evaluate the thrust profile of a ducted fan.Disney Research
Richard Landon uses a test rig to evaluate the thrust profile of a ducted fan.Disney ResearchIn the next video, a slightly larger robot tackles a much more dramatic fall, from 65’ in the air. This simple machine has two piston-like feet and a similar array of ducted fans on top. The fans not only stabilize the robot upon landing, they also help keep it oriented properly as it falls. Inside each foot is a plug of single-use compressible foam. Crushing the foam on impact provides a nice, constant force profile, which maximizes the amount of energy dissipated per inch of contraction.
In the case of this little robot, the mechanical energy dissipation in the pistons is less than the total energy needed to be dissipated from the fall, so the rest of the mechanism takes a pretty hard hit. The size of the robot is an advantage in this case, because scaling laws mean that the strength-to-weight ratio is in its favor.
The strength of a component is a function of its cross-sectional area, while the weight of a component is a function of its volume. Area is proportional to length squared, while volume is proportional to length cubed. This means that as an object gets smaller, its weight becomes relatively small. This is why a toddler can be half the height of an adult but only a fraction of that adult’s weight, and why ants and spiders can run around on long, spindly legs. Our tiny robots take advantage of this, but we can’t stop there if we want to represent some of our bigger characters.
 Louis Lambie and Michael Lynch assemble an early ducted fan test platform. The platform was mounted on guidewires and was used for lifting capacity tests.Disney Research
Louis Lambie and Michael Lynch assemble an early ducted fan test platform. The platform was mounted on guidewires and was used for lifting capacity tests.Disney ResearchIn most aerial robotics applications, control is provided by a system that is capable of supporting the entire weight of the robot. In our case, being able to hover isn’t a necessity. The clip below shows an investigation into how much thrust is needed to control the orientation of a fairly large, heavy robot. The robot is supported on a gimbal, allowing it to spin freely. At the extremities are mounted arrays of ducted fans. The fans don’t have enough force to keep the frame in the air, but they do have a lot of control authority over the orientation.
Complicated robots are less likely to survive unscathed when subjected to the extremely high accelerations of a direct ground impact, as you can see in this early test that didn’t quite go according to plan.
In this last video, we use a combination of the previous techniques and add one more capability – a dramatic mid-air stop. Ducted fans are part of this solution, but the high-speed deceleration is principally accomplished by a large water rocket. Then the mechanical legs only have to handle the last ten feet of dropping acceleration.
Whether it’s using water or rocket fuel, the principle underlying a rocket is the same – mass is ejected from the rocket at high speed, producing a reaction force in the opposite direction via Newton’s third law. The higher the flow rate and the denser the fluid, the more force is produced. To get a high flow rate and a quick response time, we needed a wide nozzle that went from closed to open cleanly in a matter of milliseconds. We designed a system using a piece of copper foil and a custom punch mechanism that accomplished just that.
 Grant Imahara pressurizes a test tank to evaluate an early valve prototype [left]. The water rocket in action - note the laminar, two-inch-wide flow as it passes through the specially designed nozzleDisney Research
Grant Imahara pressurizes a test tank to evaluate an early valve prototype [left]. The water rocket in action - note the laminar, two-inch-wide flow as it passes through the specially designed nozzleDisney ResearchOnce the water rocket has brought the robot to a mid-air stop, the ducted fans are able to hold it in a stable hover about ten feet above the deck. When they cut out, the robot falls again and the legs absorb the impact. In the video, the robot has a couple of loose tethers attached as a testing precaution, but they don’t provide any support, power, or guidance.
“It might not be so obvious as to what this can be directly used for today, but these rough proof-of-concept experiments show that we might be able to work within real-world physics to do the high falls our characters do on the big screen, and someday actually stick the landing,” explains Tony Dohi, the project lead.
There are still a large number of problems for future projects to address. Most characters have legs that bend on hinges rather than compress like pistons, and don’t wear a belt made of ducted fans. Beyond issues of packaging and form, making sure that the robot lands exactly where it intends to land has interesting implications for perception and control. Regardless, we think we can confirm that this kind of entrance has–if you’ll excuse the pun–quite the impact.
-
Video Friday: Robot Bees
by Evan Ackerman on 10. May 2024. at 16:26

Video Friday is your weekly selection of awesome robotics videos, collected by your friends at IEEE Spectrum robotics. We also post a weekly calendar of upcoming robotics events for the next few months. Please send us your events for inclusion.
ICRA 2024: 13–17 May 2024, YOKOHAMA, JAPAN
RoboCup 2024: 17–22 July 2024, EINDHOVEN, NETHERLANDS
ICSR 2024: 23–26 October 2024, ODENSE, DENMARK
Cybathlon 2024: 25–27 October 2024, ZURICH
Enjoy today’s videos!
Festo has robot bees!
It’s a very clever design, but the size makes me terrified of whatever the bees are that Festo seems to be familiar with.
[ Festo ]
Boing, boing, boing!
[ USC ]
Why the heck would you take the trouble to program a robot to make sweet potato chips and then not scarf them down yourself?
[ Dino Robotics ]
Mobile robots can transport payloads far greater than their mass through vehicle traction. However, off-road terrain features substantial variation in height, grade, and friction, which can cause traction to degrade or fail catastrophically. This paper presents a system that utilizes a vehicle-mounted, multipurpose manipulator to physically adapt the robot with unique anchors suitable for a particular terrain for autonomous payload transport.
[ DART Lab ]
Turns out that working on a collaborative task with a robot can make humans less efficient, because we tend to overestimate the robot’s capabilities.
[ CHI 2024 ]
Wing posts a video with the title “What Do Wing’s Drones Sound Like” but only includes a brief snippet—though nothing without background room noise—revealing to curious viewers and listeners exactly what Wing’s drones sound like.
Because, look, a couple seconds of muted audio underneath a voiceover is in fact not really answering the question.
[ Wing ]
This first instance of ROB 450 in Winter 2024 challenged students to synthesize the knowledge acquired through their Robotics undergraduate courses at the University of Michigan to use a systematic and iterative design and analysis process and apply it to solving a real, open-ended Robotics problem.
This Microsoft Future Leaders in Robotics and AI Seminar is from Catie Cuan at Stanford, on “Choreorobotics: Teaching Robots How to Dance With Humans.”
As robots transition from industrial and research settings into everyday environments, robots must be able to (1) learn from humans while benefiting from the full range of the humans’ knowledge and (2) learn to interact with humans in safe, intuitive, and social ways. I will present a series of compelling robot behaviors, where human perception and interaction are foregrounded in a variety of tasks.
[ UMD ]
-
The New Shadow Hand Can Take a Beating
by Evan Ackerman on 10. May 2024. at 14:00

For years, Shadow Robot Company’s Shadow Hand has arguably been the gold standard for robotic manipulation. Beautiful and expensive, it is able to mimic the form factor and functionality of human hands, which has made it ideal for complex tasks. I’ve personally experienced how amazing it is to use Shadow Hands in a teleoperation context, and it’s hard to imagine anything better.
The problem with the original Shadow hand was (and still is) fragility. In a research environment, this has been fine, except that research is changing: Roboticists no longer carefully program manipulation tasks by, uh, hand. Now it’s all about machine learning, in which you need robotic hands to massively fail over and over again until they build up enough data to understand how to succeed.
“We’ve aimed for robustness and performance over anthropomorphism and human size and shape.” —Rich Walker, Shadow Robot Company
Doing this with a Shadow Hand was just not realistic, which Google DeepMind understood five years ago when it asked Shadow Robot to build it a new hand with hardware that could handle the kind of training environments that now typify manipulation research. So Shadow Robot spent the last half-decade-ish working on a new, three-fingered Shadow Hand, which the company unveiled today. The company is calling it, appropriately enough, “the new Shadow Hand.”
As you can see, this thing is an absolute beast. Shadow Robot says that the new hand is “robust against a significant amount of misuse, including aggressive force demands, abrasion and impacts.” Part of the point, though, is that what robot-hand designers might call “misuse,” robot-manipulation researchers might very well call “progress,” and the hand is designed to stand up to manipulation research that pushes the envelope of what robotic hardware and software are physically capable of.
Shadow Robot understands that despite its best engineering efforts, this new hand will still occasionally break (because it’s a robot and that’s what robots do), so the company designed it to be modular and easy to repair. Each finger is its own self-contained unit that can be easily swapped out, with five Maxon motors in the base of the finger driving the four finger joints through cables in a design that eliminates backlash. The cables themselves will need replacement from time to time, but it’s much easier to do this on the new Shadow Hand than it was on the original. Shadow Robot says that you can swap out an entire New Hand’s worth of cables in the same time it would take you to replace a single cable on the old hand.
 Shadow Robot
Shadow RobotThe new Shadow Hand itself is somewhat larger than a typical human hand, and heavier too: Each modular finger unit weighs 1.2 kilograms, and the entire three-fingered hand is just over 4 kg. The fingers have humanlike kinematics, and each joint can move up to 180 degrees per second with the capability of exerting at least 8 newtons of force at each fingertip. Both force control and position control are available, and the entire hand runs Robot Operating System, the Open Source Robotics Foundation’s collection of open-source software libraries and tools.
One of the coolest new features of this hand is the tactile sensing. Shadow Robot has decided to take the optical route with fingertip sensors, GelSight-style. Each fingertip is covered in soft, squishy gel with thousands of embedded particles. Cameras in the fingers behind the gel track each of those particles, and when the fingertip touches something, the particles move. Based on that movement, the fingertips can very accurately detect the magnitude and direction of even very small forces. And there are even more sensors on the insides of the fingers too, with embedded Hall effect sensors to help provide feedback during grasping and manipulation tasks.
 Shadow Robot
Shadow RobotThe most striking difference here is how completely different of a robotic-manipulation philosophy this new hand represents for Shadow Robot. “We’ve aimed for robustness and performance over anthropomorphism and human size and shape,” says Rich Walker, director of Shadow Robot Company. “There’s a very definite design choice there to get something that really behaves much more like an optimized manipulator rather than a humanlike hand.”
Walker explains that Shadow Robot sees two different approaches to manipulation within the robotics community right now: There’s imitation learning, where a human does a task and then a robot tries to do the task the same way, and then there’s reinforcement learning, where a robot tries to figure out how do the task by itself. “Obviously, this hand was built from the ground up to make reinforcement learning easy.”
The hand was also built from the ground up to be rugged and repairable, which had a significant effect on the form factor. To make the fingers modular, they have to be chunky, and trying to cram five of them onto one hand was just not practical. But because of this modularity, Shadow Robot could make you a five-fingered hand if you really wanted one. Or a two-fingered hand. Or (and this is the company’s suggestion, not mine) “a giant spider.” Really, though, it’s probably not useful to get stuck on the form factor. Instead, focus more on what the hand can do. In fact, Shadow Robot tells me that the best way to think about the hand in the context of agility is as having three thumbs, not three fingers, but Walker says that “if we describe it as that, people get confused.”
There’s still definitely a place for the original anthropomorphic Shadow Hand, and Shadow Robot has no plans to discontinue it. “It’s clear that for some people anthropomorphism is a deal breaker, they have to have it,” Walker says. “But for a lot of people, the idea that they could have something which is really robust and dexterous and can gather lots of data, that’s exciting enough to be worth saying okay, what can we do with this? We’re very interested to find out what happens.”
The Shadow New Hand is available now, starting at about US $74,000 depending on configuration.
-
Commercial Space Stations Approach Launch Phase
by Andrew Jones on 10. May 2024. at 13:00

A changing of the guard in space stations is on the horizon as private companies work toward providing new opportunities for science, commerce, and tourism in outer space.
Blue Origin is one of a number of private-sector actors aiming to harbor commercial activities in low Earth orbit (LEO) as the creaking and leaking International Space Station (ISS) approaches its drawdown. Partners in Blue Origin’s Orbital Reef program, including firms Redwire, Sierra Space, and Boeing, are each reporting progress in their respective components of the program. The collaboration itself may not be on such strong ground. Such endeavors may also end up slowed and controlled by regulation so far absent from many new, commercial areas of space.
Orbital Reef recently aced testing milestones for its critical life support system, with assistance from NASA. These included hitting targets for trace contaminant control, water contaminant oxidation, urine water recovery, and water tank tests—all of which are required to operate effectively and efficiently to enable finite resources to keep delicate human beings alive in orbit for long timeframes.
Blue Origin, founded by Jeff Bezos, is characteristically tight-lipped on its progress and challenges and declined to provide further comment on progress beyond NASA’s life-support press statement.
The initiative is backed by NASA’s Commercial LEO Destinations (CLD) program, through which the agency is providing funding to encourage the private sector to build space habitats. NASA may also be the main client starting out, although the wider goal is to foster a sustainable commercial presence in LEO.
The Space-Based Road Ahead
The challenge Orbital Reef faces is considerable: reimagining successful earthbound technologies—such as regenerative life-support systems, expandable habitats and 3D printing—but now in orbit, on a commercially viable platform. The technologies must also adhere to unforgiving constraints of getting mass and volume to space, and operating on a significantly reduced budget compared to earlier national space station programs.
Add to that autonomy and redundancy that so many mission-critical functions will demand, as well as high-bandwidth communications required to return data and allow streaming and connectivity for visitors.
In one recent step forward for Orbital Reef, Sierra Space, headquartered in Louisville, Colo., performed an Ultimate Burst Pressure (UBP) test on its architecture in January. This involved inflating, to the point of failure, the woven fabric pressure shell—including Vectran, a fabric that becomes rigid and stronger than steel when pressurized on orbit—for its Large Integrated Flexible Environment (LIFE) habitat. Sierra’s test reached 530,000 pascals (77 pounds per square inch) before it burst—marking a successful failure that far surpassed NASA’s recommended safety level of 419,200 Pa (60.8 psi).
Notably, the test article was 300 cubic meters in volume, or one-third the volume of ISS—a megaproject constructed by some 15 countries over more than 30 launches. LIFE will contain 10 crew cabins along with living, galley, and gym areas. This is expected to form part of the modular Orbital Reef complex. The company stated last year it aimed to launch a pathfinder version of LIFE around the end of 2026.
Inflating and Expanding Expectations
Whereas the size of ISS modules and those of China’s new, three-module Tiangong space station, constructed in 2021–22, was dependent on the size of the payload bay or fairing of the shuttle or rocket doing the launching, using expandable quarters allows Orbital Reef to offer habitable areas multiples (in this case five times) greater than the volume of the 5-meter rocket fairing to be used to transport the system to orbit.
Other modules will include Node, with an airlock and docking facilities, also developed by Sierra Space, as well as a spherical Core module developed by Blue Origin. Finally, Boeing is developing a research module, which will include a science cupola, akin to that on the ISS, external payload facilities, and a series of laboratories.
Orbital Reef will be relying on some technologies developed for and spun off from the ISS project, which was completed in 2011 at a cost of US $100 billion. The new station will be operating on fractions of such budgets, with Blue Origin awarded $130 million of a total $415.6 million given to three companies in 2021.
“NASA is using a two-phase strategy to, first, support the development of commercial destinations and, secondly, enable the agency to purchase services as one of many customers” says NASA spokesperson Anna Schneider, at NASA’s Johnson Space Center.
For instance, Northrop Grumman is working on its Persistent Platform to provide autonomous and robotic capabilities for commercial science and manufacturing capabilities in LEO.
Such initiatives could face politically constructed hurdles, however. Last year, some industry advocates opposed a White House proposal that would see new commercial space activities such as space stations regulated.
Meanwhile, the European Space Agency (ESA) signed a memorandum of understanding in late 2023 with Airbus and Voyager Space, headquartered in Denver, which would give ESA access to a planned Starlab space station after the ISS is transitioned out. That two-module orbital outpost will also be inflatable and is now expected to be launched in 2028.
China also is exploring opening its Tiangong station to commercial activities, including its own version of NASA’s commercial cargo and extending the station with new modules—and new competition for the world’s emerging space station sector.
-
Your Next Great AI Engineer Already Works for You
by CodeSignal on 09. May 2024. at 18:42

The AI future has arrived. From tech and finance, to healthcare, retail, and manufacturing, nearly every industry today has begun to incorporate artificial intelligence (AI) into their technology platforms and business operations. The result is a surging talent demand for engineers who can design, implement, leverage, and manage AI systems.
Over the next decade, the need for AI talent will only continue to grow. The US Bureau of Labor Statistics expects demand for AI engineers to increase by 23 percent by 2030 and demand for machine learning (ML) engineers, a subfield of AI, to grow by up to 22 percent.
In the tech industry, this demand is in full swing. Job postings that call for skills in generative AI increased by an incredible 1,848 percent in 2023, a recent labor market analysis shows. The analysis also found that there were over 385,000 postings for AI roles in 2023.
 Figure 1: Growth of job postings requiring skills in generative AI, 2022-2023
Figure 1: Growth of job postings requiring skills in generative AI, 2022-2023
To capitalize on the transformative potential of AI, companies cannot simply hire new AI engineers: there just aren’t enough of them yet. To address the global shortage of AI engineering talent, you must upskill and reskill your existing engineers.
Essential skills for AI and ML
AI and its subfields, machine learning (ML) and natural language processing (NLP), all involve training algorithms on large sets of data to produce models that can perform complex tasks. As a result, different types of AI engineering roles require many of the same core skills.
CodeSignal’s Talent Science team and technical subject matter experts have conducted extensive skills mapping of AI engineering roles to define the skills required of these roles. These are the core skills they identified for two popular AI roles: ML engineering and NLP engineering.
Machine learning (ML) engineering core skills

Natural language processing (NLP) engineering core skills

Developing AI skills on your teams
A recent McKinsey report finds that upskilling and reskilling are core ways that organizations fill AI skills gaps on their teams. Alexander Sukharevsky, Senior Partner at McKinsey, explains in the report: “When it comes to sourcing AI talent, the most popular strategy among all respondents is reskilling existing employees. Nearly half of the companies we surveyed are doing so.”
So: what is the best way to develop the AI skills you need within your existing teams? To answer that, we first need to dive deeper into how humans learn new skills.
Components of effective skills development
Most corporate learning programs today use the model of traditional classroom learning where one teacher, with one lesson, serves many learners. An employee starts by choosing a program, often with little guidance. Once they begin the course, lessons likely use videos to deliver instruction and are followed by quizzes to gauge their retention of the information.
There are several problems with this model:
- Decades of research show that the traditional, one-to-many model of learning is not the most effective way to learn. Educational psychologist Benjamin Bloom observed that students who learned through one-on-one tutoring outperformed their peers by two standard deviations; that is, they performed better than 98 percent of those who learned in traditional classroom environments. The superiority of one-on-one tutoring over classroom learning has been dubbed the 2-sigma problem in education (see Figure 2 below).
- Multiple-choice quizzes provide a poor signal of employees’ skills—especially for specialized technical skills like AI and ML engineering. Quizzes also do not give learners the opportunity to apply what they’ve learned in a realistic context or in the flow of their work.
- Without guidance grounded in their current skills, strengths, and goals—as well as their team’s needs—employees may choose courses or learning programs that are mismatched to their level of skill proficiency or goals.

Developing your team members’ mastery of the AI and ML skills your team needs requires a learning program that delivers the following:
- One-on-one tutoring. Today’s best-in-class technical learning programs use AI-powered assistants that are contextually aware and fully integrated with the learning environment to deliver personalized, one-on-one guidance and feedback to learners at scale.
The use of AI to support their learning will come as no surprise to your developers and other technical employees: a recent survey shows that 81 percent of developers already use AI tools in their work—and of those, 76 percent use them to learn new knowledge and skills.
- Practice-based learning. Decades of research show that people learn best with active practice, not passive intake of information. The learning program you use to level up your team’s skills in AI and ML should be practice-centered and make use of coding exercises that simulate real AI and ML engineering work.
- Outcome-driven tools. Lastly, the best technical upskilling programs ensure employees actually build relevant skills (not just check a box) and apply what they learn on the job. Learning programs should also give managers visibility into their team members’ skill growth and mastery. Your platform should include benchmarking data, to allow you to compare your team’s skills to the larger population of technical talent, as well as integrations with your existing learning systems.
Deep dive: Practice-based learning for AI skills
Below is an example of an advanced practice exercise from the Introduction to Neural Networks with TensorFlow course in CodeSignal Develop.
Example practice: Implementing layers in a neural network
In this practice exercise, learners build their skills in designing neural network layers to improve the performance of the network. Learners implement their solution in a realistic IDE and built-in terminal in the right side of the screen, and interact with Cosmo, an AI-powered tutor and guide, in the panel on the left side of the screen.
Practice description: Now that you have trained a model with additional epochs, let’s tweak the neural network’s architecture. Your task is to implement a second dense layer in the neural network to potentially improve its learning capabilities. Remember: Configuring layers effectively is crucial for the model’s performance!

Conclusion
The demand for AI and ML engineers is here, and will continue to grow over the coming years as AI technologies become critical to more and more organizations across all industries. Companies seeking to fill AI and ML skills gaps on their teams must invest in upskilling and reskilling their existing technical teams with crucial AI and ML skills.
Learn more:
-
Management Versus Technical Track
by Tariq Samad on 09. May 2024. at 18:00

This article is part of our exclusive career advice series in partnership with the IEEE Technology and Engineering Management Society.
As you begin your professional career freshly armed with an engineering degree, your initial roles and responsibilities are likely to revolve around the knowledge and competencies you learned at school. If you do well in your job, you’re apt to be promoted, gaining more responsibilities such as managing projects, interacting with other departments, making presentations to management, and meeting with customers. You probably also will gain a general understanding of how your company and the business world work.
At some point in your career, you’re likely to be asked an important question: Are you interested in a management role?
There is no right or wrong answer. Engineers have fulfilling, rewarding careers as individual contributors and as managers—and companies need both. You should decide your path based on your interests and ambitions as well as your strengths and shortcomings.
However, the specific considerations involved aren’t always obvious. To help you, this article covers some of the differences between the two career paths, as well as factors that might influence you.
The remarks are based on our personal experiences in corporate careers spanning decades in the managerial track and the technical track. Tariq worked at Honeywell; Gus at 3M. We have included advice from IEEE Technology and Engineering Management Society colleagues.
Opting for either track isn’t a career-long commitment. Many engineers who go into management return to the technical track, in some cases of their own volition. And management opportunities can be adopted late in one’s career, again based on individual preferences or organizational needs.
In either case, there tends to be a cost to switching tracks. While the decision of which track to take certainly isn’t irrevocable, it behooves engineers to understand the pros and cons involved.
Differences between the two tracks
Broadly, the managerial track is similar across all companies. It starts with supervising small groups, extends through middle-management layers, progresses up to leadership positions and, ultimately, the executive suite. Management backgrounds can vary, however. For example, although initial management levels in a technology organization generally require an engineering or science degree, some top leaders in a company might be more familiar with sales, marketing, or finance.
It’s a different story for climbing the technical ladder. Beyond the first engineering-level positions, there is no standard model. In some cases individual contributors hit the career ceiling below the management levels. In others, formal roles exist that are equivalent to junior management positions in terms of pay scale and other aspects.
“Engineers have fulfilling, rewarding careers as individual contributors and as managers—and companies need both.”
Some organizations have a well-defined promotional system with multiple salary bands for technical staff, parallel to those for management positions. Senior technologists often have a title such as Fellow, staff scientist, or architect, with top-of-the-ladder positions including corporate Fellow, chief engineer/scientist, and enterprise architect.
Organizational structures vary considerably among small companies—including startups, medium companies, and large corporations. Small businesses often don’t have formal or extensive technical tracks, but their lack of structure can make it easier to advance in responsibilities and qualifications while staying deeply technical.
In more established companies, structures and processes tend to be well defined and set by policy.
For those interested in the technical track, the robustness of a company’s technical ladder can be a factor in joining the company. Conversely, if you’re interested in the technical ladder and you’re working for a company that does not offer one, that might be a reason to look for opportunities elsewhere.
Understanding the career paths a company offers is especially important for technologists.
The requirements for success
First and foremost, the track you lean toward should align with aspirations for your career—and your personal life.
As you advance in the management path, you can drive business and organizational success through decisions you make and influence. You also will be expected to shape and nurture employees in your organization by providing feedback and guidance. You likely will have more control over resources—people as well as funding—and more opportunity for defining and executing strategy.
The technical path has much going for it as well, especially if you are passionate about solving technical challenges and increasing your expertise in your area of specialization. You won’t be supervising large numbers of employees, but you will manage significant projects and programs that give you chances to propose and define such initiatives. You also likely will have more control of your time and not have to deal with the stress involved with being responsible for the performance of the people and groups reporting to you.
The requirements for success in the two tracks offer contrasts as well. Technical expertise is an entry requirement for the technical track. It’s not just technical depth, however. As you advance, technical breadth is likely to become increasingly important and will need to be supplemented by an understanding of the business, including markets, customers, economics, and government regulations.
Pure technical expertise will never be the sole performance criterion. Soft skills such as verbal and written communication, getting along with people, time management, and teamwork are crucial for managers and leaders.
On the financial side, salaries and growth prospects generally will be higher on the managerial track. Executive tiers can include substantial bonuses and stock options. Salary growth is typically slower for senior technologists.
Managerial and technical paths are not always mutually exclusive. It is, in fact, not uncommon for staff members who are on the technical ladder to supervise small teams. And some senior managers are able to maintain their technical expertise and earn recognition for it.
We recommend you take time to consider which of the two tracks is more attractive—before you get asked to choose. If you’re early in your career, you don’t need to make this important decision now. You can keep your options open and discuss them with your peers, senior colleagues, and management. And you can contemplate and clarify what your objectives and preferences are. When the question does come up, you’ll be better prepared to answer it.
-
5 New Ways to Maximize Your Hardware Security Resilience
by Ansys on 09. May 2024. at 15:48

Connected vehicles offer a range of benefits, such as real-time data sharing, app-to-car connectivity, advanced driver assistance systems (ADAS), and critical safety features like location tracking, remote parking, and in-vehicle infotainment systems (IVIs). These advancements aim to enhance the overall driving and riding experience. However, it is crucial to acknowledge that equipping vehicles with smart features also exposes them to potential cyberattacks. These attacks can result in customer data leakage or even compromise critical safety functionalities.
It’s expected to discover vulnerabilities after the product is released, which could have been easily prevented. For instance, as reported by Bloomberg, a recent increase in car thefts was attributed to the absence of anti-theft computer chips in vehicle critical systems. Therefore, it is imperative to proactively consider and address potential attack vectors right from the initial stages of development. This cybersecurity vulnerability applies to many other industrial applications, such as industrial IoT, SmartCity, and digital healthcare, where every device or system is connected, and every connection is a vulnerability.
Design for security is becoming mainstream and should be part of today’s standard design methodologies.
What you will learn:
1. Why a model-based and system-oriented solution is needed for automotive cybersecurity
2. How to quickly identify threat scenarios
3. Why a pre-silicon security verification flow is essential for secure ICs
4. Using AI to mitigate side-channel vulnerabilities
Who should attend this presentation:
This webinar is valuable to anyone who works with product design, connectivity and security.
-
A Skeptic’s Take on Beaming Power to Earth from Space
by Henri Barde on 09. May 2024. at 15:00

The accelerating buildout of solar farms on Earth is already hitting speed bumps, including public pushback against the large tracts of land required and a ballooning backlog of requests for new transmission lines and grid connections. Energy experts have been warning that electricity is likely to get more expensive and less reliable unless renewable power that waxes and wanes under inconstant sunlight and wind is backed up by generators that can run whenever needed. To space enthusiasts, that raises an obvious question: Why not stick solar power plants where the sun always shines?
Space-based solar power is an idea so beautiful, so tantalizing that some argue it is a wish worth fulfilling. A constellation of gigantic satellites in geosynchronous orbit (GEO) nearly 36,000 kilometers above the equator could collect sunlight unfiltered by atmosphere and uninterrupted by night (except for up to 70 minutes a day around the spring and fall equinoxes). Each megasat could then convert gigawatts of power into a microwave beam aimed precisely at a big field of receiving antennas on Earth. These rectennas would then convert the signal to usable DC electricity.
The thousands of rocket launches needed to loft and maintain these space power stations would dump lots of soot, carbon dioxide, and other pollutants into the stratosphere, with uncertain climate impacts. But that might be mitigated, in theory, if space solar displaced fossil fuels and helped the world transition to clean electricity.
The glamorous vision has inspired numerous futuristic proposals. Japan’s space agency has presented a road map to deployment. Space authorities in China aim to put a small test satellite in low Earth orbit (LEO) later this decade. Ideas to put megawatt-scale systems in GEO sometime in the 2030s have been floated but not yet funded.
The U.S. Naval Research Laboratory has already beamed more than a kilowatt of power between two ground antennas about a kilometer apart. It also launched in 2023 a satellite that used a laser to transmit about 1.5 watts, although the beam traveled less than 2 meters and the system had just 11 percent efficiency. A team at Caltech earlier this year wrapped up a mission that used a small satellite in LEO to test thin-film solar cells, flexible microwave-power circuitry, and a small collapsible deployment mechanism. The energy sent Earthward by the craft was too meager to power a lightbulb, but it was progress nonetheless.
The European Space Agency (ESA) debuted in 2022 its space-based solar-power program, called Solaris, with an inspiring (but entirely fantastical) video animation. The program’s director, Sanjay Vijendran, told IEEE Spectrum that the goal of the effort is not to develop a power station for space. Instead, the program aims to spend three years and €60 million (US $65 million) to figure out whether solar cells, DC-to-RF converters, assembly robots, beam-steering antennas, and other must-have technologies will improve drastically enough over the next 10 to 20 years to make orbital solar power feasible and competitive. Low-cost, low-mass, and space-hardy versions of these technologies would be required, but engineers trying to draw up detailed plans for such satellites today find no parts that meet the tough requirements.
 Not so fast: The real-world efficiency of commercial, space-qualified solar cells has progressed much more slowly than records set in highly controlled research experiments, which often use exotic materials or complex designs that cannot currently be mass-produced. Points plotted here show the highest efficiency reported in five-year intervals.HENRI BARDE; DATA FROM NATIONAL RENEWABLE ENERGY LABORATORY (RESEARCH CELLS) AND FROM MANUFACTURER DATA SHEETS AND PRESENTATIONS (COMMERCIAL CELLS)
Not so fast: The real-world efficiency of commercial, space-qualified solar cells has progressed much more slowly than records set in highly controlled research experiments, which often use exotic materials or complex designs that cannot currently be mass-produced. Points plotted here show the highest efficiency reported in five-year intervals.HENRI BARDE; DATA FROM NATIONAL RENEWABLE ENERGY LABORATORY (RESEARCH CELLS) AND FROM MANUFACTURER DATA SHEETS AND PRESENTATIONS (COMMERCIAL CELLS)
With the flurry of renewed attention, you might wonder: Has extraterrestrial solar power finally found its moment? As the recently retired head of space power systems at ESA—with more than 30 years of experience working on power generation, energy storage, and electrical systems design for dozens of missions, including evaluation of a power-beaming experiment proposed for the International Space Station—I think the answer is almost certainly no.
Despite mounting buzz around the concept, I and many of my former colleagues at ESA are deeply skeptical that these large and complex power systems could be deployed quickly enough and widely enough to make a meaningful contribution to the global energy transition. Among the many challenges on the long and formidable list of technical and societal obstacles: antennas so big that we cannot even simulate their behavior.
Here I offer a road map of the potential chasms and dead ends that could doom a premature space solar project to failure. Such a misadventure would undermine the credibility of the responsible space agency and waste capital that could be better spent improving less risky ways to shore up renewable energy, such as batteries, hydrogen, and grid improvements. Champions of space solar power could look at this road map as a wish list that must be fulfilled before orbital solar power can become truly appealing to electrical utilities.
Space Solar Power at Peak Hype—Again
For decades, enthusiasm for the possibility of drawing limitless, mostly clean power from the one fusion reactor we know works reliably—the sun—has run hot and cold. A 1974 study that NASA commissioned from the consultancy Arthur D. Little bullishly recommended a 20-year federal R&D program, expected to lead to a commercial station launching in the mid-1990s. After five years of work, the agency delivered a reference architecture for up to 60 orbiting power stations, each delivering 5 to 10 gigawatts of baseload power to major cities. But officials gave up on the idea when they realized that it would cost over $1 trillion (adjusted for inflation) and require hundreds of astronauts working in space for decades, all before the first kilowatt could be sold.
NASA did not seriously reconsider space solar until 1995, when it ordered a “fresh look” at the possibility. That two-year study generated enough interest that the U.S. Congress funded a small R&D program, which published plans to put up a megawatt-scale orbiter in the early 2010s and a full-size power plant in the early 2020s. Funding was cut off a few years later, with no satellites developed.
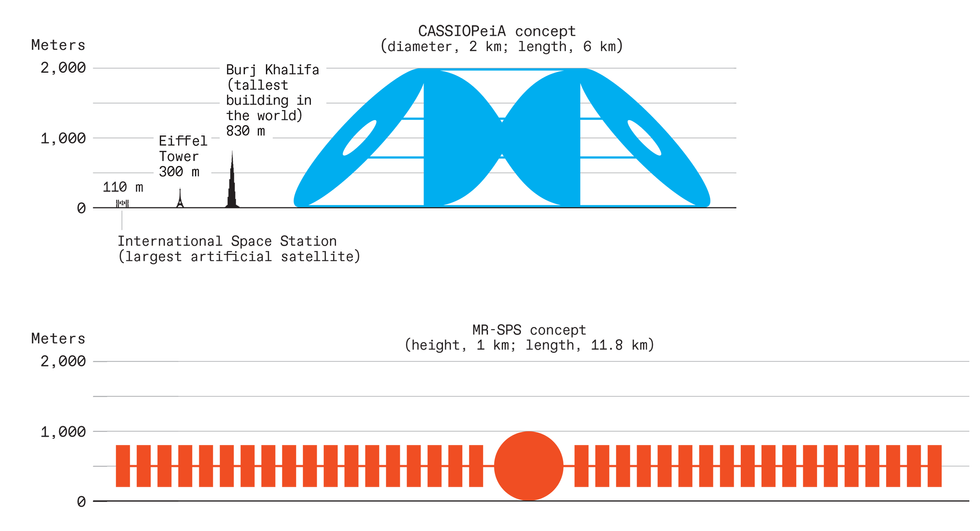 Because of the physics of power transmission from geosynchronous orbit, space power satellites must be enormous—hundreds of times larger than the International Space Station and even dwarfing the tallest skyscrapers—to generate electricity at a competitive price. The challenges for their engineering and assembly are equally gargantuan. Chris Philpot
Because of the physics of power transmission from geosynchronous orbit, space power satellites must be enormous—hundreds of times larger than the International Space Station and even dwarfing the tallest skyscrapers—to generate electricity at a competitive price. The challenges for their engineering and assembly are equally gargantuan. Chris Philpot
Then, a decade ago, private-sector startups generated another flurry of media attention. One, Solaren, even signed a power-purchase agreement to deliver 200 megawatts to utility customers in California by 2016 and made bold predictions that space solar plants would enter mass production in the 2020s. But the contract and promises went unfulfilled.
The repeated hype cycles have ended the same way each time, with investors and governments balking at the huge investments that must be risked to build a system that cannot be guaranteed to work. Indeed, in what could presage the end of the current hype cycle, Solaris managers have had trouble drumming up interest among ESA’s 22 member states. So far only the United Kingdom has participated, and just 5 percent of the funds available have been committed to actual research work.
Even space-solar advocates have recognized that success clearly hinges on something that cannot be engineered: sustained political will to invest, and keep investing, in a multidecade R&D program that ultimately could yield machines that can’t put electricity on the grid. In that respect, beamed power from space is like nuclear fusion, except at least 25 years behind.
In the 1990s, the fusion community succeeded in tapping into national defense budgets and cobbled together the 35-nation, $25 billion megaproject ITER, which launched in 2006. The effort set records for delays and cost overruns, and yet a prototype is still years from completion. Nevertheless, dozens of startups are now testing new fusion-reactor concepts. Massive investments in space solar would likely proceed in the same way. Of course, if fusion succeeds, it would eclipse the rationale for solar-energy satellites.
Space Industry Experts Run the Numbers
The U.S. and European space agencies have recently released detailed technical analyses of several space-based solar-power proposals. [See diagrams.] These reports make for sobering reading.
SPS-ALPHA Mark-III
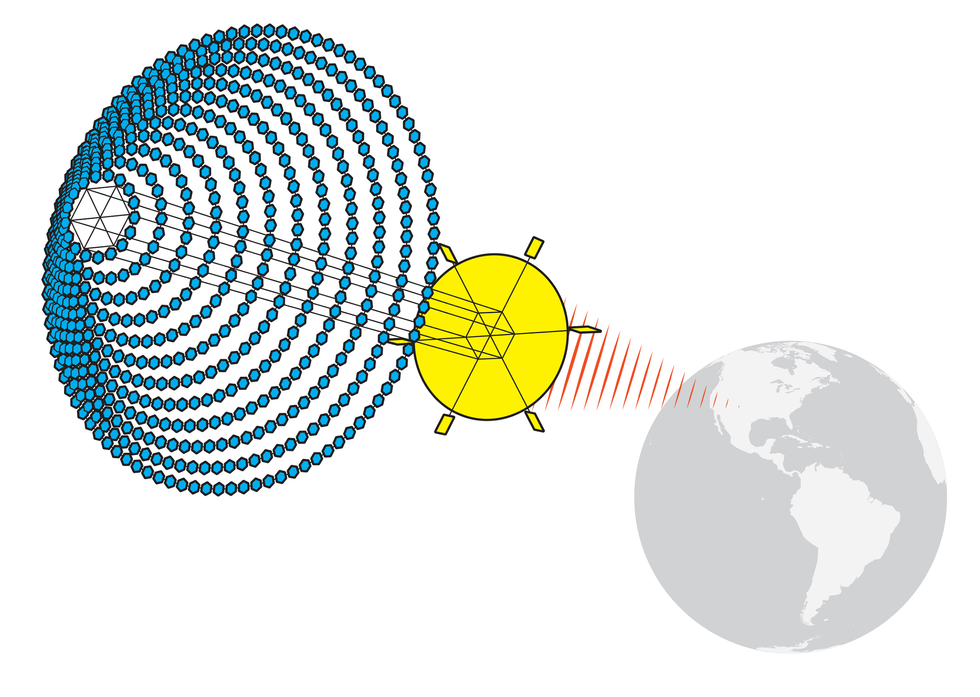
Proposed by: John C. Mankins, former NASA physicist
Features: Thin-film reflectors (conical array) track the sun and concentrate sunlight onto an Earth-facing energy-conversion array that has photovoltaic (PV) panels on one side, microwave antennas on the other, and power distribution and control electronics in the middle. Peripheral modules adjust the station’s orbit and orientation.
MR-SPS
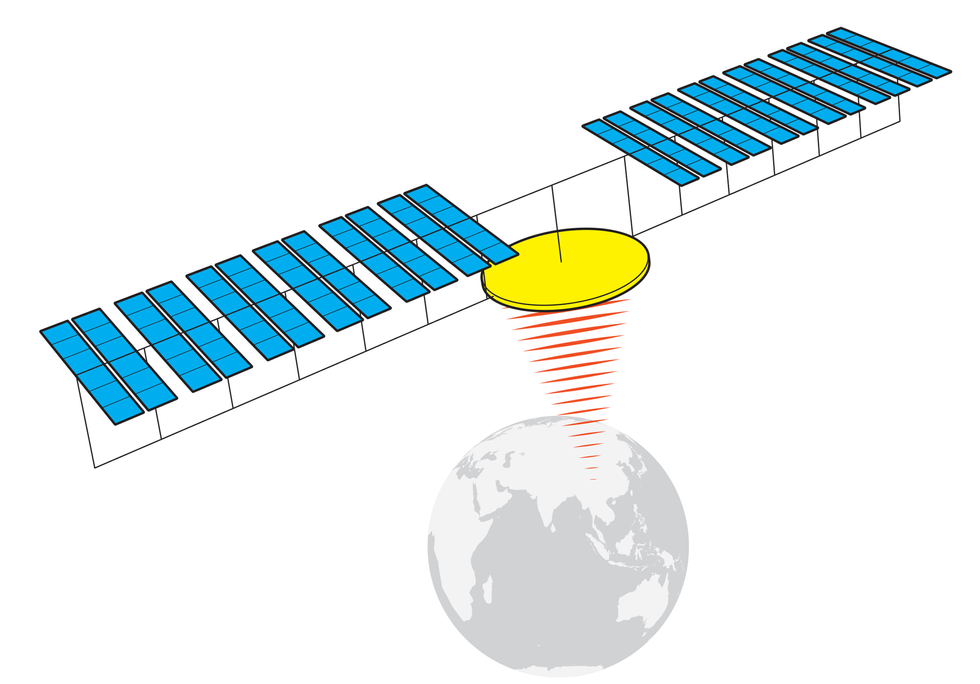
Proposed by: China Academy of Space Technology
Features: Fifty PV solar arrays, each 200 meters wide and 600 meters long, track the sun and send power through rotating high-power joints and perpendicular trusses to a central microwave-conversion and transmission array that points 128,000 antenna modules at the receiving station on Earth.
CASSIOPeiA
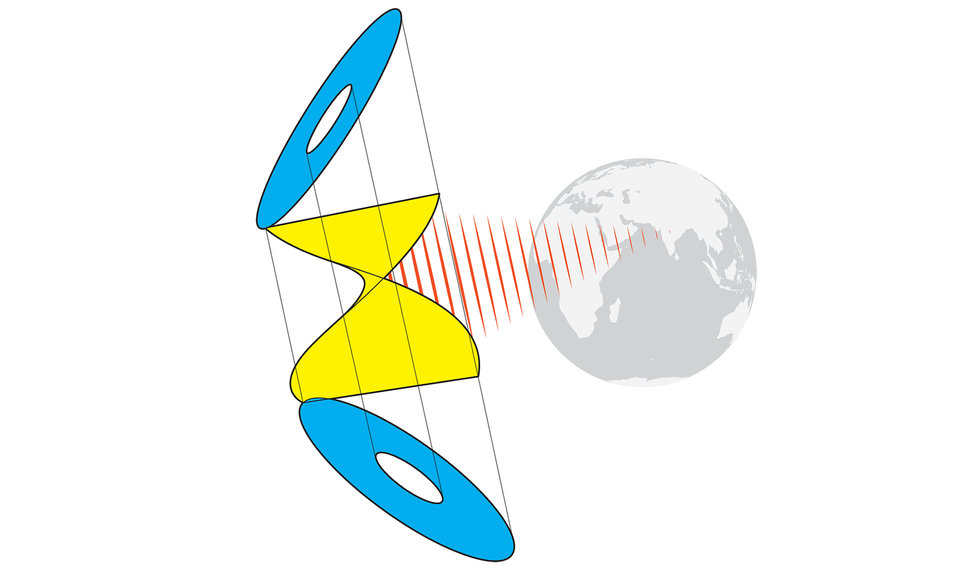
Proposed by: Ian Cash, chief architect, Space Solar Group Holdings
Features: Circular thin-film reflectors track the sun and bounce light onto a helical array that includes myriad small PV cells covered by Fresnel-lens concentrators, power-conversion electronics, and microwave dipole antennas. The omnidirectional antennas must operate in sync to steer the beam as the station rotates relative to the Earth.
SPS (Solar power satellite)
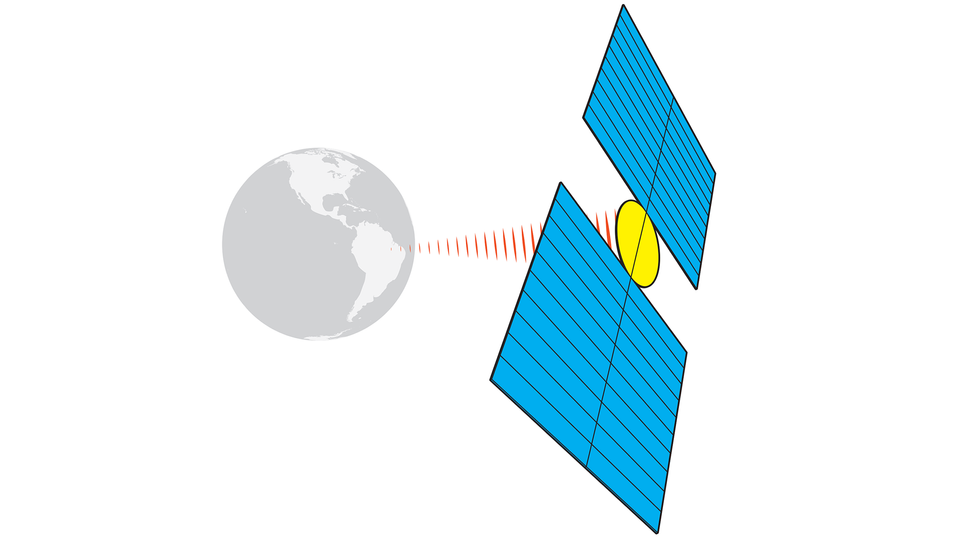
Proposed by: Thales Alenia Space
Features: Nearly 8,000 flexible solar arrays, each 10 meters wide and 80 meters long, are unfurled from roll-out modules and linked together to form two wings. The solar array remains pointed at the sun, so the central transmitter must rotate and also operate with great precision as a phased-array antenna to continually steer the beam onto the ground station.
Electricity made this way, NASA reckoned in its 2024 report, would initially cost 12 to 80 times as much as power generated on the ground, and the first power station would require at least $275 billion in capital investment. Ten of the 13 crucial subsystems required to build such a satellite—including gigawatt-scale microwave beam transmission and robotic construction of kilometers-long, high-stiffness structures in space—rank as “high” or “very high” technical difficulty, according to a 2022 report to ESA by Frazer-Nash, a U.K. consultancy. Plus, there is no known way to safely dispose of such enormous structures, which would share an increasingly crowded GEO with crucial defense, navigation, and communications satellites, notes a 2023 ESA study by the French-Italian satellite maker Thales Alenia Space.
An alternative to microwave transmission would be to beam the energy down to Earth as reflected sunlight. Engineers at Arthur D. Little described the concept in a 2023 ESA study in which they proposed encircling the Earth with about 4,000 aimable mirrors in LEO. As each satellite zips overhead, it would shine an 8-km-wide spotlight onto participating solar farms, allowing the farms to operate a few extra hours each day (if skies are clear). In addition to the problems of clouds and light pollution, the report noted the thorny issue of orbital debris, estimating that each reflector would be penetrated about 75 billion times during its 10-year operating life.
My own assessment, presented at the 2023 European Space Power Conference and published by IEEE, pointed out dubious assumptions and inconsistencies in four space-solar designs that have received serious attention from government agencies. Indeed, the concepts detailed so far all seem to stand on shaky technical ground.
Massive Transmitters and Receiving Stations
The high costs and hard engineering problems that prevent us from building orbital solar-power systems today arise mainly from the enormity of these satellites and their distance from Earth, both of which are unavoidable consequences of the physics of this kind of energy transmission. Only in GEO can a satellite stay (almost) continuously connected to a single receiving station on the ground. The systems must beam down their energy at a frequency that passes relatively unimpeded through all kinds of weather and doesn’t interfere with critical radio systems on Earth. Most designs call for 2.45 or 5.8 gigahertz, within the range used for Wi-Fi. Diffraction will cause the beam to spread as it travels, by an amount that depends on the frequency.
Thales Alenia Space estimated that a transmitter in GEO must be at least 750 meters in diameter to train the bright center of a 5.8-GHz microwave beam onto a ground station of reasonable area over that tremendous distance—65 times the altitude of LEO satellites like Starlink. Even using a 750-meter transmitter, a receiver station in France or the northern United States would fill an elliptical field covering more than 34 square kilometers. That’s more than two-thirds the size of Bordeaux, France, where I live.
“Success hinges on something that cannot be engineered: sustained political will to keep investing in a multidecade R&D program that ultimately could yield machines that can’t put electricity on the grid.”
Huge components come with huge masses, which lead to exorbitant launch costs. Thales Alenia Space estimated that the transmitter alone would weigh at least 250 tonnes and cost well over a billion dollars to build, launch, and ferry to GEO. That estimate, based on ideas from the Caltech group that have yet to be tested in space, seems wildly optimistic; previous detailed transmitter designs are about 30 times heavier.
Because the transmitter has to be big and expensive, any orbiting solar project will maximize the power it sends through the beam, within acceptable safety limits. That’s why the systems evaluated by NASA, ESA, China, and Japan are all scaled to deliver 1–2 GW, the maximum output that utilities and grid operators now say they are willing to handle. It would take two or three of these giant satellites to replace one large retiring coal or nuclear power station.
Energy is lost at each step in the conversion from sunlight to DC electricity, then to microwaves, then back to DC electricity and finally to a grid-compatible AC current. It will be hard to improve much on the 11 percent end-to-end efficiency seen in recent field trials. So the solar arrays and electrical gear must be big enough to collect, convert, and distribute around 9 GW of power in space just to deliver 1 GW to the grid. No electronic switches, relays, and transformers have been designed or demonstrated for spacecraft that can handle voltages and currents anywhere near the required magnitude.
Some space solar designs, such as SPS-ALPHA and CASSIOPeiA, would suspend huge reflectors on kilometers-long booms to concentrate sunlight onto high-efficiency solar cells on the back side of the transmitter or intermingled with antennas. Other concepts, such as China’s MR-SPS and the design proposed by Thales Alenia Space, would send the currents through heavy, motorized rotating joints that allow the large solar arrays to face the sun while the transmitter pivots to stay fixed on the receiving station on Earth.
 All space solar-power concepts that send energy to Earth via a microwave beam would need a large receiving station on the ground. An elliptical rectenna field 6 to 10 kilometers wide would be covered with antennas and electronics that rectify the microwaves into DC power. Additional inverters would then convert the electricity to grid-compatible AC current.Chris Philpot
All space solar-power concepts that send energy to Earth via a microwave beam would need a large receiving station on the ground. An elliptical rectenna field 6 to 10 kilometers wide would be covered with antennas and electronics that rectify the microwaves into DC power. Additional inverters would then convert the electricity to grid-compatible AC current.Chris Philpot
The net result, regardless of approach, is an orbiting power station that spans several kilometers, totals many thousands of tonnes, sends gigawatts of continuous power through onboard electronics, and comprises up to a million modules that must be assembled in space—by robots. That is a gigantic leap from the largest satellite and solar array ever constructed in orbit: the 420-tonne, 109-meter International Space Station (ISS), whose 164 solar panels produce less than 100 kilowatts to power its 43 modules.
The ISS has been built and maintained by astronauts, drawing on 30 years of prior experience with the Salyut, Skylab, and Mir space stations. But there is no comparable incremental path to a robot-assembled power satellite in GEO. Successfully beaming down a few megawatts from LEO would be an impressive achievement, but it wouldn’t prove that a full-scale system is feasible, nor would the intermittent power be particularly interesting to commercial utilities.
T Minus...Decades?
NASA’s 2024 report used sensitivity analysis to look for advances, however implausible, that would enable orbital solar power to be commercially competitive with nuclear fission and other low-emissions power. To start, the price of sending a tonne of cargo to LEO on a large reusable rocket, which has fallen 36 percent over the past 10 years, would have to drop by another two-thirds, to $500,000. This assumes that all the pieces of the station could be dropped off in low orbit and then raised to GEO over a period of months by space tugs propelled by electrical ion thrusters rather than conventional rockets. The approach would slow the pace of construction and add to the overall mass and cost. New tugs would have to be developed that could tow up to 100 times as much cargo as the biggest electric tugs do today. And by my calculations, the world’s annual production of xenon—the go-to propellant for ion engines—is insufficient to carry even a single solar-power satellite to GEO.
Thales Alenia Space looked at a slightly more realistic option: using a fleet of conventional rockets as big as SpaceX’s new Starship—the largest rocket ever built—to ferry loads from LEO to GEO, and then back to LEO for refueling from an orbiting fuel depot. Even if launch prices plummeted to $200,000 a tonne, they calculated, electricity from their system would be six times as expensive as NASA’s projected cost for a terrestrial solar farm outfitted with battery storage—one obvious alternative.
What else would have to go spectacularly right? In NASA’s cost-competitive scenario, the price of new, specialized spaceships that could maintain the satellite for 30 years—and then disassemble and dispose of it—would have to come down by 90 percent. The efficiency of commercially produced, space-qualified solar cells would have to soar from 32 percent today to 40 percent, while falling in cost. Yet over the past 30 years, big gains in the efficiency of research cells have not translated well to the commercial cells available at low cost [see chart, “Not So Fast”].
Is it possible for all these things to go right simultaneously? Perhaps. But wait—there’s more that can go wrong.
The Toll of Operating a Solar Plant in Space
Let’s start with temperature. Gigawatts of power coursing through the system will make heat removal essential because solar cells lose efficiency and microcircuits fry when they get too hot. A couple of dozen times a year, the satellite will pass suddenly into the utter darkness of Earth’s shadow, causing temperatures to swing by around 300 °C, well beyond the usual operating range of electronics. Thermal expansion and contraction may cause large structures on the station to warp or vibrate.
Then there’s the physical toll of operating in space. Vibrations and torques exerted by altitude-control thrusters, plus the pressure of solar radiation on the massive sail-like arrays, will continually bend and twist the station this way and that. The sprawling arrays will suffer unavoidable strikes from man-made debris and micrometeorites, perhaps even a malfunctioning construction robot. As the number of space power stations increases, we could see a rapid rise in the threat of Kessler syndrome, a runaway cascade of collisions that is every space operator’s nightmare.
Probably the toughest technical obstacle blocking space solar power is a basic one: shaping and aiming the beam. The transmitter is not a dish, like a radio telescope in reverse. It’s a phased array, a collection of millions of little antennas that must work in near-perfect synchrony, each contributing its piece to a collective waveform aimed at the ground station.
Like people in a stadium crowd raising their arms on cue to do “the wave,” coordination of a phased array is essential. It will work properly only if every element on the emitter syncs the phase of its transmission to align precisely with the transmission of its neighbors and with an incoming beacon signal sent from the ground station. Phase errors measured in picoseconds can cause the microwave beam to blur or drift off its target. How can the system synchronize elements separated by as much as a kilometer with such incredible accuracy? If you have the answer, please patent and publish it, because this problem currently has engineers stumped.
There is no denying the beauty of the idea of turning to deep space for inexhaustible electricity. But nature gets a vote. As Lao Tzu observed long ago in the Tao Te Ching, “The truth is not always beautiful, nor beautiful words the truth.”
-
Femtosecond Lasers Solve Solar Panels’ Recycling Issue
by Emily Waltz on 09. May 2024. at 14:35

Solar panels are built to last 25 years or more in all kinds of weather. Key to this longevity is a tight seal of the photovoltaic materials. Manufacturers achieve the seal by laminating a panel’s silicon cells with polymer sheets between glass panes. But the sticky polymer is hard to separate from the silicon cells at the end of a solar panel’s life, making recycling the materials more difficult.
Researchers at the U.S. National Renewable Energy Lab (NREL) in Golden, Colo., say they’ve found a better way to seal solar modules. Using a femtosecond laser, the researchers welded together solar panel glass without the use of polymers such as ethylene vinyl acetate. These glass-to-glass precision welds are strong enough for outdoor solar panels, and are better at keeping out corrosive moisture, the researchers say.
 A femtosecond laser welds a small piece of test glass.NREL
A femtosecond laser welds a small piece of test glass.NREL“Solar panels are not easily recycled,” says David Young, a senior scientist at NREL. “There are companies that are doing it now, but it’s a tricky play between cost and benefit, and most of the problem is with the polymers.” With no adhesive polymers involved, recycling facilities can more easily separate and reuse the valuable materials in solar panels such as silicon, silver, copper, and glass.
Because of the polymer problem, many recycling facilities just trash the polymer-covered silicon cells and recover only the aluminum frames and glass encasements, says Silvana Ovaitt, a photovoltaic (PV) analyst at NREL. This partial recycling wastes the most valuable materials in the modules.
“At some point there’s going to be a huge amount of spent panels out there, and we want to get it right, and make it easy to recycle.” —David Young, NREL
Finding cost-effective ways to recycle all the materials in solar panels will become increasingly important. Manufacturers globally are deploying enough solar panels to produce an additional 240 gigawatts each year. That rate is projected to increase to 3 terawatts by 2030, Ovaitt says. By 2050, anywhere from 54 to 160 million tonnes of PV panels will have reached the end of their life-spans, she says.
“At some point there’s going to be a huge amount of spent panels out there, and we want to get it right, and make it easy to recycle,” says Young. “There’s no reason not to.” A change in manufacturing could help alleviate the problem—although not for at least another 25 years, when panels constructed with the new technique would be due to be retired.
In NREL’s technique, the glass that encases the solar cells in a PV panel is welded together by precision melting. The precision melting is accomplished with femtosecond lasers, which pack a tremendous number of photons into a very short time scale--about 1 millionth of 1 billionth of a second. The number of photons emitted per second from the laser is so intense that it changes the optical absorption process in the glass, says Young. The process changes from linear (normal absorption) to nonlinear, which allows the glass to absorb energy from the photons that it would normally not absorb, he says.
The intense beam, focused near the interface of the two sheets of glass, generates a small plasma of ionized glass atoms. This plasma allows the glass to absorb most of the photons from the laser and locally melt the two glass sheets to form a weld. Because there’s no open surface, there is no evaporation of the molten glass during the welding process. The lack of evaporation from the molten pool allows the glass to cool in a stress-free state, leaving a very strong weld.
 A femtosecond laser creates precision welds between two glass plates.David Young/NREL
A femtosecond laser creates precision welds between two glass plates.David Young/NRELIn stress tests conducted by the NREL group, the welds proved almost as strong as the glass itself, as if there were no weld at all. Young and his colleagues described their proof-of-concept technique in a paper published 21 February in the IEEE Journal of Photovoltaics.
This is the first time a femtosecond laser has been used to test glass-to-glass welds for solar modules, the authors say. The cost of such lasers has declined over the last few years, so researchers are finding uses for them in a wide range of applications. For example, femtosecond lasers have been used to create 3D midair plasma displays and to turn tellurite glass into a semiconductor crystal. They’ve also been used to weld glass in medical devices.
Prior to femtosecond lasers, research groups attempted to weld solar panel glass with nanosecond lasers. But those lasers, with pulses a million times as long as those of a femtosecond laser, couldn’t create a glass-to-glass weld. Researchers tried using a filler material called glass frit in the weld, but the bonds of the dissimilar materials proved too brittle and weak for outdoor solar panel designs, Young says.
In addition to making recycling easier, NREL’s design may make solar panels last longer. Polymers are poor barriers to moisture compared with glass, and the material degrades over time. This lets moisture into the solar cells, and eventually leads to corrosion. “Current solar modules aren’t watertight,” says Young. That will be a problem for perovskite cells, a leading next-generation solar technology that is extremely sensitive to moisture and oxygen.
“If we can provide a different kind of seal where we can eliminate the polymers, not only do we get a better module that lasts longer, but also one that is much easier to recycle,” says Young.
-
Brain-Inspired Computer Approaches Brain-Like Size
by Dina Genkina on 08. May 2024. at 14:38

Today Dresden, Germany–based startup SpiNNcloud Systems announced that its hybrid supercomputing platform, the SpiNNcloud Platform, is available for sale. The machine combines traditional AI accelerators with neuromorphic computing capabilities, using system-design strategies that draw inspiration from the human brain. Systems for purchase vary in size, but the largest commercially available machine can simulate 10 billion neurons, about one-tenth the number in the human brain. The announcement was made at the ISC High Performance conference in Hamburg, Germany.
“We’re basically trying to bridge the gap between brain inspiration and artificial systems.” —Hector Gonzalez, SpiNNcloud Systems
SpiNNcloud Systems was founded in 2021 as a spin-off of the Dresden University of Technology. Its original chip, the SpiNNaker1, was designed by Steve Furber, the principal designer of the ARM microprocessor—the technology that now powers most cellphones. The SpiNNaker1 chip is already in use by 60 research groups in 23 countries, SpiNNcloud Systems says.
Human Brain as Supercomputer
Brain-emulating computers hold the promise of vastly lower energy computation and better performance on certain tasks. “The human brain is the most advanced supercomputer in the universe, and it consumes only 20 watts to achieve things that artificial intelligence systems today only dream of,” says Hector Gonzalez, cofounder and co-CEO of SpiNNcloud Systems. “We’re basically trying to bridge the gap between brain inspiration and artificial systems.”
Aside from sheer size, a distinguishing feature of the SpiNNaker2 system is its flexibility. Traditionally, most neuromorphic computers emulate the brain’s spiking nature: Neurons fire off electrical spikes to communicate with the neurons around them. The actual mechanism of these spikes in the brain is quite complex, and neuromorphic hardware often implements a specific simplified model. The SpiNNaker2 can implement a broad range of such models however, as they are not hardwired into its architecture.
Instead of looking how each neuron and synapse operates in the brain and trying to emulate that from the bottom up, Gonzalez says, the his team’s approach involved implementing key performance features of the brain. “It’s more about taking a practical inspiration from the brain, following particularly fascinating aspects such as how the brain is energy proportional and how it is simply highly parallel,” Gonzalez says.
To build hardware that is energy proportional—each piece draws power only when it’s actively in use and highly parallel—the company started with the building blocks. The basic unit of the system is the SpiNNaker2 chip, which hosts 152 processing units. Each processing unit has an ARM-based microcontroller, and unlike its predecessor the SpiNNaker1, also comes equipped with accelerators for use on neuromorphic models and traditional neural networks.
 The SpiNNaker2 supercomputer has been designed to model up to 10 billion neurons, about one-tenth the number in the human brain. SpiNNCloud Systems
The SpiNNaker2 supercomputer has been designed to model up to 10 billion neurons, about one-tenth the number in the human brain. SpiNNCloud SystemsThe processing units can operate in an event-based manner: They can stay off unless an event triggers them to turn on and operate. This enables energy-proportional operation. The events are routed between units and across chips asynchronously, meaning there is no central clock coordinating their movements—which can allow for massive parallelism. Each chip is connected to six other chips, and the whole system is connected in the shape of a torus to ensure all connecting wires are equally short.
The largest commercially offered system is not only capable of emulating 10 billion neurons, but also performing 0.3 billion billion operations per second (exaops) of more traditional AI tasks, putting it on a comparable scale with the top 10 largest supercomputers today.
Among the first customers of the SpiNNaker2 system is a team at Sandia National Labs, which plans to use it for further research on neuromorphic systems outperforming traditional architectures and performing otherwise inaccessible computational tasks.
“The ability to have a general programmable neuron model lets you explore some of these more complex learning rules that don’t necessarily fit onto older neuromorphic systems,” says Fred Rothganger, senior member of technical staff at Sandia. “They, of course, can run on a general-purpose computer. But those general-purpose computers are not necessarily designed to efficiently handle the kind of communication patterns that go on inside a spiking neural network. With [the SpiNNaker2 system] we get the ideal combination of greater programmability plus efficient communication.”
-
Engineering Needs More Futurists
by Dorota A. Grejner-Brzezinska on 07. May 2024. at 18:00

A quick glance at the news headlines each morning might convey that the world is in crisis. Challenges include climate-change threats to human infrastructure and habitats; cyberwarfare by state and nonstate actors attacking energy sources and health care systems; and the global water crisis, which is compounded by the climate crisis. Perhaps the biggest challenge is the rapid advance of artificial intelligence and what it means for humanity.
As people grapple with those and other issues, they typically look to policymakers and business leaders for answers. However, no true solutions can be developed and implemented without the technical expertise of engineers.
Encouraging visionary, futuristic thinking is the function of the Engineering Research Visioning Alliance. ERVA is an initiative of the U.S. National Science Foundation’s Directorate for Engineering, for which I serve as principal investigator. IEEE is one of several professional engineering societies that are affiliate partners.
Engineers are indispensable architects
Engineers are not simply crucial problem-solvers; they have long proven to be proactive architects of the future. For example, Nobel-winning physicists discovered the science behind the sensors that make modern photography possible. Engineers ran with the discovery, developing technology that NASA could use to send back clear pictures from space, giving us glimpses of universes far beyond our line of sight. The same tech enables you to snap photos with your cellphone.
As an engineer myself, I am proud of our history of not just making change but also envisioning it.
In the late 19th century, electrical engineer Nikola Tesla had envisioned wireless communication, lighting, and power distribution.
As early as 1900, civil engineer John Elfreth Watkins predicted that by 2000 we would have such now-commonplace innovations as color photography, wireless telephones, and home televisions (and even TV dinners), among other things.
“If we are going to successfully tackle today’s most vexing global challenges, engineers cannot be relegated to playing a reactive role.”
Watkins embodied an engineer’s curiosity and prescience, but too often today, we spend the lion’s share of our time with technical tinkering and not enough on the bigger picture.
If we are going to successfully tackle today’s most vexing global challenges, engineers cannot be relegated to playing a reactive role. We need to completely reimagine how nearly everything works. And because complex problems are multifaceted, we must do so in a multidisciplinary fashion.
We need big ideas, future-focused thinking with the foresight to transform how we live, work, and play—a visionary mindset embraced and advanced by engineers who leverage R&D to solve problems and activate discoveries. We need a different attitude from that of the consummate practitioners we typically imagine ourselves to be. We need the mindset of the futurist.
Futuristic thinking transforms society
A futurist studies current events and trends to determine not just predictions but also possibilities for the future. The term futurist has a long connection with science fiction, going back to the early 20th century, personified in such figures as writer H.G. Wells.
While many literary figures’ predictions have proven fanciful (though some, like Elfreth’s, have come true), engineers and scientists have engaged in foresight for generations, introducing new ways to look at our world, and transforming society along the way.
Futuristic thinking pushes the boundaries of what we can currently imagine and conceive. In an era of systemic crises, there is a seemingly paradoxical but accurate truth: It has become impractical to think too pragmatically.
It is especially counterintuitive to engineers, as we are biased toward observable, systematic thinking. But it is a limitation we have overcome through visionary exploits of the past—and one we must overcome now, when the world needs us.
Overcoming systematic thinking
Four times each year, ERVA convenes engineers, scientists, technologists, ethicists, social scientists, and federal science program leads to engage in innovative visioning workshops. We push hard and ask the experts to expand their thinking beyond short-term problems and think big about future possibilities. Some examples of challenges we have addressed—and the subsequent comprehensive reports on recommended research direction for visionary, futuristic thinking—are:
- The Role of Engineering to Address Climate Change. Our first visioning event considered how engineers can help mitigate the effects of rising global temperatures and better reduce carbon emissions. We envisioned how we could use artificial intelligence and other new technologies, including some revolutionary sensors, to proactively assess weather and water security events, decarbonize without disruptions to our energy supply, and slow the pace of warming.
- Engineering R&D Solutions for Unhackable Infrastructure. We considered a future in which humans and computing systems were connected using trustworthy systems, with engineering solutions to self-identity threats and secure systems before they become compromised. Solutions for unhackable infrastructure should be inherent rather than bolted-on, integrated across connected channels, and activated from the system level to wearables. Actions must be taken now to ensure trustworthiness at every level so that the human element is at the forefront of future information infrastructure.
- Engineering Materials for a Sustainable Future. In our most recent report, we discussed a future in which the most ubiquitous, noncircular materials in our world—concrete, chemicals, and single-use packaging—are created using sustainable materials. We embraced the use of organic and reusable materials, examining what it is likely to take to shift production, storage, and transportation in the process. Again, engineers are required to move beyond current solutions and to push the boundaries of what is possible.
ERVA is tackling new topics in upcoming visioning sessions on areas as diverse as the future of wireless competitiveness, quantum engineering, and improving women’s health.
We have an open call for new visioning event ideas. We challenge the engineering community to propose themes for ERVA to explore so we can create a road map of future research priorities to solve societal challenges. Engineers are needed to share their expertise, so visit our website to follow this critical work. It is time we recaptured that futurist spirit.
-
What Can AI Researchers Learn From Alien Hunters?
by Edmon Begoli on 07. May 2024. at 12:00

The emergence of artificial general intelligence (AGI)—systems that can perform any task a human can—could be the most important event in human history, one that radically affects all aspects of our collective lives. Yet AGI, which could emerge soon, remains an elusive and controversial concept. We lack a clear definition of what it is, we don’t know how we will detect it, and we don’t know how to deal with it if it finally emerges.
What we do know, however, is that today’s approaches to studying AGI are not nearly rigorous enough. Within industry, where many of today’s AI breakthroughs are happening, companies like OpenAI are actively striving to create AGI, but include research on AGI’s social dimensions and safety issues only as their corporate leaders see fit. While the academic community looks at AGI more broadly, seeking the characteristics of a new intelligent life-form, academic institutions don’t have the resources for a significant effort.
Thinking about AGI calls to mind another poorly understood and speculative phenomenon with the potential for transformative impacts on humankind. We believe that the SETI Institute’s efforts to detect advanced extraterrestrial intelligence demonstrate several valuable concepts that can be adapted for AGI research. Instead of taking a dogmatic or sensationalist stance, the SETI project takes a scientifically rigorous and pragmatic approach—putting the best possible mechanisms in place for the definition, detection, and interpretation of signs of possible alien intelligence.
The idea behind SETI goes back 60 years, to the beginning of the space age. In their 1959 Nature paper, the physicists Giuseppe Cocconi and Philip Morrison described the need to search for interstellar communication. Assuming the uncertainty of extraterrestrial civilizations’ existence and technological sophistication, they theorized about how an alien society would try to communicate and discussed how we should best “listen” for messages. Inspired by this position, we argue for a similar approach to studying AGI, in all its uncertainties.
AI researchers are still debating how probable it is that AGI will emerge and how to detect it. However, the challenges in defining AGI and the difficulties in measuring it are not a justification for ignoring it or for taking a “we’ll know when we see it” approach. On the contrary, these issues strengthen the need for an interdisciplinary approach to AGI detection, evaluation, and public education, including a science-based approach to the risks associated with AGI.
We need a SETI-like approach to AGI now
The last few years have shown a vast leap in AI capabilities. The large language models (LLMs) that power chatbots like ChatGPT, which can converse convincingly with humans, have renewed the discussion about AGI. For example, recent articles have stated that ChatGPT shows “sparks” of AGI, is capable of reasoning, and outperforms humans in many evaluations.
While these claims are intriguing and exciting, there are reasons to be skeptical. In fact, a large group of scientists argue that the current set of tools won’t bring us any closer to true AGI. But given the risks associated with AGI, if there is even a small likelihood of it occurring, we must make a serious effort to develop a standard definition of AGI, establish a SETI-like approach to detecting it, and devise ways to safely interact with it if it emerges.
Challenge 1: How to define AGI
The crucial first step is to define what exactly to look for. In SETI’s case, researchers decided to look for so-called narrow-band signals distinct from other radio signals present in the cosmic background. These signals are considered intentional and only produced by intelligent life.
In the case of AGI, matters are far more complicated. Today, there is no clear definition of “artificial general intelligence” (other terms, such as strong AI, human-level intelligence, and superintelligence are also widely used to describe similar concepts). The term is hard to define because it contains other imprecise and controversial terms. Although “intelligence” is defined in the Oxford Dictionary as “the ability to acquire and apply knowledge and skills,” there is still much debate on which skills are involved and how they can be measured. The term “general” is also ambiguous. Does an AGI need to be able to do everything a human can do? Is generality a quality we measure as a binary or continuous variable?
One of the first missions of a “SETI for AGI” construct must be to clearly define the terms “general” and “intelligence” so the research community can speak about them concretely and consistently. These definitions need to be grounded in the disciplines supporting the AGI concept, such as computer science, measurement science, neuroscience, psychology, mathematics, engineering, and philosophy. Once we have clear definitions of these terms, we’ll need to find ways to measure them.
There’s also the crucial question of whether a true AGI must include consciousness, personhood, and self-awareness. These terms also have multiple definitions, and the relationships between them and intelligence must be clarified. Although it’s generally thought that consciousness isn’t necessary for intelligence, it’s often intertwined with discussions of AGI because creating a self-aware machine would have many philosophical, societal, and legal implications. Would a new large language model that can answer an IQ test better than a human be as important to detect as a truly conscious machine?
 Getty Images
Getty ImagesChallenge 2: How to measure AGI
In the case of SETI, if a candidate narrow-band signal is detected, an expert group will verify that it is indeed an extraterrestrial source. They’ll use established criteria—for example, looking at the signal type and source and checking for repetition—and conduct all the assessments at multiple facilities for additional validation.
How to best measure computer intelligence has been a long-standing question in the field. In a famous 1950 paper, Alan Turing proposed the “imitation game,” now more widely known as the Turing Test, which assesses whether human interlocutors can distinguish if they are chatting with a human or a machine. Although the Turing Test has been useful for evaluations in the past, the rise of LLMs has made it clear that it’s not a complete enough test to measure intelligence. As Turing noted in his paper, the imitation game does an excellent job of testing if a computer can imitate the language-generation process, but the relationship between imitating language and thinking is still an open question. Other techniques will certainly be needed.
These appraisals must be directed at different dimensions of intelligence. Although measures of human intelligence are controversial, IQ tests can provide an initial baseline to assess one dimension. In addition, cognitive tests on topics such as creative problem-solving, rapid learning and adaptation, reasoning, goal-directed behavior, and self-awareness would be required to assess the general intelligence of a system.
These cognitive tests will be useful, but it’s important to remember that they were designed for humans and might contain certain assumptions about basic human capabilities that might not apply to computers, even those with AGI abilities. For example, depending on how it’s trained, a machine may score very high on an IQ test but remain unable to solve much simpler tasks. In addition, the AI may have other communication modalities and abilities that would not be measurable by our traditional tests.
There’s a clear need to design novel evaluations to measure AGI or its subdimensions accurately. This process would also require a diverse set of researchers from different fields who deeply understand AI, are familiar with the currently available tests, and have the competency, creativity, and foresight to design novel tests. These measurements will hopefully alert us when meaningful progress is made toward AGI.
Once we have developed a standard definition of AGI and developed methodologies to detect it, we must devise a way to address its emergence.
Challenge 3: How to deal with AGI
Once we have discovered this new form of intelligence, we must be prepared to answer questions such as: Is the newly discovered intelligence a new form of life? What kinds of rights does it have? What kinds of rights do we have regarding this intelligence? What are the potential safety concerns, and what is our approach to handling the AGI entity, containing it, and safeguarding ourselves from it?
Here, too, SETI provides inspiration. SETI has protocols for handling the evidence of a sign of extraterrestrial intelligence. SETI’s post-detection protocols emphasize validation, transparency, and cooperation with the United Nations, with the goal of maximizing the credibility of the process, minimizing sensationalism, and bringing structure to such a profound event.
As with extraterrestrial intelligence, we need protocols for safe and secure interactions with AGI. These AGI protocols would serve as the internationally recognized framework for validating emergent AGI properties, bringing transparency to the entire process, ensuring international cooperation, applying safety-related best practices, and handling any ethical, social, and philosophical concerns.
We readily acknowledge that the SETI analogy can only go so far. If AGI emerges, it will be a human-made phenomenon. We will likely gradually engineer AGI and see it slowly emerge, so detection might be a process that takes place over a period of years, if not decades. In contrast, the existence of extraterrestrial life is something that we have no control over, and contact could happen very suddenly.
The discovery of a true AGI would be the most profound development in the history of science, and its consequences would be also entirely unpredictable. To best prepare, we need a methodical, comprehensive, principled, and interdisciplinary approach to defining, detecting, and dealing with AGI. With SETI as an inspiration, we propose that the AGI research community establish a similar framework to ensure an unbiased, scientific, transparent, and collaborative approach to dealing with possibly the most important development in human history.
-
IEEE’s Honor Society Expands to More Countries
by Kathy Pretz on 03. May 2024. at 18:46

The IEEE–Eta Kappa Nu honor society for engineers celebrates its 120th anniversary this year. Founded in October 1904, IEEE-HKN recognizes academic experience as well as excellence in scholarship, leadership, and service. Inductees are chosen based on their technical, scientific, and leadership achievements. There are now more than 270 IEEE-HKN chapters at universities around the world.
The society has changed significantly over the years. Global expansion resulted from the merger of North America–based HKN with IEEE in 2010. There are now 30 chapters outside the United States, including ones recently established at universities in Ecuador, Hungary, and India.
IEEE-HKN has more than 200,000 members around the world. Since the merger, more than 37,000 people have been inducted. Membership now extends beyond just students. Among them are 23 former IEEE presidents as well as a who’s who of engineering leaders and technology pioneers including GM Chief Executive Mary Barra, Google founding CEO Larry Page, and Advanced Micro Devices CEO Lisa Su. Last year more than 100 professional members were added to the rolls.
“If you want to make sure that you’re on the forefront of engineering leadership, you should definitely consider joining IEEE-HKN.” —Joseph Greene
In 1950 HKN established the category of eminent member to honor those whose contributions significantly benefited society. There now are 150 such members. They include the fathers of the Internet and IEEE Medal of Honor recipients Vint Cerf and Bob Kahn; former astronaut Sandra Magnus; and Henry Samueli, a Broadcom founder.
IEEE-HKN is celebrating its anniversary on 28 October, Founders Day, the date the society was established. A variety of activities are scheduled for the day at chapters and other locations around the world, says Nancy Ostin, the society’s director.
New chapters in Ecuador, Hungary, and India
Several chapters have been established in recent months. The Nu Eta chapter at the Sri Sairam Engineering College, in Chennai, India, was founded in September, becoming the fourth chapter in the country. In October the Nu Theta chapter debuted at Purdue University Northwest in Hammond, Ind.
 Students from the IEEE-HKN Lambda Chi chapter at Hampton University in Virginia celebrate their induction with a cake. IEEE-Eta Kappa Nu
Students from the IEEE-HKN Lambda Chi chapter at Hampton University in Virginia celebrate their induction with a cake. IEEE-Eta Kappa NuSo far this year, chapters were formed at the Escuela Superior Politécnica del Litoral, in Guayaquil, Ecuador; Hampton University in Virginia; Óbuda University, in Budapest; and Polytechnic University of Puerto Rico in San Juan, the second chapter in the territory. Hampton is a historically Black research university.
A focus on career development
IEEE-HKN’s benefits have expanded over time. The society now focuses more on helping its members with career development. Career-related services on the society’s website include a job board and a resource center that aids with writing résumés and cover letters, as well as interview tips and career coaching services.
 2024 IEEE-HKN president Ryan Bales [center] with members of the Nu Iota chapter at Óbuda University in Budapest. IEEE-Eta Kappa Nu
2024 IEEE-HKN president Ryan Bales [center] with members of the Nu Iota chapter at Óbuda University in Budapest. IEEE-Eta Kappa NuThere’s also the HKN Career Conversations podcast, hosted by society alumni. Topics they’ve covered include ethics, workplace conflicts, imposter syndrome, and cultivating creativity.
The honor society also holds networking events including its annual international leadership conferences, where student leaders from across the world collaborate on how they can benefit the organization and their communities.
Mentorship and networking opportunities
IEEE-HKN’s mentoring program connects recent graduates with alumni. IEEE professionals are paired with graduate students based on technical interest, desired mentoring area, and personality.
Alumnus Joseph Greene, a Ph.D. candidate in computational imaging at Boston University, joined the school’s Kappa Sigma chapter in 2014 and continues to mentor graduate students and help organize events to engage alumni. Greene has held several leadership positions with the chapter, including president, vice president, and student governor on the IEEE-HKN board.
He created a professional-to-student mentoring program for the chapter. It partners people from industry and academia with students to build working relationships and to provide career, technical, and personal advice. Since the program launched in 2022, Greene says, more than 40 people have participated.
“What I found most rewarding about having a mentor is they offer a much broader perspective than just your collegiate needs,” he said in the interview with The Institute.
Another program Greene launched is the IEEE-HKN GradLab YouTube podcast, which he says covers “everything about grad school that they don’t teach you in a classroom.”
“If you want to make sure that you’re on the forefront of engineering leadership, you should definitely consider joining IEEE-HKN,” Greene said in the interview. “The organization, staff, and volunteers are dedicated toward making sure you have the opportunity, resources, and network to thrive and succeed.”
If you were ever inducted into IEEE-HKN, your membership never expires, Ostin notes. Check your IEEE membership record. The honor society’s name should appear there but if it does not, complete the alumni reconnect form.
-
Video Friday: Loco-Manipulation
by Evan Ackerman on 03. May 2024. at 16:22

Video Friday is your weekly selection of awesome robotics videos, collected by your friends at IEEE Spectrum robotics. We also post a weekly calendar of upcoming robotics events for the next few months. Please send us your events for inclusion.
Eurobot Open 2024: 8–11 May 2024, LA ROCHE-SUR-YON, FRANCE
ICRA 2024: 13–17 May 2024, YOKOHAMA, JAPAN
RoboCup 2024: 17–22 July 2024, EINDHOVEN, NETHERLANDS
Cybathlon 2024: 25–27 October 2024, ZURICH
Enjoy today’s videos!
In this work, we present LocoMan, a dexterous quadrupedal robot with a novel morphology to perform versatile manipulation in diverse constrained environments. By equipping a Unitree Go1 robot with two low-cost and lightweight modular 3-DoF loco-manipulators on its front calves, LocoMan leverages the combined mobility and functionality of the legs and grippers for complex manipulation tasks that require precise 6D positioning of the end effector in a wide workspace.
[ CMU ]
Thanks, Changyi!
Object manipulation has been extensively studied in the context of fixed-base and mobile manipulators. However, the overactuated locomotion modality employed by snake robots allows for a unique blend of object manipulation through locomotion, referred to as loco-manipulation. In this paper, we present an optimization approach to solving the loco-manipulation problem based on nonimpulsive implicit-contact path planning for our snake robot COBRA.
Okay, but where that costume has eyes is not where Spot has eyes, so the Spot in the costume can’t see, right? And now I’m skeptical of the authenticity of the mutual snoot-boop.
[ Boston Dynamics ]
Here’s some video of Field AI’s robots operating in relatively complex and unstructured environments without prior maps. Make sure to read our article from this week for details!
[ Field AI ]
Is it just me, or is it kind of wild that researchers are now publishing papers comparing their humanoid controller to the “manufacturer’s” humanoid controller? It’s like humanoids are a commodity now or something.
[ OSU ]
I, too, am packing armor for ICRA.
[ Pollen Robotics ]
Honey Badger 4.0 is our latest robotic platform, created specifically for traversing hostile environments and difficult terrains. Equipped with multiple cameras and sensors, it will make sure no defect is omitted during inspection.
[ MAB Robotics ]
Thanks, Jakub!
Have an automation task that calls for the precision and torque of an industrial robot arm…but you need something that is more rugged or a nonconventional form factor? Meet the HEBI Robotics H-Series Actuator! With 9x the torque of our X-Series and seamless compatibility with the HEBI ecosystem for robot development, the H-Series opens a new world of possibilities for robots.
[ HEBI ]
Thanks, Dave!
This is how all spills happen at my house too: super passive-aggressively.
[ 1X ]
EPFL’s team, led by Ph.D. student Milad Shafiee along with coauthors Guillaume Bellegarda and BioRobotics Lab head Auke Ijspeert, have trained a four-legged robot using deep-reinforcement learning to navigate challenging terrain, achieving a milestone in both robotics and biology.
[ EPFL ]
At Agility, we make robots that are made for work. Our robot Digit works alongside us in spaces designed for people. Digit handles the tedious and repetitive tasks meant for a machine, allowing companies and their people to focus on the work that requires the human element.
[ Agility ]
With a wealth of incredible figures and outstanding facts, here’s Jan Jonsson, ABB Robotics veteran, sharing his knowledge and passion for some of our robots and controllers from the past.
[ ABB ]
I have it on good authority that getting robots to mow a lawn (like, any lawn) is much harder than it looks, but Electric Sheep has built a business around it.
[ Electric Sheep ]
The AI Index, currently in its seventh year, tracks, collates, distills, and visualizes data relating to artificial intelligence. The Index provides unbiased, rigorously vetted, and globally sourced data for policymakers, researchers, journalists, executives, and the general public to develop a deeper understanding of the complex field of AI. Led by a steering committee of influential AI thought leaders, the Index is the world’s most comprehensive report on trends in AI. In this seminar, HAI Research Manager Nestor Maslej offers highlights from the 2024 report, explaining trends related to research and development, technical performance, technical AI ethics, the economy, education, policy and governance, diversity, and public opinion.
[ Stanford HAI ]
This week’s CMU Robotics Institute seminar, from Dieter Fox at Nvidia and the University of Washington, is “Where’s RobotGPT?”
In this talk, I will discuss approaches to generating large datasets for training robot-manipulation capabilities, with a focus on the role simulation can play in this context. I will show some of our prior work, where we demonstrated robust sim-to-real transfer of manipulation skills trained in simulation, and then present a path toward generating large-scale demonstration sets that could help train robust, open-world robot-manipulation models.
[ CMU ]
-
The UK's ARIA Is Searching For Better AI Tech
by Dina Genkina on 01. May 2024. at 16:10
Dina Genkina: Hi, I’m Dina Genkina for IEEE Spectrum‘s Fixing the Future. Before we start, I want to tell you that you can get the latest coverage from some of Spectrum‘s most important beats, including AI, climate change, and robotics, by signing up for one of our free newsletters. Just go to spectrum.ieee.org/newsletters to subscribe. And today our guest on the show is Suraj Bramhavar. Recently, Bramhavar left his job as a co-founder and CTO of Sync Computing to start a new chapter. The UK government has just founded the Advanced Research Invention Agency, or ARIA, modeled after the US’s own DARPA funding agency. Bramhavar is heading up ARIA’s first program, which officially launched on March 12th of this year. Bramhavar’s program aims to develop new technology to make AI computation 1,000 times more cost efficient than it is today. Siraj, welcome to the show.
Suraj Bramhavar: Thanks for having me.
Genkina: So your program wants to reduce AI training costs by a factor of 1,000, which is pretty ambitious. Why did you choose to focus on this problem?
Bramhavar: So there’s a couple of reasons why. The first one is economical. I mean, AI is basically to become the primary economic driver of the entire computing industry. And to train a modern large-scale AI model costs somewhere between 10 million to 100 million pounds now. And AI is really unique in the sense that the capabilities grow with more computing power thrown at the problem. So there’s kind of no sign of those costs coming down anytime in the future. And so this has a number of knock-on effects. If I’m a world-class AI researcher, I basically have to choose whether I go work for a very large tech company that has the compute resources available for me to do my work or go raise 100 million pounds from some investor to be able to do cutting edge research. And this has a variety of effects. It dictates, first off, who gets to do the work and also what types of problems get addressed. So that’s the economic problem. And then separately, there’s a technological one, which is that all of this stuff that we call AI is built upon a very, very narrow set of algorithms and an even narrower set of hardware. And this has scaled phenomenally well. And we can probably continue to scale along kind of the known trajectories that we have. But it’s starting to show signs of strain. Like I just mentioned, there’s an economic strain, there’s an energy cost to all this. There’s logistical supply chain constraints. And we’re seeing this now with kind of the GPU crunch that you read about in the news.
And in some ways, the strength of the existing paradigm has kind of forced us to overlook a lot of possible alternative mechanisms that we could use to kind of perform similar computations. And this program is designed to kind of shine a light on those alternatives.
Genkina: Yeah, cool. So you seem to think that there’s potential for pretty impactful alternatives that are orders of magnitude better than what we have. So maybe we can dive into some specific ideas of what those are. And you talk about in your thesis that you wrote up for the start of this program, you talk about natural computing systems. So computing systems that take some inspiration from nature. So can you explain a little bit what you mean by that and what some of the examples of that are?
Bramhavar: Yeah. So when I say natural-based or nature-based computing, what I really mean is any computing system that either takes inspiration from nature to perform the computation or utilizes physics in a new and exciting way to perform computation. So you can think about kind of people have heard about neuromorphic computing. Neuromorphic computing fits into this category, right? It takes inspiration from nature and usually performs a computation in most cases using digital logic. But that represents a really small slice of the overall breadth of technologies that incorporate nature. And part of what we want to do is highlight some of those other possible technologies. So what do I mean when I say nature-based computing? I think we have a solicitation call out right now, which calls out a few things that we’re interested in. Things like new types of in-memory computing architectures, rethinking AI models from an energy context. And we also call out a couple of technologies that are pivotal for the overall system to function, but are not necessarily so eye-catching, like how you interconnect chips together, and how you simulate a large-scale system of any novel technology outside of the digital landscape. I think these are critical pieces to realizing the overall program goals. And we want to put some funding towards kind of boosting that workup as well.
Genkina: Okay, so you mentioned neuromorphic computing is a small part of the landscape that you’re aiming to explore here. But maybe let’s start with that. People may have heard of neuromorphic computing, but might not know exactly what it is. So can you give us the elevator pitch of neuromorphic computing?
Bramhavar: Yeah, my translation of neuromorphic computing— and this may differ from person to person, but my translation of it is when you kind of encode the information in a neural network via spikes rather than kind of discrete values. And that modality has shown to work pretty well in certain situations. So if I have some camera and I need a neural network next to that camera that can recognize an image with very, very low power or very, very high speed, neuromorphic systems have shown to work remarkably well. And they’ve worked in a variety of other applications as well. One of the things that I haven’t seen, or maybe one of the drawbacks of that technology that I think I would love to see someone solve for is being able to use that modality to train large-scale neural networks. So if people have ideas on how to use neuromorphic systems to train models at commercially relevant scales, we would love to hear about them and that they should submit to this program call, which is out.
Genkina: Is there a reason to expect that these kinds of— that neuromorphic computing might be a platform that promises these orders of magnitude cost improvements?
Bramhavar: I don’t know. I mean, I don’t know actually if neuromorphic computing is the right technological direction to realize that these types of orders of magnitude cost improvements. It might be, but I think we’ve intentionally kind of designed the program to encompass more than just that particular technological slice of the pie, in part because it’s entirely possible that that is not the right direction to go. And there are other more fruitful directions to put funding towards. Part of what we’re thinking about when we’re designing these programs is we don’t really want to be prescriptive about a specific technology, be it neuromorphic computing or probabilistic computing or any particular thing that has a name that you can attach to it. Part of what we tried to do is set a very specific goal or a problem that we want to solve. Put out a funding call and let the community kind of tell us which technologies they think can best meet that goal. And that’s the way we’ve been trying to operate with this program specifically. So there are particular technologies we’re kind of intrigued by, but I don’t think we have any one of them selected as like kind of this is the path forward.
Genkina: Cool. Yeah, so you’re kind of trying to see what architecture needs to happen to make computers as efficient as brains or closer to the brain’s efficiency.
Bramhavar: And you kind of see this happening in the AI algorithms world. As these models get bigger and bigger and grow their capabilities, they’re starting to introduce things that we see in nature all the time. I think probably the most relevant example is this stable diffusion, this neural network model where you can type in text and generate an image. It’s got diffusion in the name. Diffusion is a natural process. Noise is a core element of this algorithm. And so there’s lots of examples like this where they’ve kind of— that community is taking bits and pieces or inspiration from nature and implementing it into these artificial neural networks. But in doing that, they’re doing it incredibly inefficiently.
Genkina: Yeah. Okay, so great. So the idea is to take some of the efficiencies out in nature and kind of bring them into our technology. And I know you said you’re not prescribing any particular solution and you just want that general idea. But nevertheless, let’s talk about some particular solutions that have been worked on in the past because you’re not starting from zero and there are some ideas about how to do this. So I guess neuromorphic computing is one such idea. Another is this noise-based computing, something like probabilistic computing. Can you explain what that is?
Bramhavar: Noise is a very intriguing property? And there’s kind of two ways I’m thinking about noise. One is just how do we deal with it? When you’re designing a digital computer, you’re effectively designing noise out of your system, right? You’re trying to eliminate noise. And you go through great pains to do that. And as soon as you move away from digital logic into something a little bit more analog, you spend a lot of resources fighting noise. And in most cases, you eliminate any benefit that you get from your kind of newfangled technology because you have to fight this noise. But in the context of neural networks, what’s very interesting is that over time, we’ve kind of seen algorithms researchers discover that they actually didn’t need to be as precise as they thought they needed to be. You’re seeing the precision kind of come down over time. The precision requirements of these networks come down over time. And we really haven’t hit the limit there as far as I know. And so with that in mind, you start to ask the question, “Okay, how precise do we actually have to be with these types of computations to perform the computation effectively?” And if we don’t need to be as precise as we thought, can we rethink the types of hardware platforms that we use to perform the computations?
So that’s one angle is just how do we better handle noise? The other angle is how do we exploit noise? And so there’s kind of entire textbooks full of algorithms where randomness is a key feature. I’m not talking necessarily about neural networks only. I’m talking about all algorithms where randomness plays a key role. Neural networks are kind of one area where this is also important. I mean, the primary way we train neural networks is stochastic gradient descent. So noise is kind of baked in there. I talked about stable diffusion models like that where noise becomes a key central element. In almost all of these cases, all of these algorithms, noise is kind of implemented using some digital random number generator. And so there the thought process would be, “Is it possible to redesign our hardware to make better use of the noise, given that we’re using noisy hardware to start with?” Notionally, there should be some savings that come from that. That presumes that the interface between whatever novel hardware you have that is creating this noise, and the hardware you have that’s performing the computing doesn’t eat away all your gains, right? I think that’s kind of the big technological roadblock that I’d be keen to see solutions for, outside of the algorithmic piece, which is just how do you make efficient use of noise.
When you’re thinking about implementing it in hardware, it becomes very, very tricky to implement it in a way where whatever gains you think you had are actually realized at the full system level. And in some ways, we want the solutions to be very, very tricky. The agency is designed to fund very high risk, high reward type of activities. And so there in some ways shouldn’t be consensus around a specific technological approach. Otherwise, somebody else would have likely funded it.
Genkina: You’re already becoming British. You said you were keen on the solution.
Bramhavar: I’ve been here long enough.
Genkina: It’s showing. Great. Okay, so we talked a little bit about neuromorphic computing. We talked a little bit about noise. And you also mentioned some alternatives to backpropagation in your thesis. So maybe first, can you explain for those that might not be familiar what backpropagation is and why it might need to be changed?
Bramhavar: Yeah, so this algorithm is essentially the bedrock of all AI training currently you use today. Essentially, what you’re doing is you have this large neural network. The neural network is composed of— you can think about it as this long chain of knobs. And you really have to tune all the knobs just right in order to get this network to perform a specific task, like when you give it an image of a cat, it says that it is a cat. And so what backpropagation allows you to do is to tune those knobs in a very, very efficient way. Starting from the end of your network, you kind of tune the knob a little bit, see if your answer gets a little bit closer to what you’d expect it to be. Use that information to then tune the knobs in the previous layer of your network and keep on doing that iteratively. And if you do this over and over again, you can eventually find all the right positions of your knobs such that your network does whatever you’re trying to do. And so this is great. Now, the issue is every time you tune one of these knobs, you’re performing this massive mathematical computation. And you’re typically doing that across many, many GPUs. And you do that just to tweak the knob a little bit. And so you have to do it over and over and over and over again to get the knobs where you need to go.
There’s a whole bevy of algorithms. What you’re really doing is kind of minimizing error between what you want the network to do and what it’s actually doing. And if you think about it along those terms, there’s a whole bevy of algorithms in the literature that kind of minimize energy or error in that way. None of them work as well as backpropagation. In some ways, the algorithm is beautiful and extraordinarily simple. And most importantly, it’s very, very well suited to be parallelized on GPUs. And I think that is part of its success. But one of the things I think both algorithmic researchers and hardware researchers fall victim to is this chicken and egg problem, right? Algorithms researchers build algorithms that work well on the hardware platforms that they have available to them. And at the same time, hardware researchers develop hardware for the existing algorithms of the day. And so one of the things we want to try to do with this program is blend those worlds and allow algorithms researchers to think about what is the field of algorithms that I could explore if I could rethink some of the bottlenecks in the hardware that I have available to me. Similarly in the opposite direction.
Genkina: Imagine that you succeeded at your goal and the program and the wider community came up with a 1/1000s compute cost architecture, both hardware and software together. What does your gut say that that would look like? Just an example. I know you don’t know what’s going to come out of this, but give us a vision.
Bramhavar: Similarly, like I said, I don’t think I can prescribe a specific technology. What I can say is that— I can say with pretty high confidence, it’s not going to just be one particular technological kind of pinch point that gets unlocked. It’s going to be a systems level thing. So there may be individual technology at the chip level or the hardware level. Those technologies then also have to meld with things at the systems level as well and the algorithms level as well. And I think all of those are going to be necessary in order to reach these goals. I’m talking kind of generally, but what I really mean is like what I said before is we got to think about new types of hardware. We also have to think about, “Okay, if we’re going to scale these things and manufacture them in large volumes cost effectively, we’re going to have to build larger systems out of building blocks of these things. So we’re going to have to think about how to stitch them together in a way that makes sense and doesn’t eat away any of the benefits. We’re also going to have to think about how to simulate the behavior of these things before we build them.” I think part of the power of the digital electronics ecosystem comes from the fact that you have cadence and synopsis and these EDA platforms that allow you with very high accuracy to predict how your circuits are going to perform before you build them. And once you get out of that ecosystem, you don’t really have that.
So I think it’s going to take all of these things in order to actually reach these goals. And I think part of what this program is designed to do is kind of change the conversation around what is possible. So by the end of this, it’s a four-year program. We want to show that there is a viable path towards this end goal. And that viable path could incorporate kind of all of these aspects of what I just mentioned.
Genkina: Okay. So the program is four years, but you don’t necessarily expect like a finished product of a 1/1000s cost computer by the end of the four years, right? You kind of just expect to develop a path towards it.
Bramhavar: Yeah. I mean, ARIA was kind of set up with this kind of decadal time horizon. We want to push out-- we want to fund, as I mentioned, high-risk, high reward technologies. We have this kind of long time horizon to think about these things. I think the program is designed around four years in order to kind of shift the window of what the world thinks is possible in that timeframe. And in the hopes that we change the conversation. Other folks will pick up this work at the end of that four years, and it will have this kind of large-scale impact on a decadal.
Genkina: Great. Well, thank you so much for coming today. Today we spoke with Dr. Suraj Bramhavar, lead of the first program headed up by the UK’s newest funding agency, ARIA. He filled us in on his plans to reduce AI costs by a factor of 1,000, and we’ll have to check back with him in a few years to see what progress has been made towards this grand vision. For IEEE Spectrum, I’m Dina Genkina, and I hope you’ll join us next time on Fixing the Future.
-
A Brief History of the World’s First Planetarium
by Allison Marsh on 01. May 2024. at 15:00

In 1912, Oskar von Miller, an electrical engineer and founder of the Deutsches Museum, had an idea: Could you project an artificial starry sky onto a dome, as a way of demonstrating astronomical principles to the public?
It was such a novel concept that when von Miller approached the Carl Zeiss company in Jena, Germany, to manufacture such a projector, they initially rebuffed him. Eventually, they agreed, and under the guidance of lead engineer Walther Bauersfeld, Zeiss created something amazing.
The use of models to show the movements of the planets and stars goes back centuries, starting with mechanical orreries that used clockwork mechanisms to depict our solar system. A modern upgrade was Clair Omar Musser’s desktop electric orrery, which he designed for the Seattle World’s Fair in 1962.
The projector that Zeiss planned for the Deutsches Museum would be far more elaborate. For starters, there would be two planetariums. One would showcase the Copernican, or heliocentric, sky, displaying the stars and planets as they revolved around the sun. The other would show the Ptolemaic, or geocentric, sky, with the viewer fully immersed in the view, as if standing on the surface of the Earth, seemingly at the center of the universe.
The task of realizing those ideas fell to Bauersfeld, a mechanical engineer by training and a managing director at Zeiss.
 Zeiss engineer Walther Bauersfeld worked out the electromechanical details of the planetarium. In this May 1920 entry from his lab notebook [right], he sketched the two-axis system for showing the daily and annual motions of the stars.ZEISS Archive
Zeiss engineer Walther Bauersfeld worked out the electromechanical details of the planetarium. In this May 1920 entry from his lab notebook [right], he sketched the two-axis system for showing the daily and annual motions of the stars.ZEISS ArchiveAt first, Bauersfeld focused on projecting just the sun, moon, and planets of our solar system. At the suggestion of his boss, Rudolf Straubel, he added stars. World War I interrupted the work, but by 1920 Bauersfeld was back at it. One entry in May 1920 in Bauersfeld’s meticulous lab notebook showed the earliest depiction of the two-axis design that allowed for the display of the daily as well as the annual motions of the stars. (The notebook is preserved in the Zeiss Archive.)
The planetarium projector was in fact a concatenation of many smaller projectors and a host of gears. According to the Zeiss Archive, a large sphere held all of the projectors for the fixed stars as well as a “planet cage” that held projectors for the sun, the moon, and the planets Mercury, Venus, Mars, Jupiter, and Saturn. The fixed-star sphere was positioned so that it projected outward from the exact center of the dome. The planetarium also had projectors for the Milky Way and the names of major constellations.
The projectors within the planet cage were organized in tiers with complex gearing that allowed a motorized drive to move them around one axis to simulate the annual rotations of these celestial objects against the backdrop of the stars. The entire projector could also rotate around a second axis, simulating the Earth’s polar axis, to show the rising and setting of the sun, moon, and planets over the horizon.
 The Zeiss planetarium projected onto a spherical surface, which consisted of a geodesic steel lattice overlaid with concrete.Zeiss Archive
The Zeiss planetarium projected onto a spherical surface, which consisted of a geodesic steel lattice overlaid with concrete.Zeiss ArchiveBauersfeld also contributed to the design of the surrounding projection dome, which achieved its exactly spherical surface by way of a geodesic network of steel rods covered by a thin layer of concrete.
Planetariums catch on worldwide
The first demonstration of what became known as the Zeiss Model I projector took place on 21 October 1923 before the Deutsches Museum committee in their not-yet-completed building, in Munich. “This planetarium is a marvel,” von Miller declared in an administrative report.
 In 1924, public demonstrations of the Zeiss planetarium took place on the roof of the company’s factory in Jena, Germany.ZEISS Archive
In 1924, public demonstrations of the Zeiss planetarium took place on the roof of the company’s factory in Jena, Germany.ZEISS ArchiveThe projector then returned north to Jena for further adjustments and testing. The company also began offering demonstrations of the projector in a makeshift dome on the roof of its factory. From July to September 1924, more than 30,000 visitors experienced the Zeisshimmel (Zeiss sky) this way. These demonstrations became informal visitor-experience studies and allowed Zeiss and the museum to make refinements and improvements.
On 7 May 1925, the world’s first projection planetarium officially opened to the public at the Deutsches Museum. The Zeiss Model I displayed 4,500 stars, the band of the Milky Way, the sun, moon, Mercury, Venus, Mars, Jupiter, and Saturn. Gears and motors moved the projector to replicate the changes in the sky as Earth rotated on its axis and revolved around the sun. Visitors viewed this simulation of the night sky from the latitude of Munich and in the comfort of a climate-controlled building, although at first chairs were not provided. (I get a crick in the neck just thinking about it.) The projector was bolted to the floor, but later versions were mounted on rails to move them back and forth. A presenter operated the machine and lectured on astronomical topics, pointing out constellations and the orbits of the planets.
 Word of the Zeiss planetarium spread quickly, through postcards and images.ZEISS Archive
Word of the Zeiss planetarium spread quickly, through postcards and images.ZEISS ArchiveThe planetarium’s influence quickly extended far beyond Germany, as museums and schools around the world incorporated the technology into immersive experiences for science education and public outreach. Each new planetarium was greeted with curiosity and excitement. Postcards and images of planetariums (both the distinctive domed buildings and the complicated machines) circulated widely.
In 1926, Zeiss opened its own planetarium in Jena based on Bauersfeld’s specifications. The first city outside of Germany to acquire a Zeiss planetarium was Vienna. It opened in a temporary structure on 7 May 1927 and in a permanent structure four years later, only to be destroyed during World War II.
The Zeiss planetarium in Rome, which opened in 1928, projected the stars onto the domed vault of the 3rd-century Aula Ottagona, part of the ancient Baths of Diocletian.
The first planetarium in the western hemisphere opened in Chicago in May 1930. Philanthropist Max Adler, a former executive at Sears, contributed funds to the building that now bears his name. He called it a “classroom under the heavens.”
Japan’s first planetarium, a Zeiss Model II, opened in Osaka in 1937 at the Osaka City Electricity Science Museum. As its name suggests, the museum showcased exhibits on electricity, funded by the municipal power company. The city council had to be convinced of the educational value of the planetarium. But the mayor and other enthusiasts supported it. The planetarium operated for 50 years.
Who doesn’t love a planetarium?
After World War II and the division of Germany, the Zeiss company also split in two, with operations continuing at Oberkochen in the west and Jena in the east. Both branches continued to develop the planetarium through the Zeiss Model VI before shifting the nomenclature to more exotic names, such as the Spacemaster, Skymaster, and Cosmorama.
 The two large spheres of the Zeiss Model II, introduced in 1926, displayed the skies of the northern and southern hemispheres, respectively. Each sphere contained a number of smaller projectors.ZEISS Archive
The two large spheres of the Zeiss Model II, introduced in 1926, displayed the skies of the northern and southern hemispheres, respectively. Each sphere contained a number of smaller projectors.ZEISS ArchiveOver the years, refinements included increased precision, the addition of more stars, automatic controls that allowed the programming of complete shows, and a shift to fiber optics and LED lighting. Zeiss still produces planetariums in a variety of configurations for different size domes.
Today more than 4,000 planetariums are in operation globally. A planetarium is often the first place where children connect what they see in the night sky to a broader science and an understanding of the universe. My hometown of Richmond, Va., opened its first planetarium in April 1983 at the Science Museum of Virginia. That was a bit late in the big scheme of things, but just in time to wow me as a kid. I still remember the first show I saw, narrated by an animatronic Mark Twain with a focus on the 1986 visit of Halley’s Comet.
By then the museum also had a giant OmniMax screen that let me soar over the Grand Canyon, watch beavers transform the landscape, and swim with whale sharks, all from the comfort of my reclining seat. No wonder the museum is where I got my start as a public historian of science and technology. I began volunteering there at age 14 and have never looked back.
Part of a continuing series looking at historical artifacts that embrace the boundless potential of technology.
An abridged version of this article appears in the May 2024 print issue as “A Planetarium Is Born.”
References
In 2023, the Deutsches Museum celebrated the centennial of its planetarium, with the exhibition 100 Years of the Planetarium, which included artifacts such as astrolabes and armillary spheres as well as a star show in a specially built planetarium dome.
I am always appreciative of corporations that recognize their own history and maintain robust archives. Zeiss has a wonderful collection of historic photos online with detailed descriptions.
I also consulted The Zeiss Works and the Carl Zeiss Foundation in Jena by Felix Auerbach, although I read an English translation that was in the Robert B. Ariail Collection of Historical Astronomy, part of the University of South Carolina’s special collections.
-
Modeling Cable Design & Power Electronics
by COMSOL on 01. May 2024. at 13:03

The shift toward the electrification of vehicles and the expansion of the electrical grid for renewable energy integration has led to a considerable increase in the demand for power electronics devices and modernized cable systems — applications that will help ensure a consistent and long-term electricity supply. Simulation is used to drive the design of new power electronics devices (such as solar power and wind turbine systems), which are required to operate efficiently for varying levels of power production and power consumption (in the case of electric vehicles). A multiphysics modeling and simulation approach plays a critical role in meeting design goals and reducing the overall production time.
The COMSOL Multiphysics® software offers a wide range of capabilities for the modeling of energy transmission and power electronics, including quasistatic and time-harmonic electromagnetic fields. Additionally, the COMSOL® software features unique capabilities for coupling thermal and structural effects with electromagnetic fields. Effects such as induction heating and Joule heating, as well as structural stresses and strains caused by thermal expansion, can be studied with user-friendly modeling features.
In this webinar, we will provide an overview of the modeling and simulation functionality in the COMSOL® software for the design of high-power cables and devices for power electronics.
-
This Startup Uses the MIT App Inventor to Teach Girls Coding
by Joanna Goodrich on 30. April 2024. at 18:00

When Marianne Smith was teaching computer science in 2016 at Flathead Valley Community College, in Kalispell, Mont., the adjunct professor noticed the female students in her class were severely outnumbered, she says.
Smith says she believed the disparity was because girls were not being introduced to science, technology, engineering, and mathematics in elementary and middle school.
Code Girls United
Founded
2018
Headquarters
Kalispell, Mont.
Employees
10
In 2017 she decided to do something to close the gap. The IEEE member started an after-school program to teach coding and computer science.
What began as a class of 28 students held in a local restaurant is now a statewide program run by Code Girls United, a nonprofit Smith founded in 2018. The organization has taught more than 1,000 elementary, middle, and high school students across 38 cities in Montana and three of the state’s Native American reservations. Smith has plans to expand the nonprofit to South Dakota, Wisconsin, and other states, as well as other reservations.
“Computer science is not a K–12 requirement in Montana,” Smith says. “Our program creates this rare hands-on experience that provides students with an experience that’s very empowering for girls in our community.”
The nonprofit was one of seven winners last year of MIT Solve’s Gender Equity in STEM Challenge. The initiative supports organizations that work to address gender barriers. Code Girls United received US $100,000 to use toward its program.
“The MIT Solve Gender Equity in STEM Challenge thoroughly vets all applicants—their theories, practices, organizational health, and impact,” Smith says. “For Code Girls United to be chosen as a winner of the contest is a validating honor.”
From a restaurant basement to statewide programs
When Smith had taught her sons how to program robots, she found that programming introduced a set of logic and communication skills similar to learning a new language, she says.
Those skills were what many girls were missing, she reasoned.
“It’s critical that girls be given the opportunity to speak and write in this coding language,” she says, “so they could also have the chance to communicate their ideas.”
An app to track police vehicles
Last year Code Girls United’s advanced class held in Kalispell received a special request from Jordan Venezio, the city’s police chief. He asked the class to create an app to help the Police Department manage its vehicle fleet.
The department was tracking the location of its police cars on paper, a process that made it challenging to get up-to-date information about which cars were on patrol, available for use, or being repaired, Venezio told the Flathead Beacon.
The objective was to streamline day-to-day vehicle operations. To learn how the department operates and see firsthand the difficulties administrators faced when managing the vehicles, two students shadowed officers for 10 weeks.
The students programmed the app using Visual Studio Code, React Native, Expo Go, and GitHub.
The department’s administrators now more easily can see each vehicle’s availability, whether it’s at the repair shop, or if it has been retired from duty.
“It’s a great privilege for the girls to be able to apply the skills they’ve learned in the Code Girls United program to do something like this for the community,” Smith says. “It really brings our vision full circle.”
At first she wasn’t sure what subjects to teach, she says, reasoning that Java and other programming languages were too advanced for elementary school students.
She came across MIT App Inventor, a block-based visual programming language for creating mobile apps for Android and iOS devices. Instead of learning a coding language by typing it, students drag and drop jigsaw puzzle–like pieces that contain code to issue instructions. She incorporated building an app with general computer science concepts such as conditionals, logic flow, and variables. With each concept learned, the students built a more difficult app.
“It was perfect,” she says, “because the girls could make an app and test it the same day. It’s also very visual.”
Once she had a curriculum, she wanted to find willing students, so she placed an advertisement in the local newspaper. Twenty-eight girls signed up for the weekly classes, which were held in a diner. Assisting Smith were Beth Schecher, a retired technical professional; and Liz Bernau, a newly graduated elementary school teacher who taught technology classes. Students had to supply their own laptop.
At the end of the first 18 weeks, the class was tasked with creating apps to enter in the annual Technovation Girls competition. The contest seeks out apps that address issues including animal abandonment, safely reporting domestic violence, and access to mental health services.
The first group of students created several apps to enter in the competition, including ones that connected users to water-filling stations, provided people with information about food banks, and allowed users to report potholes. The group made it to the competition’s semifinals.
The coding program soon outgrew the diner and moved to a computer lab in a nearby elementary school. From there classes were held at Flathead Valley Community College. The program continued to grow and soon expanded to schools in other Montana towns including Belgrade, Havre, Joliet, and Polson.
The COVID-19 pandemic prompted the program to become virtual—which was “oddly fortuitous,” Smith says. After she made the curriculum available for anyone to use via Google Classroom, it increased in popularity.
That’s when she decided to launch her nonprofit. With that came a new curriculum.
 What began as a class of 28 students held in a restaurant in Kalispell, Mont., has grown into a statewide program run by Code Girls United. The nonprofit has taught coding and computer science to more than 1,000 elementary, middle, and high school students. Code Girls United
What began as a class of 28 students held in a restaurant in Kalispell, Mont., has grown into a statewide program run by Code Girls United. The nonprofit has taught coding and computer science to more than 1,000 elementary, middle, and high school students. Code Girls UnitedProgram expands across the state
Beginner, intermediate, and advanced classes were introduced. Instructors of the weekly after-school program are volunteers and teachers trained by Smith or one of the organization’s 10 employees. The teachers are paid a stipend.
For the first half of the school year, students in the beginner class learn computer science while creating apps.
“By having them design and build a mobile app,” Smith says, “I and the other teachers teach them computer science concepts in a fun and interactive way.”
Once students master the course, they move on to the intermediate and advanced levels, where they are taught lessons in computer science and learn more complicated programming concepts such as Java and Python.
“It’s important to give girls who live on the reservations educational opportunities to close the gap. It’s the right thing to do for the next generation.”
During the second half of the year, the intermediate and advanced classes participate in Code Girls United’s App Challenge. The girls form teams and choose a problem in their community to tackle. Next they write a business plan that includes devising a marketing strategy, designing a logo, and preparing a presentation. A panel of volunteer judges evaluates their work, and the top six teams receive a scholarship of up to $5,000, which is split among the members.
The organization has given out more than 55 scholarships, Smith says.
“Some of the girls who participated in our first education program are now going to college,” she says. “Seventy-two percent of participants are pursuing a degree in a STEM field, and quite a few are pursuing computer science.”
Introducing coding to Native Americans
The program is taught to high school girls on Montana’s Native American reservations through workshops.
Many reservations lack access to technology resources, Smith says, so presenting the program there has been challenging. But the organization has had some success and is working with the Blackfeet reservation, the Salish and Kootenai tribes on the Flathead reservation, and the Nakota and Gros Ventre tribes at Fort Belknap.
The workshops tailor technology for Native American culture. In the newest course, students program a string of LEDs to respond to the drumbeat of tribal songs using the BBC’s Micro:bit programmable controller. The lights are attached to the bottom of a ribbon skirt, a traditional garment worn by young women. Colorful ribbons are sewn horizontally across the bottom, with each hue having a meaning.
The new course was introduced to students on the Flathead reservation this month.
“Montana’s reservations are some of the most remote and resource-limited communities,” Smith says, “especially in regards to technology and educational opportunities.
“It’s important to give girls who live on the reservations educational opportunities to close the gap. It’s the right thing to do for the next generation.”
-
How Field AI Is Conquering Unstructured Autonomy
by Evan Ackerman on 30. April 2024. at 14:00

One of the biggest challenges for robotics right now is practical autonomous operation in unstructured environments. That is, doing useful stuff in places your robot hasn’t been before and where things may not be as familiar as your robot might like. Robots thrive on predictability, which has put some irksome restrictions on where and how they can be successfully deployed.
But over the past few years, this has started to change, thanks in large part to a couple of pivotal robotics challenges put on by DARPA. The DARPA Subterranean Challenge ran from 2018 to 2021, putting mobile robots through a series of unstructured underground environments. And the currently ongoing DARPA RACER program tasks autonomous vehicles with navigating long distances off-road. Some extremely impressive technology has been developed through these programs, but there’s always a gap between this cutting-edge research and any real-world applications.
Now, a bunch of the folks involved in these challenges, including experienced roboticists from NASA, DARPA, Google DeepMind, Amazon, and Cruise (to name just a few places) are applying everything that they’ve learned to enable real-world practical autonomy for mobile robots at a startup called Field AI.
Field AI was cofounded by Ali Agha, who previously was a group leader for NASA JPL’s Aerial Mobility Group as well as JPL’s Perception Systems Group. While at JPL, Agha led Team CoSTAR, which won the DARPA Subterranean Challenge Urban Circuit. Agha has also been the principal investigator for DARPA RACER, first with JPL, and now continuing with Field AI. “Field AI is not just a startup,” Agha tells us. “It’s a culmination of decades of experience in AI and its deployment in the field.”
Unstructured environments are where things are constantly changing, which can play havoc with robots that rely on static maps.
The “field” part in Field AI is what makes Agha’s startup unique. Robots running Field AI’s software are able to handle unstructured, unmapped environments without reliance on prior models, GPS, or human intervention. Obviously, this kind of capability was (and is) of interest to NASA and JPL, which send robots to places where there are no maps, GPS doesn’t exist, and direct human intervention is impossible.
But DARPA SubT demonstrated that similar environments can be found on Earth, too. For instance, mines, natural caves, and the urban underground are all extremely challenging for robots (and even for humans) to navigate. And those are just the most extreme examples: robots that need to operate inside buildings or out in the wilderness have similar challenges understanding where they are, where they’re going, and how to navigate the environment around them.
 An autonomous vehicle drives across kilometers of desert with no prior map, no GPS, and no road.Field AI
An autonomous vehicle drives across kilometers of desert with no prior map, no GPS, and no road.Field AIDespite the difficulty that robots have operating in the field, this is an enormous opportunity that Field AI hopes to address. Robots have already proven their worth in inspection contexts, typically where you either need to make sure that nothing is going wrong across a large industrial site, or for tracking construction progress inside a partially completed building. There’s a lot of value here because the consequences of something getting messed up are expensive or dangerous or both, but the tasks are repetitive and sometimes risky and generally don’t require all that much human insight or creativity.
Uncharted Territory as Home Base
Where Field AI differs from other robotics companies offering these services, as Agha explains, is that his company wants to do these tasks without first having a map that tells the robot where to go. In other words, there’s no lengthy setup process, and no human supervision, and the robot can adapt to changing and new environments. Really, this is what full autonomy is all about: going anywhere, anytime, without human interaction. “Our customers don’t need to train anything,” Agha says, laying out the company’s vision. “They don’t need to have precise maps. They press a single button, and the robot just discovers every corner of the environment.” This capability is where the DARPA SubT heritage comes in. During the competition, DARPA basically said, “here’s the door into the course. We’re not going to tell you anything about what’s back there or even how big it is. Just go explore the whole thing and bring us back the info we’ve asked for.” Agha’s Team CoSTAR did exactly that during the competition, and Field AI is commercializing this capability.
“With our robots, our aim is for you to just deploy it, with no training time needed. And then we can just leave the robots.” —Ali Agha, Field AI
The other tricky thing about these unstructured environments, especially construction environments, is that things are constantly changing, which can play havoc with robots that rely on static maps. “We’re one of the few, if not the only company that can leave robots for days on continuously changing construction sites with minimal supervision,” Agha tells us. “These sites are very complex—every day there are new items, new challenges, and unexpected events. Construction materials on the ground, scaffolds, forklifts, and heavy machinery moving all over the place, nothing you can predict.”
 Field AI
Field AIField AI’s approach to this problem is to emphasize environmental understanding over mapping. Agha says that essentially, Field AI is working towards creating “field foundation models” (FFMs) of the physical world, using sensor data as an input. You can think of FFMs as being similar to the foundation models of language, music, and art that other AI companies have created over the past several years, where ingesting a large amount of data from the Internet enables some level of functionality in a domain without requiring specific training for each new situation. Consequently, Field AI’s robots can understand how to move in the world, rather than just where to move. “We look at AI quite differently from what’s mainstream,” Agha explains. “We do very heavy probabilistic modeling.” Much more technical detail would get into Field AI’s IP, says Agha, but the point is that real-time world modeling becomes a by-product of Field AI’s robots operating in the world rather than a prerequisite for that operation. This makes the robots fast, efficient, and resilient.
Developing field-foundation models that robots can use to reliably go almost anywhere requires a lot of real-world data, which Field AI has been collecting at industrial and construction sites around the world for the past year. To be clear, they’re collecting the data as part of their commercial operations—these are paying customers that Field AI has already. “In these job sites, it can traditionally take weeks to go around a site and map where every single target of interest that you need to inspect is,” explains Agha. “But with our robots, our aim is for you to just deploy it, with no training time needed. And then we can just leave the robots. This level of autonomy really unlocks a lot of use cases that our customers weren’t even considering, because they thought it was years away.” And the use cases aren’t just about construction or inspection or other areas where we’re already seeing autonomous robotic systems, Agha says. “These technologies hold immense potential.”
There’s obviously demand for this level of autonomy, but Agha says that the other piece of the puzzle that will enable Field AI to leverage a trillion dollar market is the fact that they can do what they do with virtually any platform. Fundamentally, Field AI is a software company—they make sensor payloads that integrate with their autonomy software, but even those payloads are adjustable, ranging from something appropriate for an autonomous vehicle to something that a drone can handle.
Heck, if you decide that you need an autonomous humanoid for some weird reason, Field AI can do that too. While the versatility here is important, according to Agha, what’s even more important is that it means you can focus on platforms that are more affordable, and still expect the same level of autonomous performance, within the constraints of each robot’s design, of course. With control over the full software stack, integrating mobility with high-level planning, decision making, and mission execution, Agha says that the potential to take advantage of relatively inexpensive robots is what’s going to make the biggest difference toward Field AI’s commercial success.
 Same brain, lots of different robots: the Field AI team’s foundation models can be used on robots big, small, expensive, and somewhat less expensive.Field AI
Same brain, lots of different robots: the Field AI team’s foundation models can be used on robots big, small, expensive, and somewhat less expensive.Field AIField AI is already expanding its capabilities, building on some of its recent experience with DARPA RACER by working on deploying robots to inspect pipelines for tens of kilometers and to transport materials across solar farms. With revenue coming in and a substantial chunk of funding, Field AI has even attracted interest from Bill Gates. Field AI’s participation in RACER is ongoing, under a sort of subsidiary company for federal projects called Offroad Autonomy, and in the meantime its commercial side is targeting expansion to “hundreds” of sites on every platform it can think of, including humanoids.
-
Expect a Wave of Wafer-Scale Computers
by Samuel K. Moore on 30. April 2024. at 13:00

At TSMC’s North American Technology Symposium on Wednesday, the company detailed both its semiconductor technology and chip-packaging technology road maps. While the former is key to keeping the traditional part of Moore’s Law going, the latter could accelerate a trend toward processors made from more and more silicon, leading quickly to systems the size of a full silicon wafer. Such a system, Tesla’s next generation Dojo training tile is already in production, TSMC says. And in 2027 the foundry plans to offer technology for more complex wafer-scale systems than Tesla’s that could deliver 40 times as much computing power as today’s systems.
For decades chipmakers increased the density of logic on processors largely by scaling down the area that transistors take up and the size of interconnects. But that scheme has been running out of steam for a while now. Instead, the industry is turning to advanced packaging technology that allows a single processor to be made from a larger amount of silicon. The size of a single chip is hemmed in by the largest pattern that lithography equipment can make. Called the reticle limit, that’s currently about 800 square millimeters. So if you want more silicon in your GPU you need to make it from two or more dies. The key is connecting those dies so that signals can go from one to the other as quickly and with as little energy as if they were all one big piece of silicon.
TSMC already makes a wafer-size AI accelerator for Cerebras, but that arrangement appears to be unique and is different from what TSMC is now offering with what it calls System-on-Wafer.
In 2027, you will get a full-wafer integration that delivers 40 times as much compute power, more than 40 reticles’ worth of silicon, and room for more than 60 high-bandwidth memory chips, TSMC predicts
For Cerebras, TSMC makes a wafer full of identical arrays of AI cores that are smaller than the reticle limit. It connects these arrays across the “scribe lines,” the areas between dies that are usually left blank, so the wafer can be diced up into chips. No chipmaking process is perfect, so there are always flawed parts on every wafer. But Cerebras designed in enough redundancy that it doesn’t matter to the finished computer.
However, with its first round of System-on-Wafer, TSMC is offering a different solution to the problems of both reticle limit and yield. It starts with already tested logic dies to minimize defects. (Tesla’s Dojo contains a 5-by-5 grid of pretested processors.) These are placed on a carrier wafer, and the blank spots between the dies are filled in. Then a layer of high-density interconnects is constructed to connect the logic using TSMC’s integrated fan-out technology. The aim is to make data bandwidth among the dies so high that they effectively act like a single large chip.
By 2027, TSMC plans to offer wafer-scale integration based on its more advanced packaging technology, chip-on-wafer-on-substrate (CoWoS). In that technology, pretested logic and, importantly, high-bandwidth memory, is attached to a silicon substrate that’s been patterned with high-density interconnects and shot through with vertical connections called through-silicon vias. The attached logic chips can also take advantage of the company’s 3D-chip technology called system-on-integrated chips (SoIC).
The wafer-scale version of CoWoS is the logical endpoint of an expansion of the packaging technology that’s already visible in top-end GPUs. Nvidia’s next GPU, Blackwell, uses CoWos to integrate more than 3 reticle sizes’ worth of silicon, including 8 high-bandwidth memory (HBM) chips. By 2026, the company plans to expand that to 5.5 reticles, including 12 HBMs. TSMC says that would translate to more than 3.5 times as much compute power as its 2023 tech allows. But in 2027, you can get a full wafer integration that delivers 40 times as much compute, more than 40 reticles’ worth of silicon and room for more than 60 HBMs, TSMC predicts.
What Wafer Scale Is Good For
The 2027 version of system-on-wafer somewhat resembles technology called Silicon-Interconnect Fabric, or Si-IF, developed at UCLA more than five years ago. The team behind SiIF includes electrical and computer-engineering professor Puneet Gupta and IEEE Fellow Subramanian Iyer, who is now charged with implementing the packaging portion of the United States’ CHIPS Act.
Since then, they’ve been working to make the interconnects on the wafer more dense and to add other features to the technology. “If you want this as a full technology infrastructure, it needs to do many other things beyond just providing fine-pitch connectivity,” says Gupta, also an IEEE Fellow. “One of the biggest pain points for these large systems is going to be delivering power.” So the UCLA team is working on ways to add good-quality capacitors and inductors to the silicon substrate and integrating gallium nitride power transistors.
AI training is the obvious first application for wafer-scale technology, but it is not the only one, and it may not even be the best, says University of Illinois Urbana-Champaign computer architect and IEEE Fellow Rakesh Kumar. At the International Symposium on Computer Architecture in June, his team is presenting a design for a wafer-scale network switch for data centers. Such a system could cut the number of advanced network switches in a very large—16,000-rack—data center from 4,608 to just 48, the researchers report. A much smaller, enterprise-scale, data center for say 8,000 servers could get by using a single wafer-scale switch.
-
Andrew Ng: Unbiggen AI
by Eliza Strickland on 09. February 2022. at 15:31

Andrew Ng has serious street cred in artificial intelligence. He pioneered the use of graphics processing units (GPUs) to train deep learning models in the late 2000s with his students at Stanford University, cofounded Google Brain in 2011, and then served for three years as chief scientist for Baidu, where he helped build the Chinese tech giant’s AI group. So when he says he has identified the next big shift in artificial intelligence, people listen. And that’s what he told IEEE Spectrum in an exclusive Q&A.
Ng’s current efforts are focused on his company Landing AI, which built a platform called LandingLens to help manufacturers improve visual inspection with computer vision. He has also become something of an evangelist for what he calls the data-centric AI movement, which he says can yield “small data” solutions to big issues in AI, including model efficiency, accuracy, and bias.
Andrew Ng on...
- What’s next for really big models
- The career advice he didn’t listen to
- Defining the data-centric AI movement
- Synthetic data
- Why Landing AI asks its customers to do the work
The great advances in deep learning over the past decade or so have been powered by ever-bigger models crunching ever-bigger amounts of data. Some people argue that that’s an unsustainable trajectory. Do you agree that it can’t go on that way?
Andrew Ng: This is a big question. We’ve seen foundation models in NLP [natural language processing]. I’m excited about NLP models getting even bigger, and also about the potential of building foundation models in computer vision. I think there’s lots of signal to still be exploited in video: We have not been able to build foundation models yet for video because of compute bandwidth and the cost of processing video, as opposed to tokenized text. So I think that this engine of scaling up deep learning algorithms, which has been running for something like 15 years now, still has steam in it. Having said that, it only applies to certain problems, and there’s a set of other problems that need small data solutions.
When you say you want a foundation model for computer vision, what do you mean by that?
Ng: This is a term coined by Percy Liang and some of my friends at Stanford to refer to very large models, trained on very large data sets, that can be tuned for specific applications. For example, GPT-3 is an example of a foundation model [for NLP]. Foundation models offer a lot of promise as a new paradigm in developing machine learning applications, but also challenges in terms of making sure that they’re reasonably fair and free from bias, especially if many of us will be building on top of them.
What needs to happen for someone to build a foundation model for video?
Ng: I think there is a scalability problem. The compute power needed to process the large volume of images for video is significant, and I think that’s why foundation models have arisen first in NLP. Many researchers are working on this, and I think we’re seeing early signs of such models being developed in computer vision. But I’m confident that if a semiconductor maker gave us 10 times more processor power, we could easily find 10 times more video to build such models for vision.
Having said that, a lot of what’s happened over the past decade is that deep learning has happened in consumer-facing companies that have large user bases, sometimes billions of users, and therefore very large data sets. While that paradigm of machine learning has driven a lot of economic value in consumer software, I find that that recipe of scale doesn’t work for other industries.
It’s funny to hear you say that, because your early work was at a consumer-facing company with millions of users.
Ng: Over a decade ago, when I proposed starting the Google Brain project to use Google’s compute infrastructure to build very large neural networks, it was a controversial step. One very senior person pulled me aside and warned me that starting Google Brain would be bad for my career. I think he felt that the action couldn’t just be in scaling up, and that I should instead focus on architecture innovation.
“In many industries where giant data sets simply don’t exist, I think the focus has to shift from big data to good data. Having 50 thoughtfully engineered examples can be sufficient to explain to the neural network what you want it to learn.”
—Andrew Ng, CEO & Founder, Landing AII remember when my students and I published the first NeurIPS workshop paper advocating using CUDA, a platform for processing on GPUs, for deep learning—a different senior person in AI sat me down and said, “CUDA is really complicated to program. As a programming paradigm, this seems like too much work.” I did manage to convince him; the other person I did not convince.
I expect they’re both convinced now.
Ng: I think so, yes.
Over the past year as I’ve been speaking to people about the data-centric AI movement, I’ve been getting flashbacks to when I was speaking to people about deep learning and scalability 10 or 15 years ago. In the past year, I’ve been getting the same mix of “there’s nothing new here” and “this seems like the wrong direction.”
How do you define data-centric AI, and why do you consider it a movement?
Ng: Data-centric AI is the discipline of systematically engineering the data needed to successfully build an AI system. For an AI system, you have to implement some algorithm, say a neural network, in code and then train it on your data set. The dominant paradigm over the last decade was to download the data set while you focus on improving the code. Thanks to that paradigm, over the last decade deep learning networks have improved significantly, to the point where for a lot of applications the code—the neural network architecture—is basically a solved problem. So for many practical applications, it’s now more productive to hold the neural network architecture fixed, and instead find ways to improve the data.
When I started speaking about this, there were many practitioners who, completely appropriately, raised their hands and said, “Yes, we’ve been doing this for 20 years.” This is the time to take the things that some individuals have been doing intuitively and make it a systematic engineering discipline.
The data-centric AI movement is much bigger than one company or group of researchers. My collaborators and I organized a data-centric AI workshop at NeurIPS, and I was really delighted at the number of authors and presenters that showed up.
You often talk about companies or institutions that have only a small amount of data to work with. How can data-centric AI help them?
Ng: You hear a lot about vision systems built with millions of images—I once built a face recognition system using 350 million images. Architectures built for hundreds of millions of images don’t work with only 50 images. But it turns out, if you have 50 really good examples, you can build something valuable, like a defect-inspection system. In many industries where giant data sets simply don’t exist, I think the focus has to shift from big data to good data. Having 50 thoughtfully engineered examples can be sufficient to explain to the neural network what you want it to learn.
When you talk about training a model with just 50 images, does that really mean you’re taking an existing model that was trained on a very large data set and fine-tuning it? Or do you mean a brand new model that’s designed to learn only from that small data set?
Ng: Let me describe what Landing AI does. When doing visual inspection for manufacturers, we often use our own flavor of RetinaNet. It is a pretrained model. Having said that, the pretraining is a small piece of the puzzle. What’s a bigger piece of the puzzle is providing tools that enable the manufacturer to pick the right set of images [to use for fine-tuning] and label them in a consistent way. There’s a very practical problem we’ve seen spanning vision, NLP, and speech, where even human annotators don’t agree on the appropriate label. For big data applications, the common response has been: If the data is noisy, let’s just get a lot of data and the algorithm will average over it. But if you can develop tools that flag where the data’s inconsistent and give you a very targeted way to improve the consistency of the data, that turns out to be a more efficient way to get a high-performing system.
“Collecting more data often helps, but if you try to collect more data for everything, that can be a very expensive activity.”
—Andrew NgFor example, if you have 10,000 images where 30 images are of one class, and those 30 images are labeled inconsistently, one of the things we do is build tools to draw your attention to the subset of data that’s inconsistent. So you can very quickly relabel those images to be more consistent, and this leads to improvement in performance.
Could this focus on high-quality data help with bias in data sets? If you’re able to curate the data more before training?
Ng: Very much so. Many researchers have pointed out that biased data is one factor among many leading to biased systems. There have been many thoughtful efforts to engineer the data. At the NeurIPS workshop, Olga Russakovsky gave a really nice talk on this. At the main NeurIPS conference, I also really enjoyed Mary Gray’s presentation, which touched on how data-centric AI is one piece of the solution, but not the entire solution. New tools like Datasheets for Datasets also seem like an important piece of the puzzle.
One of the powerful tools that data-centric AI gives us is the ability to engineer a subset of the data. Imagine training a machine-learning system and finding that its performance is okay for most of the data set, but its performance is biased for just a subset of the data. If you try to change the whole neural network architecture to improve the performance on just that subset, it’s quite difficult. But if you can engineer a subset of the data you can address the problem in a much more targeted way.
When you talk about engineering the data, what do you mean exactly?
Ng: In AI, data cleaning is important, but the way the data has been cleaned has often been in very manual ways. In computer vision, someone may visualize images through a Jupyter notebook and maybe spot the problem, and maybe fix it. But I’m excited about tools that allow you to have a very large data set, tools that draw your attention quickly and efficiently to the subset of data where, say, the labels are noisy. Or to quickly bring your attention to the one class among 100 classes where it would benefit you to collect more data. Collecting more data often helps, but if you try to collect more data for everything, that can be a very expensive activity.
For example, I once figured out that a speech-recognition system was performing poorly when there was car noise in the background. Knowing that allowed me to collect more data with car noise in the background, rather than trying to collect more data for everything, which would have been expensive and slow.
What about using synthetic data, is that often a good solution?
Ng: I think synthetic data is an important tool in the tool chest of data-centric AI. At the NeurIPS workshop, Anima Anandkumar gave a great talk that touched on synthetic data. I think there are important uses of synthetic data that go beyond just being a preprocessing step for increasing the data set for a learning algorithm. I’d love to see more tools to let developers use synthetic data generation as part of the closed loop of iterative machine learning development.
Do you mean that synthetic data would allow you to try the model on more data sets?
Ng: Not really. Here’s an example. Let’s say you’re trying to detect defects in a smartphone casing. There are many different types of defects on smartphones. It could be a scratch, a dent, pit marks, discoloration of the material, other types of blemishes. If you train the model and then find through error analysis that it’s doing well overall but it’s performing poorly on pit marks, then synthetic data generation allows you to address the problem in a more targeted way. You could generate more data just for the pit-mark category.
“In the consumer software Internet, we could train a handful of machine-learning models to serve a billion users. In manufacturing, you might have 10,000 manufacturers building 10,000 custom AI models.”
—Andrew NgSynthetic data generation is a very powerful tool, but there are many simpler tools that I will often try first. Such as data augmentation, improving labeling consistency, or just asking a factory to collect more data.
To make these issues more concrete, can you walk me through an example? When a company approaches Landing AI and says it has a problem with visual inspection, how do you onboard them and work toward deployment?
Ng: When a customer approaches us we usually have a conversation about their inspection problem and look at a few images to verify that the problem is feasible with computer vision. Assuming it is, we ask them to upload the data to the LandingLens platform. We often advise them on the methodology of data-centric AI and help them label the data.
One of the foci of Landing AI is to empower manufacturing companies to do the machine learning work themselves. A lot of our work is making sure the software is fast and easy to use. Through the iterative process of machine learning development, we advise customers on things like how to train models on the platform, when and how to improve the labeling of data so the performance of the model improves. Our training and software supports them all the way through deploying the trained model to an edge device in the factory.
How do you deal with changing needs? If products change or lighting conditions change in the factory, can the model keep up?
Ng: It varies by manufacturer. There is data drift in many contexts. But there are some manufacturers that have been running the same manufacturing line for 20 years now with few changes, so they don’t expect changes in the next five years. Those stable environments make things easier. For other manufacturers, we provide tools to flag when there’s a significant data-drift issue. I find it really important to empower manufacturing customers to correct data, retrain, and update the model. Because if something changes and it’s 3 a.m. in the United States, I want them to be able to adapt their learning algorithm right away to maintain operations.
In the consumer software Internet, we could train a handful of machine-learning models to serve a billion users. In manufacturing, you might have 10,000 manufacturers building 10,000 custom AI models. The challenge is, how do you do that without Landing AI having to hire 10,000 machine learning specialists?
So you’re saying that to make it scale, you have to empower customers to do a lot of the training and other work.
Ng: Yes, exactly! This is an industry-wide problem in AI, not just in manufacturing. Look at health care. Every hospital has its own slightly different format for electronic health records. How can every hospital train its own custom AI model? Expecting every hospital’s IT personnel to invent new neural-network architectures is unrealistic. The only way out of this dilemma is to build tools that empower the customers to build their own models by giving them tools to engineer the data and express their domain knowledge. That’s what Landing AI is executing in computer vision, and the field of AI needs other teams to execute this in other domains.
Is there anything else you think it’s important for people to understand about the work you’re doing or the data-centric AI movement?
Ng: In the last decade, the biggest shift in AI was a shift to deep learning. I think it’s quite possible that in this decade the biggest shift will be to data-centric AI. With the maturity of today’s neural network architectures, I think for a lot of the practical applications the bottleneck will be whether we can efficiently get the data we need to develop systems that work well. The data-centric AI movement has tremendous energy and momentum across the whole community. I hope more researchers and developers will jump in and work on it.
This article appears in the April 2022 print issue as “Andrew Ng, AI Minimalist.”
-
How AI Will Change Chip Design
by Rina Diane Caballar on 08. February 2022. at 14:00

The end of Moore’s Law is looming. Engineers and designers can do only so much to miniaturize transistors and pack as many of them as possible into chips. So they’re turning to other approaches to chip design, incorporating technologies like AI into the process.
Samsung, for instance, is adding AI to its memory chips to enable processing in memory, thereby saving energy and speeding up machine learning. Speaking of speed, Google’s TPU V4 AI chip has doubled its processing power compared with that of its previous version.
But AI holds still more promise and potential for the semiconductor industry. To better understand how AI is set to revolutionize chip design, we spoke with Heather Gorr, senior product manager for MathWorks’ MATLAB platform.
How is AI currently being used to design the next generation of chips?
Heather Gorr: AI is such an important technology because it’s involved in most parts of the cycle, including the design and manufacturing process. There’s a lot of important applications here, even in the general process engineering where we want to optimize things. I think defect detection is a big one at all phases of the process, especially in manufacturing. But even thinking ahead in the design process, [AI now plays a significant role] when you’re designing the light and the sensors and all the different components. There’s a lot of anomaly detection and fault mitigation that you really want to consider.
 Heather GorrMathWorks
Heather GorrMathWorksThen, thinking about the logistical modeling that you see in any industry, there is always planned downtime that you want to mitigate; but you also end up having unplanned downtime. So, looking back at that historical data of when you’ve had those moments where maybe it took a bit longer than expected to manufacture something, you can take a look at all of that data and use AI to try to identify the proximate cause or to see something that might jump out even in the processing and design phases. We think of AI oftentimes as a predictive tool, or as a robot doing something, but a lot of times you get a lot of insight from the data through AI.
What are the benefits of using AI for chip design?
Gorr: Historically, we’ve seen a lot of physics-based modeling, which is a very intensive process. We want to do a reduced order model, where instead of solving such a computationally expensive and extensive model, we can do something a little cheaper. You could create a surrogate model, so to speak, of that physics-based model, use the data, and then do your parameter sweeps, your optimizations, your Monte Carlo simulations using the surrogate model. That takes a lot less time computationally than solving the physics-based equations directly. So, we’re seeing that benefit in many ways, including the efficiency and economy that are the results of iterating quickly on the experiments and the simulations that will really help in the design.
So it’s like having a digital twin in a sense?
Gorr: Exactly. That’s pretty much what people are doing, where you have the physical system model and the experimental data. Then, in conjunction, you have this other model that you could tweak and tune and try different parameters and experiments that let sweep through all of those different situations and come up with a better design in the end.
So, it’s going to be more efficient and, as you said, cheaper?
Gorr: Yeah, definitely. Especially in the experimentation and design phases, where you’re trying different things. That’s obviously going to yield dramatic cost savings if you’re actually manufacturing and producing [the chips]. You want to simulate, test, experiment as much as possible without making something using the actual process engineering.
We’ve talked about the benefits. How about the drawbacks?
Gorr: The [AI-based experimental models] tend to not be as accurate as physics-based models. Of course, that’s why you do many simulations and parameter sweeps. But that’s also the benefit of having that digital twin, where you can keep that in mind—it’s not going to be as accurate as that precise model that we’ve developed over the years.
Both chip design and manufacturing are system intensive; you have to consider every little part. And that can be really challenging. It’s a case where you might have models to predict something and different parts of it, but you still need to bring it all together.
One of the other things to think about too is that you need the data to build the models. You have to incorporate data from all sorts of different sensors and different sorts of teams, and so that heightens the challenge.
How can engineers use AI to better prepare and extract insights from hardware or sensor data?
Gorr: We always think about using AI to predict something or do some robot task, but you can use AI to come up with patterns and pick out things you might not have noticed before on your own. People will use AI when they have high-frequency data coming from many different sensors, and a lot of times it’s useful to explore the frequency domain and things like data synchronization or resampling. Those can be really challenging if you’re not sure where to start.
One of the things I would say is, use the tools that are available. There’s a vast community of people working on these things, and you can find lots of examples [of applications and techniques] on GitHub or MATLAB Central, where people have shared nice examples, even little apps they’ve created. I think many of us are buried in data and just not sure what to do with it, so definitely take advantage of what’s already out there in the community. You can explore and see what makes sense to you, and bring in that balance of domain knowledge and the insight you get from the tools and AI.
What should engineers and designers consider when using AI for chip design?
Gorr: Think through what problems you’re trying to solve or what insights you might hope to find, and try to be clear about that. Consider all of the different components, and document and test each of those different parts. Consider all of the people involved, and explain and hand off in a way that is sensible for the whole team.
How do you think AI will affect chip designers’ jobs?
Gorr: It’s going to free up a lot of human capital for more advanced tasks. We can use AI to reduce waste, to optimize the materials, to optimize the design, but then you still have that human involved whenever it comes to decision-making. I think it’s a great example of people and technology working hand in hand. It’s also an industry where all people involved—even on the manufacturing floor—need to have some level of understanding of what’s happening, so this is a great industry for advancing AI because of how we test things and how we think about them before we put them on the chip.
How do you envision the future of AI and chip design?
Gorr: It’s very much dependent on that human element—involving people in the process and having that interpretable model. We can do many things with the mathematical minutiae of modeling, but it comes down to how people are using it, how everybody in the process is understanding and applying it. Communication and involvement of people of all skill levels in the process are going to be really important. We’re going to see less of those superprecise predictions and more transparency of information, sharing, and that digital twin—not only using AI but also using our human knowledge and all of the work that many people have done over the years.
-
Atomically Thin Materials Significantly Shrink Qubits
by Dexter Johnson on 07. February 2022. at 16:12

Quantum computing is a devilishly complex technology, with many technical hurdles impacting its development. Of these challenges two critical issues stand out: miniaturization and qubit quality.
IBM has adopted the superconducting qubit road map of reaching a 1,121-qubit processor by 2023, leading to the expectation that 1,000 qubits with today’s qubit form factor is feasible. However, current approaches will require very large chips (50 millimeters on a side, or larger) at the scale of small wafers, or the use of chiplets on multichip modules. While this approach will work, the aim is to attain a better path toward scalability.
Now researchers at MIT have been able to both reduce the size of the qubits and done so in a way that reduces the interference that occurs between neighboring qubits. The MIT researchers have increased the number of superconducting qubits that can be added onto a device by a factor of 100.
“We are addressing both qubit miniaturization and quality,” said William Oliver, the director for the Center for Quantum Engineering at MIT. “Unlike conventional transistor scaling, where only the number really matters, for qubits, large numbers are not sufficient, they must also be high-performance. Sacrificing performance for qubit number is not a useful trade in quantum computing. They must go hand in hand.”
The key to this big increase in qubit density and reduction of interference comes down to the use of two-dimensional materials, in particular the 2D insulator hexagonal boron nitride (hBN). The MIT researchers demonstrated that a few atomic monolayers of hBN can be stacked to form the insulator in the capacitors of a superconducting qubit.
Just like other capacitors, the capacitors in these superconducting circuits take the form of a sandwich in which an insulator material is sandwiched between two metal plates. The big difference for these capacitors is that the superconducting circuits can operate only at extremely low temperatures—less than 0.02 degrees above absolute zero (-273.15 °C).
 Superconducting qubits are measured at temperatures as low as 20 millikelvin in a dilution refrigerator.Nathan Fiske/MIT
Superconducting qubits are measured at temperatures as low as 20 millikelvin in a dilution refrigerator.Nathan Fiske/MITIn that environment, insulating materials that are available for the job, such as PE-CVD silicon oxide or silicon nitride, have quite a few defects that are too lossy for quantum computing applications. To get around these material shortcomings, most superconducting circuits use what are called coplanar capacitors. In these capacitors, the plates are positioned laterally to one another, rather than on top of one another.
As a result, the intrinsic silicon substrate below the plates and to a smaller degree the vacuum above the plates serve as the capacitor dielectric. Intrinsic silicon is chemically pure and therefore has few defects, and the large size dilutes the electric field at the plate interfaces, all of which leads to a low-loss capacitor. The lateral size of each plate in this open-face design ends up being quite large (typically 100 by 100 micrometers) in order to achieve the required capacitance.
In an effort to move away from the large lateral configuration, the MIT researchers embarked on a search for an insulator that has very few defects and is compatible with superconducting capacitor plates.
“We chose to study hBN because it is the most widely used insulator in 2D material research due to its cleanliness and chemical inertness,” said colead author Joel Wang, a research scientist in the Engineering Quantum Systems group of the MIT Research Laboratory for Electronics.
On either side of the hBN, the MIT researchers used the 2D superconducting material, niobium diselenide. One of the trickiest aspects of fabricating the capacitors was working with the niobium diselenide, which oxidizes in seconds when exposed to air, according to Wang. This necessitates that the assembly of the capacitor occur in a glove box filled with argon gas.
While this would seemingly complicate the scaling up of the production of these capacitors, Wang doesn’t regard this as a limiting factor.
“What determines the quality factor of the capacitor are the two interfaces between the two materials,” said Wang. “Once the sandwich is made, the two interfaces are “sealed” and we don’t see any noticeable degradation over time when exposed to the atmosphere.”
This lack of degradation is because around 90 percent of the electric field is contained within the sandwich structure, so the oxidation of the outer surface of the niobium diselenide does not play a significant role anymore. This ultimately makes the capacitor footprint much smaller, and it accounts for the reduction in cross talk between the neighboring qubits.
“The main challenge for scaling up the fabrication will be the wafer-scale growth of hBN and 2D superconductors like [niobium diselenide], and how one can do wafer-scale stacking of these films,” added Wang.
Wang believes that this research has shown 2D hBN to be a good insulator candidate for superconducting qubits. He says that the groundwork the MIT team has done will serve as a road map for using other hybrid 2D materials to build superconducting circuits.